Written by: Plan Bai Team
Blockchain is a technology that multiple parties jointly complete the recording process of the general ledger. Multiple participating computing parties connect devices into a network to form an open blockchain network, such as Bitcoin, Ethereum, Polkadot, etc. All computing participants share resources for use by developers and users.In such operating rules, data flow runs through every operating step.From the communication of the underlying nodes to block packaging, copying, confirmation, and then to the transaction transfer at the application layer. From transfer transactions in the network to the balance of each node, account data and data on-chain.As such, the paradigm of blockchain for data processing is the biggest advantage over data processing in traditional databases.Here, it has to be said that in the long Internet cycle, data has been recognized by enterprises as its core value, and at the same time, a large number of data processing and management problems need to be solved urgently. Fortunately, many blockchain projects are developing Try to use blockchain technology and combine it with other technologies to form a blockchain-based data solution.For example, multiple structural designs and various calculation forms are added to the data structure of the blockchain.1. Basic and advanced based on blockchain data structure
The data flow process of the blockchain network is like this. The nodes discover the transaction (data), and then package the transaction to form a block, and then the packaging node starts to broadcast, and the nodes participating in the consensus start to copy the block and save it (or the consensus node confirms After saving, other full nodes start replicating).In this way, the data on the blockchain becomes credible (open and transparent, and cannot be tampered with).The data is stored in the block. Because the block size is limited, the block is often filled with small-byte information, such as Bitcoin transfer transactions, Ethereum transfers and contract call messages.We can replace these transaction information with other information, such as commodity traceability and circulation information. It can also be replaced with any information that can be disclosed, such as advertisement clicks, usage of public welfare donations, bank joint account information, etc.However, due to the larger bytes of other information, it is more suitable to store small-byte information such as transaction data in blocks. After multi-party confirmation of the blockchain, these public data are credible and can be read and used.2. Chainlinks oracle network data structure
Chainlink’s Price Processing Model
After being processed on the chain, credible price data will be formed, which can be discovered and used by DeFi applications. According to the number of times the data is used, LINK tokens will be paid to the network as remuneration. incentive income.In this model, the data input from outside the Chainlink network is aggregated and processed on the chain, and finally flows to the demander to realize value.In this process, there are many key parts, such as updating the Oracle price for each price feed. Each price feed needs to obtain prices scattered in many places, and finally aggregate and process them, and the number of scattered oracle machines for each price feed is different. For example, in the ETH/USD price feed, there are 21 oracle feeds.In order to update the most accurate data at any time, the smart contract that processes the price feed must receive at least 14 of the 21 oracle machines to provide the price data before the data can be updated smoothly.Whether the data in the above operations is correct and credible is extremely important, otherwise there will be incidents of hijacking the oracle to attack the price of DeFi applications.Therefore, there must be certain rules for handling exceptions, including: taking the average value of the price; restarting the price update if the price deviation is large; specifying the price aggregation time, etc.3. Data flow based on hardware acquisition
Chainlinks model is widely used, but in the most basic structure above, if we carefully scrutinize, we can clearly see some shortcomings, such as data becoming credible through chain processing, but the process of data on chain and It is not controllable before going to the chain. The bigger problem is that Chainlink deals with simple data, that is, data with small bytes and strong publicity.Therefore, such a data model can make some process transformations, and finally create a data process like this:Terminal (data generation source) encryption--data storage--store data hash on the chain--data flow on the chainSuch a process can be described as a data flow based on the combination of hardware, distributed storage, and blockchain network. Currently, it is known for the integrated application of the Internet of Things network. Today, our example is Jasmy, an Internet of Things network that originated in Japan.The network has completed a cooperation with Toyota and Witz, a travel service provider, to process the terminal data of smart cars through the model of the platform, and to mine the value of data on the basis of avoiding personal information compliance.Lets dissect its data processing paradigm.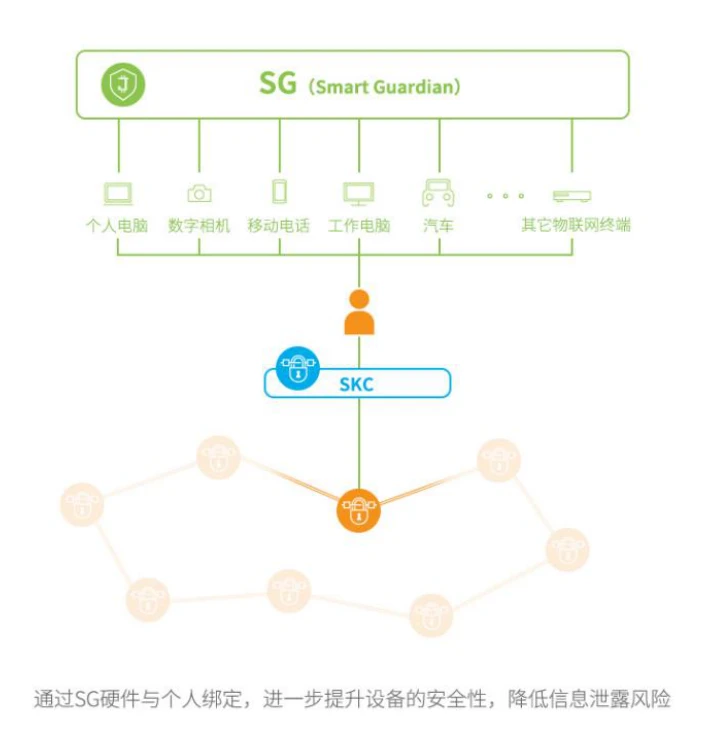 Examples of Jasmys management of hardware terminals
Examples of Jasmys management of hardware terminals
In this part, because a large number of terminal devices need to be managed, it is necessary to connect IoT devices to form an IoT platform, which is mainly responsible for device management.The next step is because the data category is complex and encrypted on the device side. In order to make the data callable, it is necessary to upload the data to an open network environment and ensure that the data can be checked and downloaded at any time. But its ownership and use rights require control.Therefore, in order to process large amounts of data, distributed storage will be used. The most convenient example is the data storage structure based on IPFS.4. Data processing paradigm of IoT technology integration
The difference between this process and Oracles implementation is that it uses IoT terminals to complete edge-side encryption and end-based encryption to complete subsequent transfers.Jasmys process is as follows:1. The IoT platform is responsible for managing terminal IoT devices, using Jasmys SKC service and SG service to realize terminal data encryption and management.2. The data of the terminal is stored in Jasmys personal data cabinet for distributed storage. SKC and SG technologies can locate the data to the personal ID or device ID during this process.3. The file hash of the distributed storage is uploaded to the chain, and the ID on the chain is bound to the file hash.4. The data transaction application developed based on the blockchain network can carry out the transfer of data value, that is, the exchange of data ownership and data usage rights.5. The data user can call the data in the distributed storage personal data cabinet.This process benefits from several characteristics of Jasmy. Jasmy has the encryption technology of Japanese hardware manufacturer Sony in the field of hardware and the supply chain capabilities in the field of Internet of Things. Other ordinary blockchain entrepreneurs cannot realize the advantages of the Internet of Things. It can be easily achieved. For example, SKCs core technology is FeliCa, a non-contact chip encryption technology that has been used in Japan for many years. This technology is providing security guarantee for Sony products. This is precisely the new calculation method added in the Jasmy structure.In addition, Jasmy can cooperate with hardware manufacturers to launch devices with terminal security and computing capabilities to participate in the network. For example, Jasmy has launched Jasmy Secure PC.The data value realization model shaped by Jasmy
5. Data flow based on trusted data computing
From the design model of Jasmy, we can see that the simple model of the blockchain can achieve outstanding results after some technical blessings. If more technologies are integrated, what can be achieved?For data, what data needs most is the attribution of ownership and the trusted flow of data based on data ownership, that is, the realization of data availability and invisible, and a series of requirements to ensure the rights and interests of data owners.We can define this paradigm as data flow based on a trusted computing model, which can be split into distributed storage, data ownership definition, and trusted execution. We use PlatON to illustrate this part.Hierarchical logic and functional allocation of PlatON
In the figure above, we can see that in the computing network of layer2, State is stored, which is the carrier node of data storage, and in this structure, it is an integrated application of account model and data storage.According to PlatON’s technical documentation, in state access, although PlatON continues to use the account model of Ethereum to store data, the state data is not stored in the Patricia tree (the storage structure of Ethereum) because of the large amount of data. It is stored separately in another SNAPDB (database) that does not store historical state.PlatONs data storage model
Therefore, the storage of PlatON is divided into account data storage (statedb) and snapshot storage (snapshotdb). Obviously, one is located in layer1 of the chain and the other is located in layer2.But in layer2, additional processing is performed on the data to give full play to its data computing characteristics. The processing is done by trusted computing devices and technologies, including verifiable computing (VC) algorithms that can realize non-interactive proof-of-chain computing Expansion scheme, secure multi-party computation (MPC) combined with secret sharing (SS) and homomorphic encryption (HE) to realize privacy computing protocols, etc.In addition, there is an MPC virtual machine to perform credible smart contract calculations, which is the basis for the operation of smart contracts in the entire network.Through the implementation of these layer2 layers, when the data flow and data application are finally realized, the original data can not be leaked and the calculation of collaborative calculation and result verification can be performed.It is worth noting that the computing devices connected to layer2 need to have dedicated computing capabilities in order to be able to implement the requirements of certain application scenarios. It requires super computing power and credible capabilities. Therefore, PlatON will enable high-performance computing devices developed such as FPGA/ASIC to access the network to meet the needs of this process.6. Application analysis of three data processing paradigms
The above three paradigms are the mainstream blockchain-based data processing methods, but what about the application of these three paradigms?Display of price feeds provided by some nodes of Chainlink
However, Oracle is a paradigm for simple high-frequency data. This model is simple and easy to apply, but it is not good at solving the legacy problems of the Internet society.For example, on data privacy issues, Oracle is more reliable in public data, but not good at unique data parts at all.The data flow based on the Internet of Things is obviously a paradigm for daily life and commercial data processing. For example, the application of Jasmy has already targeted Internet App data, enterprise office data, and data of certain hardware ecosystems.This is a paradigm that is designed from the user end to the platform and business ecological flow. This is also currently the most widely used paradigm structure.The final trusted computing is a paradigm mainly oriented towards the commercialization of data assets. The most difficult part to solve is that the data is available and invisible in the cooperation scenarios of commercialized data, and it is credible for huge amounts of data. It does not only require technology. , but requires equal emphasis on trusted technology, computing power, and storage.Therefore, these three paradigms have their own advantages and disadvantages, and the Oracle paradigm is most suitable for DeFi in the cryptocurrency field. Taking Jasmy as an example has the widest application boundary, and can cut into application fields other than simple financial data. The technology is relatively complete, but more detailed definition and specification of data is still needed. It can develop towards the third paradigm trend.7. Write at the end
The data problem is fierce, but the solution has been fully prepared in the practice of the innovator. Once the implementation process of the blockchain project is accelerated, the above three paradigms will create more business value.For example, Jasmy implements confidential design and terminal data management of enterprise data, which can increase the usable value of edge data and increase the utilization rate of enterprise data. PlatON realizes the availability and invisibility of data, which can then be applied in the field of AI privacy computing to help data application in the process of machine learning. This process is a breakthrough in many industries, such as AI+medical, AI+travel, AI+Internet applications, etc.A few years ago, we would say the future has come when we lamented the emergence of AI technology, but the author believes that now, after solving the data problem, we can really say the future has come with confidence, because this It is a new future where data belongs to the owner, and it is a new future that cannot be represented by the era of data chaos on the Internet. 









