




This article comes from:《What is Firedancer? A Deep Dive into Solana 2.0 》
Original author: 0xIchigo
Odaily Translator: Husband How

As we all know, Solana is one of the representatives of high performance in the current public chain. Its faster on-chain processing speed is sought after by many project parties and has also attracted the favor of traditional giants such as Visa. However, Solana has always had the hidden danger of network downtime. How to solve the problem of network downtime? The Firedancer client that Jump will launch to verify its client may be able to give the answer.
This article will start with the role of validators and validator clients on the blockchain, and explore how the Firedancer validator client supports the Solana network.
The following is compiled by Odaily.
What is validator and validator client diversity?
Validators are computers that participate in a proof-of-stake blockchain. Validators are the backbone of the Solana network, responsible for processing transactions and participating in the consensus process. Validators secure the network by locking up a certain amount of Solana’s native tokens as collateral. Staking tokens can be thought of as a security deposit that economically connects validators to the network. This connection incentivizes validators to perform tasks accurately and efficiently, as they are rewarded based on their contributions. At the same time, validators will also be penalized for malicious or malfunctioning behavior. A validators equity will be reduced due to improper behavior, a process called reduction. Therefore, validators have every incentive to perform their duties correctly in order to increase their stake.
The validator client is the application used by the validator to perform tasks. The client is the basis of the validator, participating in the consensus process through its cryptographically unique identity.
Having multiple different clients improves fault tolerance. For example, if no single client controls more than 33% of the share, a crash or liveness-impacting bug will not bring down the network. Likewise, if a client has a bug that causes an invalid state transition and less than 33% of shares use that client, the network is protected from security failure. This is because the majority of the network will remain in a valid state, preventing the blockchain from splitting or forking. Therefore, the diversity of validator clients can improve the resilience of the network, and an error or vulnerability in one client will not have a serious impact on the entire network.
Client diversity can be measured by the percentage of stake each client runs and the total number of available clients. At the time of writing this article,There are 1979 validators on the Solana network.The two clients used by these validators on mainnet are provided by Solana Labs and Jito Labs. When Solana launched in March 2020, it used a validator client developed by Solana Labs. In August 2022, Jito Labs released a second validator client. The client is a fork of the Solana Labs code maintained and deployed by Jito. The client optimizes the extraction of maximum extractable value (MEV) in blocks. Jitos client creates a pseudo memory pool because Solana streams chunks without a memory pool. It is worth noting that the mempool is a queue of unconfirmed and pending transactions. The pseudo mempool allows validators to search for these transactions, optimally bundle them together, and submit them to Jito’s block engine.
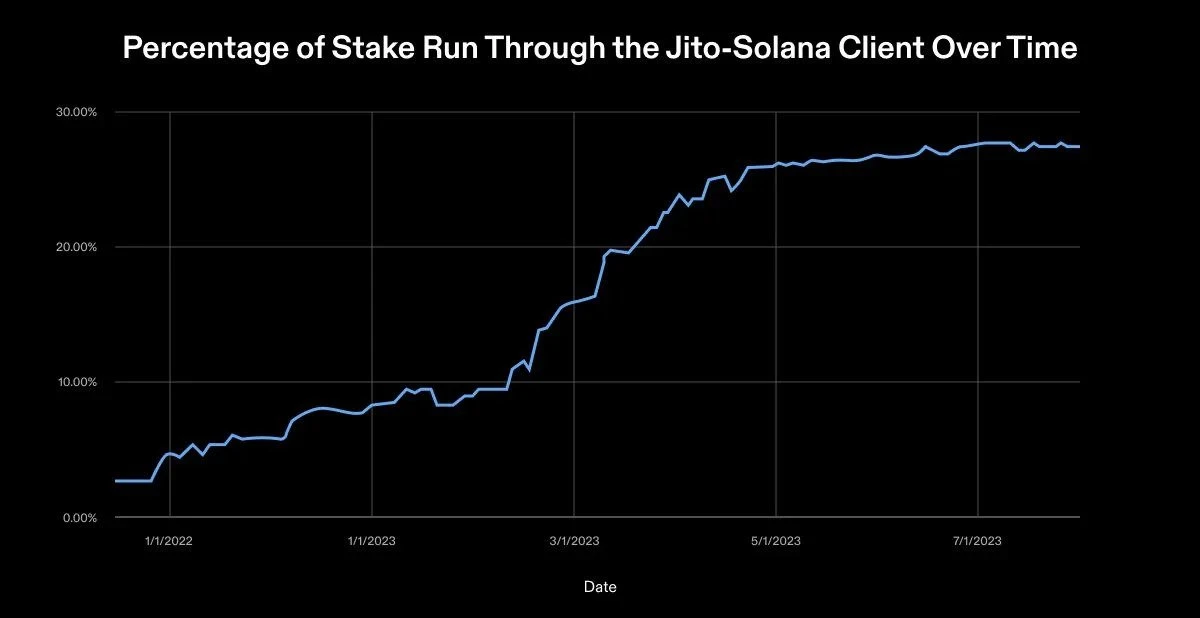
As of October 2023, Solana Labs clients hold 68.55% of active staking, while Jito holds 31.45%. The number of validators using the Jito client increased by 16% compared to the Solana Foundation’s previous health report. The growth in Jito client usage shows the evolving trend of client diversification.
While news of this growth is encouraging, its not perfect. It should be emphasized that Jito’s client is a fork of the Solana Labs client. This means that Jito shares many components with the original validator codebase and may be vulnerable to bugs or vulnerabilities affecting Solana Labs clients. In an ideal future, Solana should have at least four independent validator clients. Different teams will build these clients using different programming languages. No single implementation will exceed a 33% stake share, as each client will hold approximately 25%. This ideal setup would eliminate single points of failure throughout the validator stack.
Developing a second independent validator client is critical to achieving this future, and Jump is committed to making it happen.
Why is Jump building a new validator client?
Solana’s mainnet has been down four times in the past, each time requiring manual repairs by hundreds of validators. The outage highlights concerns about the reliability of Solanas network.Jump believes the protocol itself is reliable and attributes the downtime to issues with software modules affecting consensus.Therefore, Jump is developing a new validator client to solve these problems. The overall goal of this client is to improve the stability and efficiency of the Solana network.
Developing a standalone validator client is a difficult task. However, this isn’t the first time Jump has built a reliable global network. In the past, securities trading (i.e. buying and selling of stocks) was performed manually by market experts. With the emergence of electronic trading platforms, securities trading has become more open. This openness increases competition, automation, and reduces the time and cost for investors to trade. A technological competition began among market experts.
Traders trade for a living. A better trading experience requires greater focus on software, hardware and network solutions.These systems must have high machine intelligence, low real-time latency, high throughput, high adaptability, high scalability, high reliability, and high accountability.
One-size-fits-all solutions (i.e., software that companies can buy outright) are not a competitive advantage. Sending the correct order to the exchange in second place is an expensive way to lose money. Fierce competition in the high-frequency trading space has led to a never-ending cycle of development to build best-in-class global trading infrastructure.
This scenario may sound familiar. The requirements for a successful trading system are similar to those for a successful blockchain. Blockchain needs to be a network with superior performance, strong fault tolerance, and low latency. A slow blockchain is a failed technology that cannot meet the needs of modern enterprise applications and only hinders innovation, scalability, and real-world usefulness. With over two decades of experience developing global networks and high-performance systems, Jump is the perfect team to create independent validator clients. Jump Trading Chief Scientific Officer Kevin Bowers oversaw the build process from start to finish.
Why is the speed of light too slow?
Kevin Bowers elaborates on the problem of light being too slow. The speed of light is a finite constant that provides a natural limit to the number of calculations a single transistor can handle. Currently, bits are modeled by electrons traveling through transistors. Shannons capacity theorem, which is the maximum amount of error-free data that can be sent on a channel, limits the number of bits that can be transmitted through a transistor. Due to limitations in fundamental physics and information theory, computing speed is limited by how fast electrons move through matter and the amount of data that can be sent. These constraints become apparent when pushing supercomputers to their limits. As a result, there is a significant mismatch between a computers ability to process data and its ability to transmit it.
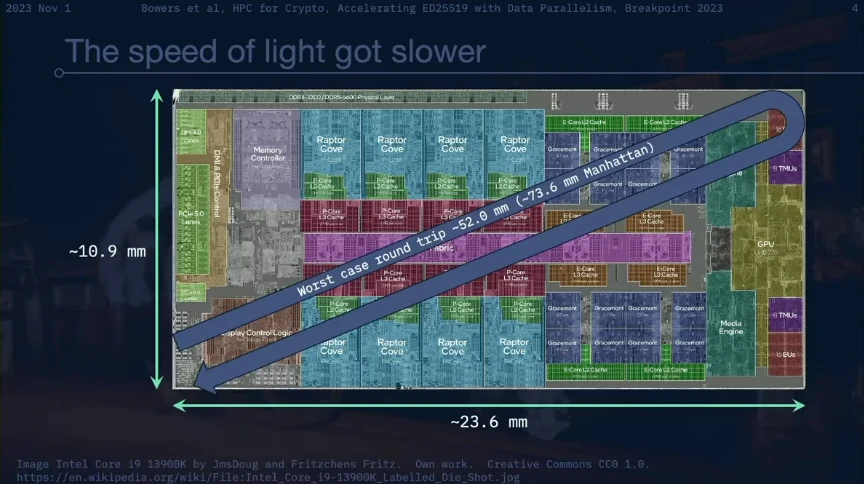
Take the Intel Core i 9 13900 K CPU as an example. It has 24 x 86 cores with a base clock speed of 2.2 GHz and a maximum turbo clock speed of 5.8 GHz. The worst case scenario is that the light needs to travel a total distance of about 52.0 mm within the CPU. The Manhattan distance (i.e., the distance between two points measured along a right-angled axis) for a CPU is approximately 73.6 mm. At the CPUs maximum turbo clock frequency of 5.8 GHz, light can travel approximately 51.7 mm through the air. This means that in a single clock cycle, a signal can complete a round trip between almost any two points on the CPU.
However, the reality is far worse. These measurements use the speed of light traveling through air, while the signal is actually transmitted through silicon dioxide (SiO2). At a clock cycle of 5.8 GHz, light can travel about 26.2 millimeters in silicon dioxide. In silicon (Si), light can only travel about 15.0 millimeters at a 5.8 GHz clock cycle, a little more than half the long side of a CPU.
The Firedancer team believes that advances in computing technology in recent years have been more about packing more cores into CPUs rather than making them faster. When people need more performance, they are encouraged to buy more hardware. This currently works in situations where throughput is the bottleneck. The actual bottleneck is the speed of light. This natural limitation leads to decision-making paralysis. As with any kind of optimization, there are many components in the system that have no immediate payoff because they are not well optimized. Unoptimized parts deteriorate over time because they have less computing resources available to them. So, what to do now?
In high-performance computing, everything must ultimately be optimized. The result is a production system oriented towards quantitative trading and quantitative research, operating at the limits of physics and information theory on a global scale. This includes lock-free algorithms that create custom network switching technology to meet these physical constraints. Jump is as much a trading company as it is a technology company. On the cutting edge of science fiction and reality, there are striking similarities between the problems currently facing Jump and Solana, which is developing Firedancer.
What is Firedancer?
Firedancer is a new standalone validator client developed in C language by the Firedancer team. Firedancer is designed with reliability in mind, using a modular architecture, minimal dependencies, and an extensive testing process. It proposes a major rewrite of the three functional components of the Solana Labs client (network, runtime, and consensus). Each level is optimized for maximum performance, so the clients ability to run is only limited by the validator hardware and not by the performance limitations caused by the software inefficiencies currently faced. With Firedancer, Solana will be able to scale based on bandwidth and hardware.
The goals of Firedancer are:
Document and standardize the Solana protocol (eventually, people should be able to create a Solana validator by looking at the documentation rather than the Rust validator code);
Increase the diversity of validator clients;
Improve ecosystem performance.
How Firedancer works
Modular architecture
Firedancer differentiates itself from current Solana validator clients through its unique modular architecture. Unlike Solana Labs Rust validator client, which runs as a single process, Firedancer is composed of many independent Linux C processes called tiles. A tile is a process and some memory. This tile architecture is the basis of Firedancers operating philosophy and approach to improving robustness and efficiency.
A process is an instance of a running program. It is a fundamental component of modern operating systems and represents the execution of a set of instructions. Each process has its own memory space and resources, and the operating system allocates and manages these resources independently without being affected by other processes. Processes are like independent workers in a big factory, using their own tools and workspaces to handle specific tasks.
In Firedancer, each tile is an independent process with a specific role. For example, the QUIC tile is responsible for handling incoming QUIC traffic and forwarding encapsulated transactions to the verify tile. The verify tile is responsible for signature verification, and other tiles have similar tasks. These tiles run independently and concurrently and together constitute the functionality of the entire system. Independent Linux processes can form small, independent fault domains. This means that an issue with one tile will only have a minimal impact on the entire system, or a small scope of impact, without immediately endangering the entire validator.
A key advantage of the Firedancer architecture is the ability to replace and upgrade each tile in seconds without any downtime. This is in contrast to the requirement that Solana Labs Rust validator client needs to be shut down completely before upgrading. This difference stems from Rusts lack of ABI (Application Binary Interface) stability, which prevents on-the-fly upgrades in a pure Rust environment. With the C process approach, you can rely on the binary stability in the C runtime model to significantly reduce upgrade-related downtime. This is because individual tiles manage validator state in different workspaces. These shared memory objects persist as long as the validator is powered on and running. During a reboot or upgrade, each tile can seamlessly pick up where it left off.
Overall, Firedancer is built on a NUMA-aware, tile-based architecture. In this architecture, each tile uses one CPU core. It features high-performance messaging between tiles, optimizing memory locality, resource layout, and component latency.
network processing
Firedancers network processing is designed to handle the intense demands of Solanas network as it upgrades to gigabit-per-second speeds. This process is divided into inbound and outbound activities.
Inbound activity mainly involves receiving transactions from users. The performance of Firedancer is very important because if the validator falls behind in processing packets, consensus messages can be lost. Solana nodes currently operate at approximately 0.2 Gbps, while Jump nodes have recorded maximum bandwidth peaks of approximately 40 GBps. This bandwidth spike highlights the need for a robust and scalable inbound processing solution.
Outbound activities include block packing, block creation, and sending shards. These steps are critical to the secure and efficient operation of the Solana network. The performance of these tasks not only affects throughput but also the overall reliability of the network.
Firedancer aims to solve Solana’s past problems with its point-to-point interface for processing transactions. A significant shortcoming of the Solana point-to-point interface in the past was its lack of congestion control when processing inbound transactions. This shortcoming resulted in outages on September 14, 2021 (17 hours) and April 30, 2022 (7 hours).
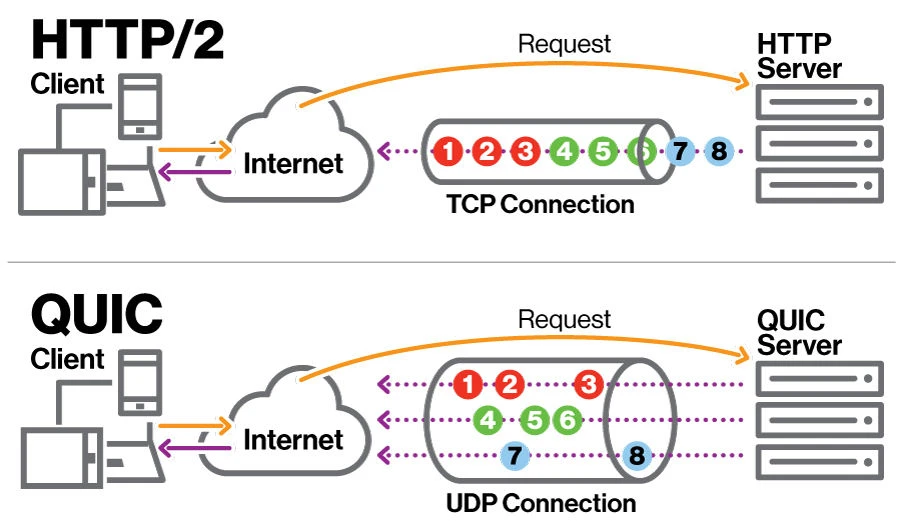
In response, Solana made several network upgrades to properly handle high transaction loads. Firedancer followed suit, adopting QUIC as its traffic control scheme.QUIC is a multiplexed transport network protocol that is the basis of HTTP/3.It plays an important role in defending against DDoS attacks and managing network traffic. However, it is important to note that in some cases the costs outweigh the benefits. QUIC is used in conjunction with dedicated data center hardware to mitigate DDoS attacks, removing the incentive for transaction flooding attacks.
QUICs 151-page specification introduces considerable complexity to development. Unable to find an existing C library that met their licensing, performance, and reliability needs, the Firedancer team built their own implementation. Firedancers QUIC implementation, nicknamed fd_quic, introduces optimized data structures and algorithms to ensure minimal memory allocation and prevent memory exhaustion.
Firedancers custom network stack is at the heart of its processing power. The stack was designed from the ground up to take advantage of Receive Side Scaling (RSS). RSS is a hardware-accelerated form of network load balancing that distributes network traffic to different CPU cores to increase parallelism in network processing. Each CPU core handles a portion of the incoming traffic with little additional overhead. This approach outperforms traditional software-based load balancing by eliminating complex schedulers, locks, and atomic operations.
Firedancer introduces a new messaging framework for composing high-performance tile applications. These tiles can bypass the limitations of socket-based kernel networking by leveraging AF_XDP, an address family optimized for high-performance packet processing. Use AF_XDP to enable Firedancer to read data directly from the network interface buffer.
This tile system implements various high-performance computing concepts within the Firedancer stack, including:
NUMA Aware - NUMA (Non-Uniform Memory Access) is a computer memory design in which a processor accesses its own memory faster than accesses memory associated with other processors. For Firedancer, being NUMA aware means the client can handle memory efficiently in multi-processor configurations. This is important for high transaction volume processing as it optimizes the utilization of available hardware resources.
Cache Locality - Cache locality refers to utilizing data that is already stored in cache close to the processor. This is usually a variant of temporal locality (i.e. the most recently accessed data). In Firedancer, the focus on cache locality means it is designed to handle network data while minimizing latency and maximizing speed.
Lock-free concurrency - Lock-free concurrency refers to designing algorithms that do not require a locking mechanism (such as a mutex) to manage concurrent operations. For Firedancer, lock-free concurrency allows multiple network operations to execute in parallel without delays due to locks. Lock-free concurrency enhances Firedancers ability to handle large numbers of transactions simultaneously.
Large page sizes - Using large page sizes in memory management helps with processing data sets, reducing page table lookups and potential memory fragmentation. For Firedancer, this means improved memory handling efficiency. This is very beneficial for processing large amounts of network data.
Build system
Firedancers build system follows a set of guiding principles to ensure reliability and consistency. It emphasizes minimizing external dependencies and treats all tools involved in the build process as dependencies. This includes pinning every dependency (including the compiler) to an exact version. A key aspect of this system is environment isolation during the build step. Environment isolation enhances portability because the build process is not affected by the system environment.
Why Firedancer is faster
Advanced data parallelism
Firedancer leverages the advanced data parallelism available inside modern processors in cryptographic tasks such as ED 25519 signature verification. Modern CPUs have Single Instruction Multiple Data (SIMD) instructions for processing multiple data elements simultaneously, as well as the ability to optimize running multiple instructions per CPU cycle. It is often more efficient in area, time, and power to operate a single instruction on an array or vector of data elements in parallel. Here, improvements in parallel data processing can dominate throughput improvements compared to pure processing speed improvements.
One area where Firedancer uses data parallelism is in optimizing computational signature verification. This approach allows simultaneous processing of data elements in an array or vector to maximize throughput and minimize latency. The core of the ED 25519 implementation is the Galois field operation. This form of arithmetic is well suited for cryptographic algorithms and binary calculations. In Galois fields, operations such as addition, subtraction, multiplication, and division are defined based on the binary nature of computer systems. Here is an example of a Galois field defined by 2^3:
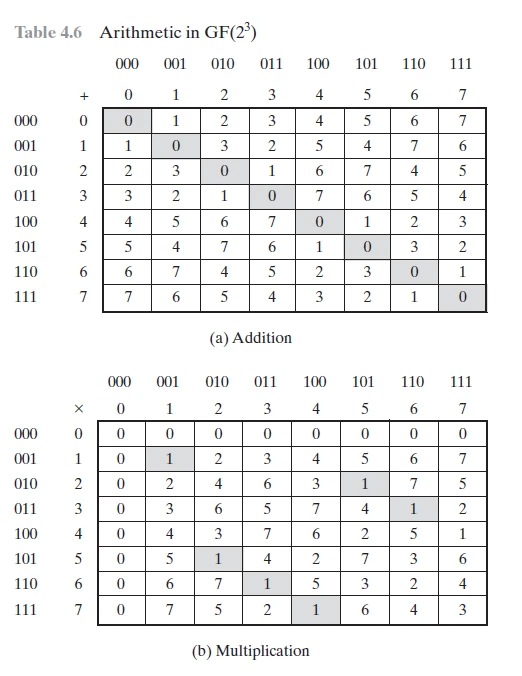
The only problem is that ED 25519 uses a Galois field defined by 2^(255-19). You can think of domain elements as numbers from 0 to 2^(255-19). The basic operations are as follows:

Addition, subtraction and multiplication are almost uint 256 _t math (i.e. calculations using unsigned integers where the maximum is 2^(256-1)). Division calculations are challenging. Common CPUs and GPUs do not support uint 256 _t Math, let alone almost uint 256 _t math, not to mention incredibly difficult division. Implementing this math and making it performant is a key issue, depending on how well we can simulate this math.

Firedancers implementation breaks down arithmetic operations by handling numbers more flexibly. If we apply the principles of ordinary long division and multiplication, carrying numbers from one column to the next, we can process the columns in parallel. The fastest way to simulate this math is to represent uint 256 _t as six 43-bit numbers, with a 9-bit carry. This allows existing 64-bit operations to be performed on the CPU while providing sufficient room for the carry bit. This arrangement of numbers reduces the need for frequent carry propagation and enables Firedancer to handle large numbers more efficiently.
This implementation exploits data parallelism by reorganizing arithmetic calculations into parallelized column sums. Processing columns in parallel can speed up overall computation because it turns tasks that might otherwise be sequential bottlenecks into parallelizable tasks. Firedancer also uses vectorized instruction sets such as AVX 512 and its IFMA extension (AVX 512-IFMA). These instruction sets allow processing of the Galois field arithmetic described above, resulting in increased speed and efficiency.
Firedancers implementation of AVX 512 acceleration is very fast. On a single 2.3 GHz Icelake server core, clock performance per core is more than double that of its 2022 Breakpoint demo. The implementation features 100% vector channel utilization and massive data parallelism. This is another great demonstration from the Firedancer team that thanks to lightspeed latency, its much easier to do independent parallel tasks at the same time than to do one thing at a time, even with custom hardware.
Enable high-speed network communications with FPGAs
The CPU can handle approximately 30,000 signature verifications per second per core. While they are an energy-efficient option, they have shortcomings for large-scale operation. This limitation stems from their sequential processing approach. GPUs boost this processing power to about 1 million validations per second per core. However, they consume approximately 300 W per unit and have inherent latency due to batch processing.
FPGAs become the better choice. They match the throughput of GPUs but consume significantly less power, around 50 W per FPGA. The latency is also lower than the ten millisecond latency of the GPU. FPGAs provide a more responsive real-time processing solution with approximately 200 microsecond latency. Unlike the GPUs batch processing, the FPGA in Firedancer processes each transaction individually in a streaming fashion. The result of Firedancers use of FPGAs is that 8 FPGAs can process 8 million signatures per second while consuming less than 400 W of power.
The team demonstrated Firedancer’s ED 25519 signature verification process at Breakpoint 2022. The process involves multiple stages, including SHA-512 calculations in a pure RTL pipeline and various checks and calculations in a custom ECC-CPU processor pipeline. Basically, the Firedancer team wrote a compiler and assembler for their custom processor, took the Python code from the RFC (Request for Comments), used the operator overloaded objects to generate machine code, and then put the machine code in ECC -On top of the CPU.

Notably, Firedancer adopts the form factor style of AWS accelerators to strike a balance between robustness and network connectivity. This option solves the challenges associated with direct network connectivity, a feature that is often limited among cloud providers. With this choice, Firedancer ensures that its advanced capabilities can be seamlessly integrated within the constraints of cloud infrastructure.
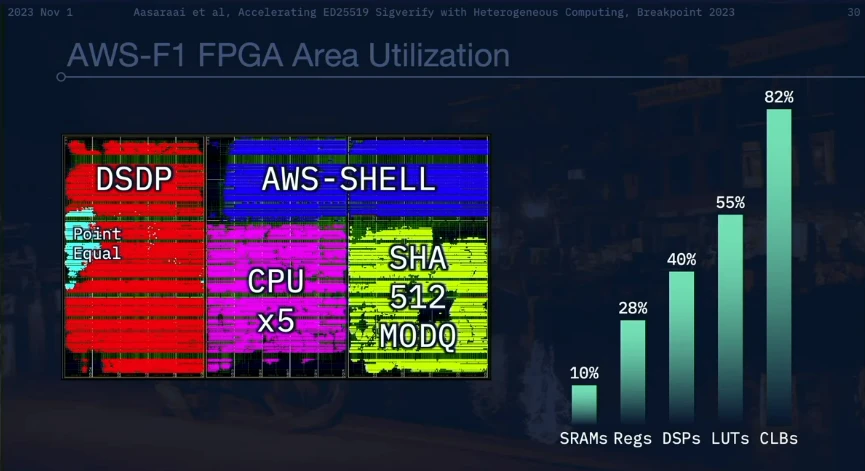
We must realize that different operations require actual physical space, not just conceptual data space. Firedancer works by strategically arranging the location of physical components to make them compact and reusable. This configuration allowed Firedancer to maximize the efficiency of its FPGA, achieving 8 million transactions per second using a 7-year-old FPGA on an 8-year-old machine.
A fundamental challenge in network communications is broadcasting new transactions globally
The point-to-point nature of the Internet, limited bandwidth, and latency issues limit the feasibility of traditional methods such as direct broadcasting using the network. Distributing data in a ring or tree structure partially solves these problems, but packets may be lost during transmission.
Reed-Solomon coding is the preferred solution to these problems. It introduces data transmission redundancy (i.e., parity information) to recover lost packets. The basic concept is that two points can define a straight line, and any two points on this straight line can reconstruct the original data points. By building a polynomial based on the data points and distributing the different points of this function across separate packets, the original data can be reconstructed as long as the receiver receives at least two packets.
We construct polynomials because using the traditional formula for points on a straight line (y = mx + b) is computationally slow. Firedancer uses Lagrangian polynomials (a specialized method for polynomial construction) to speed things up. It simplifies the creation of polynomials required for Reed-Solomon encoding. It also transforms the process into a more efficient matrix-vector multiplication for higher-order polynomials. This matrix is highly structured, with patterns that recur in a recursive manner such that the first row of the pattern completely determines it. This structure means there is a faster way to perform multiplication calculations. Firedancer uses an O(n log n) method, which it described in a 2016 article on how to use this matrix for multiplication, which is the fastest theoretical method of Reed-Solomon encoding currently known. The result is a highly efficient way to calculate parity information compared to traditional methods:
RS encoding speeds of over 120 Gbps per core;
RS decoding speeds up to 50 Gbps per core;
These metrics compare to the current ~8 Gbps/core RS encoding (rust-rse).
Using this optimized Reed-Solomon encoding method, Firedancer can calculate parity information 14 times faster than traditional methods. This makes the data encoding and decoding process fast and reliable, critical to maintaining high throughput and low latency around the world.
How does Firedancer stay safe?
Chance
All validators currently use software based on the original validator client. If Firedancer differs from Solana Labs clients, then Firedancer could improve Solanas client and supply chain diversity. This includes using similar dependencies and using Rust to develop their clients.
Solana Labs and Jito validator clients run as a separate process. Adding security to a monolithic application is difficult once its running in production. Validators running these clients will have to be shut down for immediate security upgrades to pure Rust. The Firedancer team was able to develop their new client with a security architecture built in from the start.
Firedancer also has the advantage of learning from past experiences. Solana Labs developed the validator client in a startup environment. This fast-paced environment means Labs need to move quickly to get to market quickly. This makes their future development prospects worrying. The Firedancer team can look at what Labs has done, and what teams on other chains have done, and ask what they would do differently if they could develop a validator client from scratch.
challenge
Although different from Solana Labs client, Firedancer must closely replicate its behavior. Failure to do this may introduce consistency errors and thus become a security risk. This problem can be mitigated by incentivizing a portion of the share to run on both clients, keeping Firedancers total share below 33% of the total share for longer periods of time. Regardless, the Firedancer team needs to implement the protocols full feature set, regardless of how difficult or secure it is to implement. Everything has to be consistent with Firedancer. Therefore, teams cannot develop code in isolation and must review it against the capabilities of the Labs client. This is exacerbated by a lack of specification and documentation, which means Firedancer has to introduce inefficient constructs into the protocol.
The Firedancer team also had to be aware that they were developing their new client in C. The C language does not provide memory safety guarantees natively like languages like Rust. The primary goal of the Firedancer codebase is to reduce the occurrence and impact of memory safety vulnerabilities. This goal requires special attention because Firedancer is a fast-paced project. Firedancer must find a way to maintain development speed without introducing such bugs. Operating system sandboxing is the practice of isolating Tiles from the operating system. Tile is only allowed to access the resources and perform system calls required for its work. Because Tile has a well-defined purpose and the Firedancer team develops mostly client-side code, Tiles permissions are stripped away based on the principle of least privilege.
Implement a defense-in-depth design
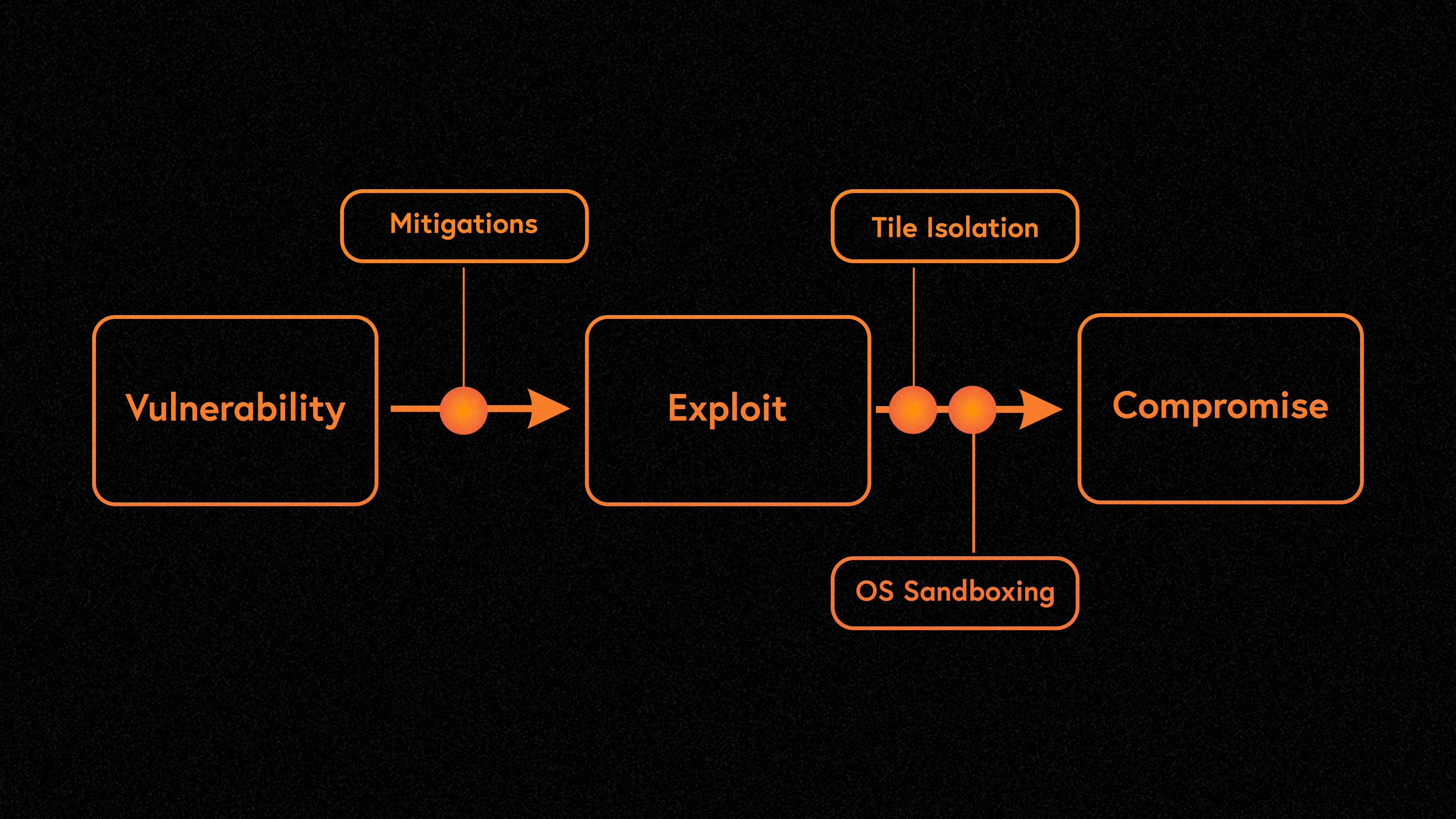
All software has security vulnerabilities at some point. Starting from the premise that the software will have bugs, Firedancer chooses to limit the potential impact of any one vulnerability. This approach is called defense in depth. Defense in depth is a strategy that uses a variety of security measures to protect assets. If an attacker compromises one part of the system, additional measures exist to prevent the threat from affecting the entire system.
Firedancer is designed to mitigate risks between vulnerabilities and exploitation stages. For example, memory safety vulnerabilities are difficult for attackers to exploit. This is because preventing this type of attack is a well-researched problem. In C, intensive research on memory safety led to a series of hardening techniques and compiler features that the team used in Firedancer. Even if an attacker is able to bypass industry best practices, it will be difficult to compromise a system by exploiting vulnerabilities. This is due to Tile isolation and the presence of operating system sandboxing.
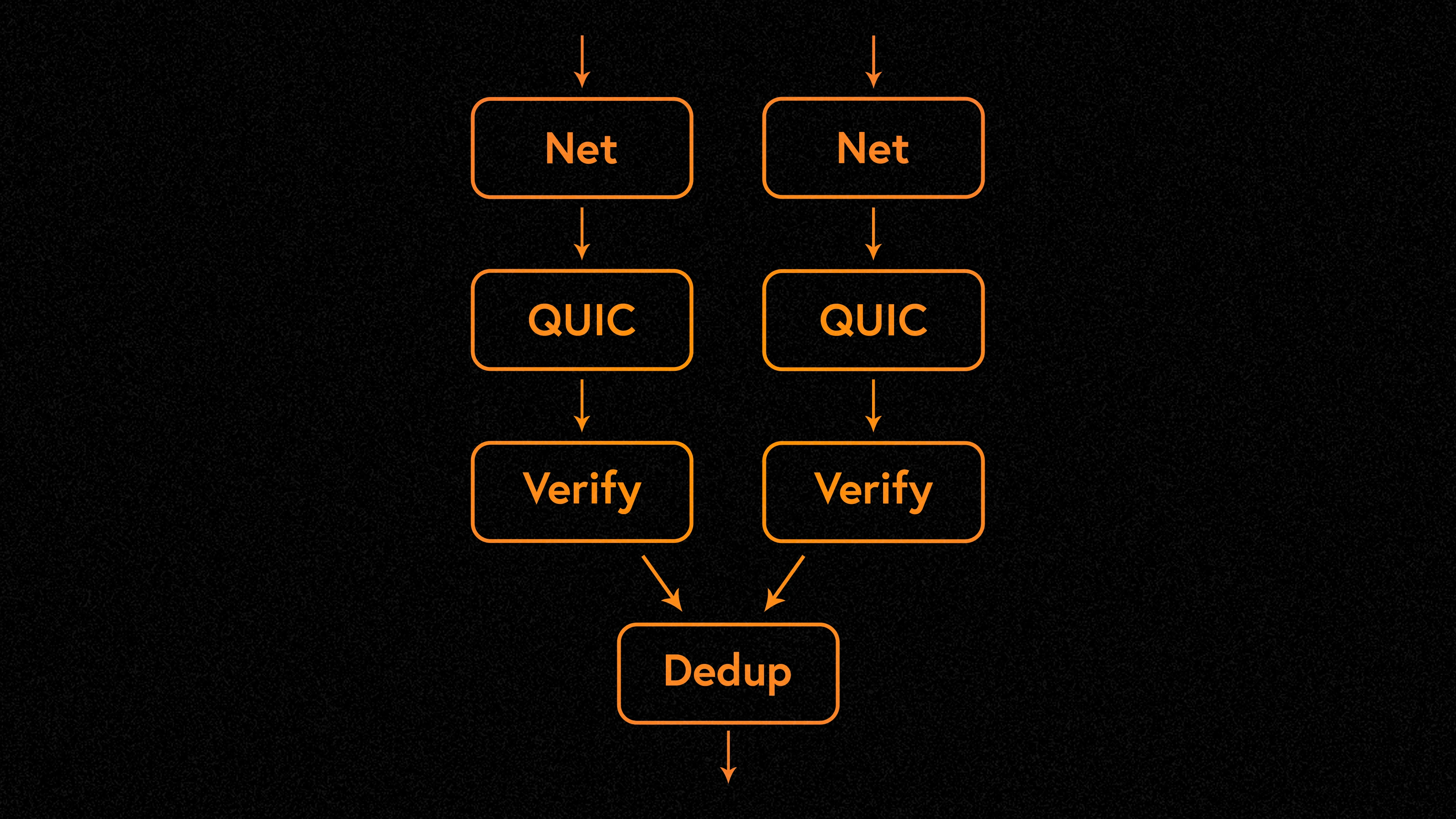
Tile isolation is a result of Firedancers parallel architecture. Since each Tile runs in its own Linux process, they have a clear, single purpose. For example, a QUIC Tile is responsible for handling incoming QUIC traffic and forwarding encapsulated transactions to the validation tile. The verification tile is then responsible for signature verification. Communication between the QUIC Tile and the Verification Tile is done through a shared memory interface (i.e. Linux processes can pass data between each other). The shared memory interface between two Tiles acts as an isolation boundary. If a QUIC Tile contains a bug that allows an attacker to execute arbitrary code when processing malicious QUIC packets, it will not affect other Tiles. In a single process, this would result in an immediate compromise. If an attacker exploited this vulnerability to target multiple validators, they could cause harm to the entire network. It is possible for an attacker to degrade QUIC Tile performance, but Firedancers design limits this to QUIC Tiles.
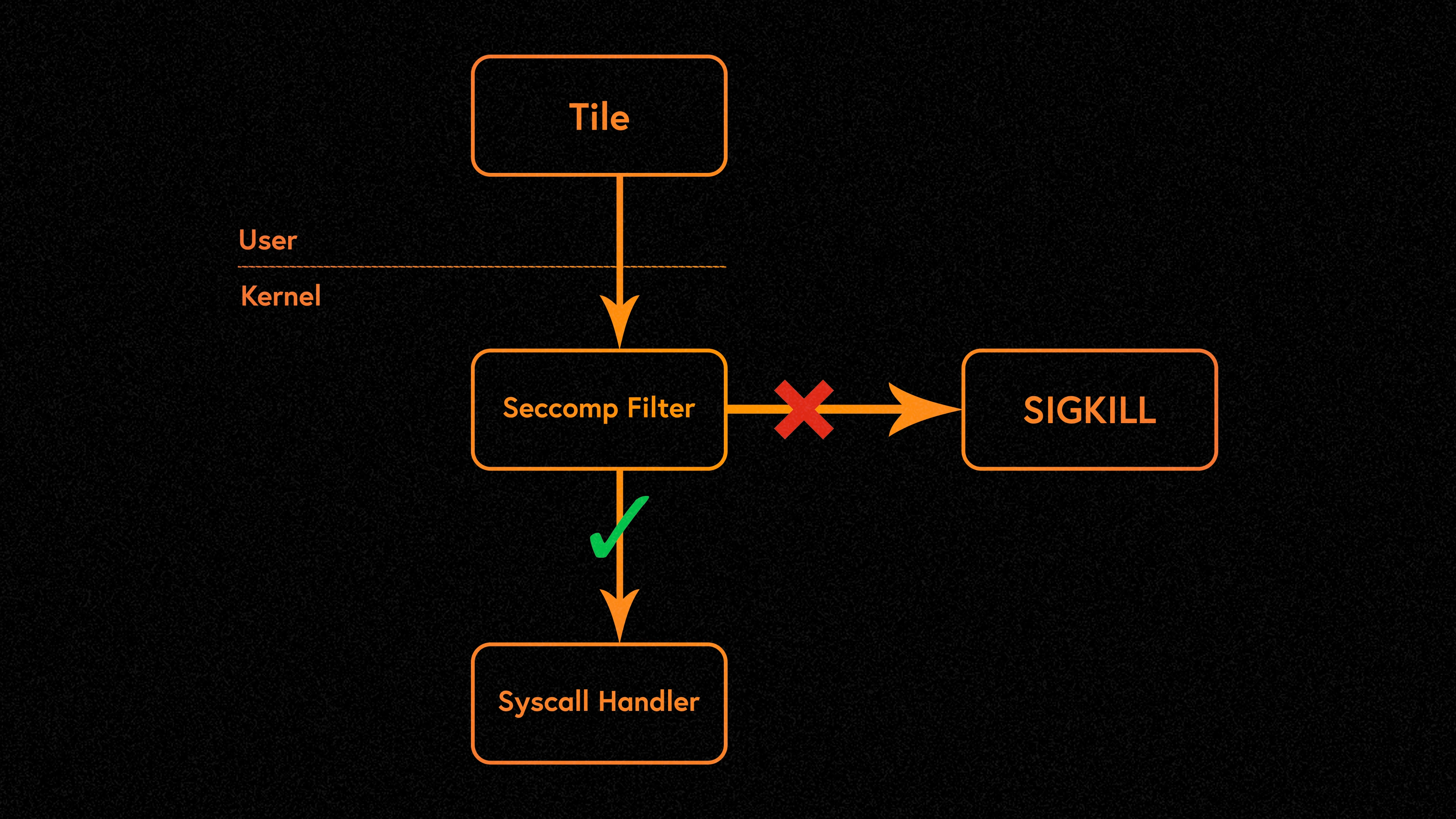
Operating system sandboxing is the practice of isolating Tiles from the operating system. Tile is only allowed to access the resources and perform system calls required for its work. Because Tile has a clearly defined purpose and nearly all of its code is developed by the Firedancer team, Tiles permissions are stripped to the bare minimum based on the principle of least privilege. Tile is placed in its own Linux namespace, providing a limited view of the system. This narrow view prevents Tile from accessing most of the file system, the network, and any other processes running on the same system. Namespaces provide a security-first boundary. However, this isolation can still be bypassed if an attacker has a kernel vulnerability that elevates privileges. The system call interface is the last attack vector in the kernel reachable from Tile. To prevent this, Firedancer uses seccomp-BPF to filter system calls before they are processed by the kernel. Clients can restrict Tiles to a select set of system calls. In some cases, it is possible to filter the parameters of a system call. This is important because Firedancer ensures that read and write system calls only operate on specific file descriptors.
Adopt an embedded security plan
During the development of Firedancer, attention was paid to embedding comprehensive safety procedures at every stage. The client’s security program is the result of ongoing collaboration between the development and security teams, setting a new standard for secure blockchain technology.
The process starts with self-service fuzz testing infrastructure. Fuzz testing is a technique that automatically detects crashes or error conditions that indicate vulnerabilities. Fuzz testing is performed by stress testing every component that accepts untrusted user input, including the P2P interface (parser) and the SBPF virtual machine. OSS-Fuzz maintains continuous fuzz coverage during code changes. The security team also set up a dedicated ClusterFuzzer instance for ongoing coverage-guided fuzz testing. Developers and security engineers also provide tools for fuzz testing (that is, unit testing against special versions of security-critical components). Developers can also contribute new fuzz tests, which are automatically received and tested. The goal is to fully fuzz test all parts before moving to the next stage.
Internal code reviews help uncover vulnerabilities that tools might miss. At this stage, the focus is on high-risk, high-impact components. This stage is a feedback mechanism that provides feedback to other parts of the security program. The team applies all the lessons learned in these reviews to improve fuzz testing coverage, introduce new static analysis checks for specific vulnerability classes, and even implement large-scale code refactorings to rule out complex attack vectors. External security reviews will be complemented by industry-leading experts and an active bug bounty program, both pre- and post-launch.
Firedancer has also undergone extensive stress testing on various test networks. These test networks will be exposed to various attacks and failures such as node duplication, network link failure, packet flooding, and consensus violations. The loads these networks endure far exceed anything realistic on mainnet.
So, this begs the question: What is the current status of Firedancer?
Whats the current status of Firedancer, and what is Frankendancer?
The Firedancer team is gradually developing Firedancer to modularize the validator client. This is consistent with their goals for documentation and standardization. This approach ensures that Firedancer stays up to date with the latest developments in Solana. This led to the creation of the Frankendancer. Frankendancer is a hybrid client model where the Firedancer team integrates its developed components into the existing validator client infrastructure. This development process allows for incremental improvements and testing of new features.
The Frankendancer is like putting a sports car in the middle of traffic. Performance will continue to improve as more components are developed and bottlenecks are eliminated. This modular development process facilitates a customizable and flexible validator environment. Here, developers can modify or replace specific components in the validator client according to their needs.
What actually runs
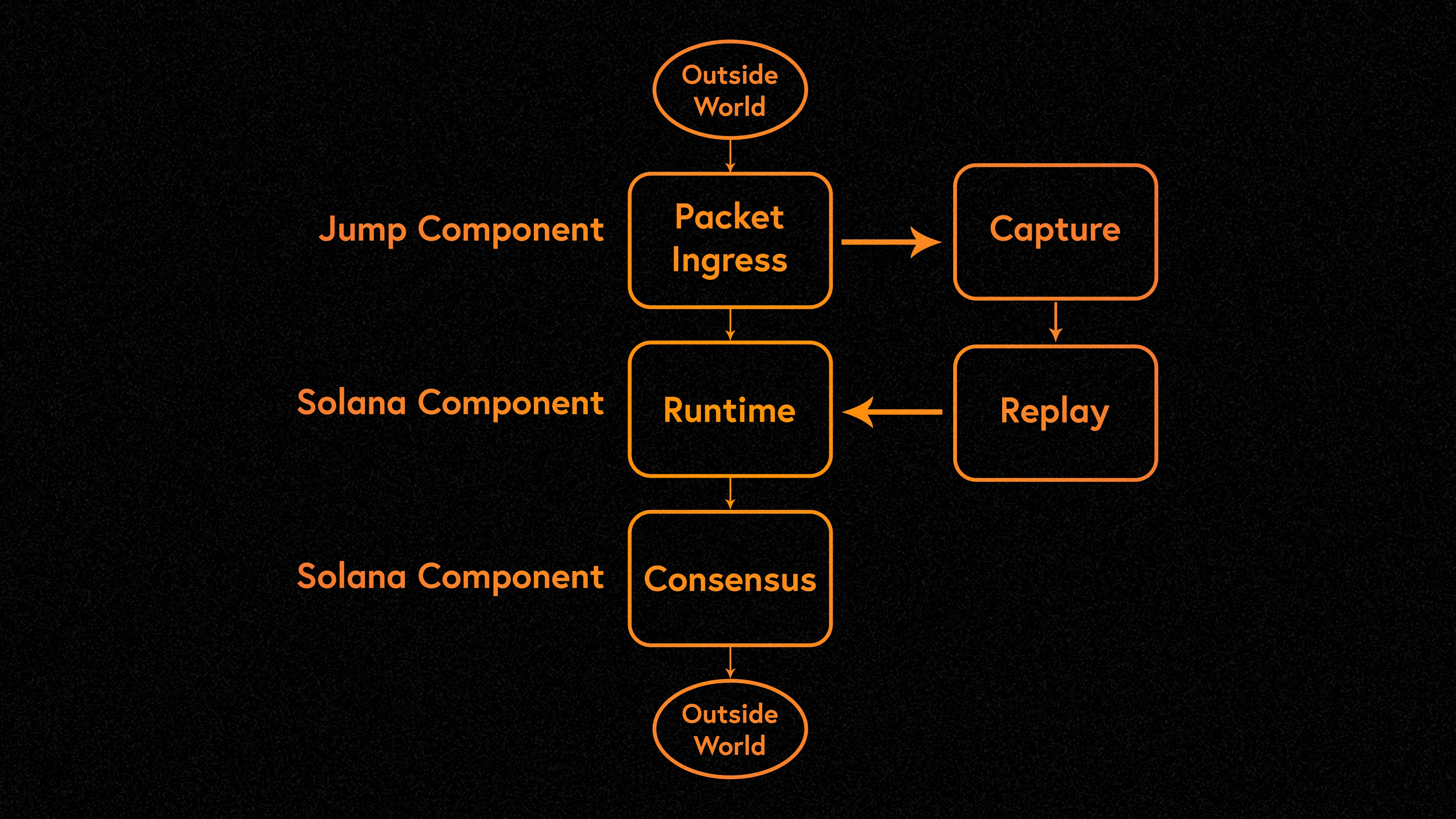
Frankendancer implements all the networking functionality of the Solana validator:
Inbound: QUIC, TPU, Sigverify, Dedup
Outbound: Block packing, creating/signing/sending Shreds (Turbine)
Frankendancer uses Firedancers high-performance C networking code on top of Solana Labs Rust runtime and consensus code.
Frankendancers architectural design focuses on high-end hardware optimization. While it supports low-end cloud hosts running standard Linux operating systems, the Firedancer team is optimizing Frankendancer for high-core-count servers. The long-term goal is to leverage existing hardware resources in the cloud to improve efficiency and performance. The client supports multiple connections simultaneously, hardware acceleration, randomized traffic steering for load distribution (ensuring even distribution of network traffic), and multiple process boundaries to provide additional security between components.
Technical efficiency is the cornerstone of Frankendancer. The system avoids memory allocations and atomic operations on the critical path, and all allocations are NUMA optimized upon initialization. This design ensures maximum efficiency and performance. Additionally, the ability to inspect system components asynchronously and remotely, as well as flexible management of Tiles (asynchronous start, stop, and restart), adds a layer of robustness and adaptability to the system.
How does Frankendancer fare?
Each Tile of Frankendancer can handle 1,000,000 transactions per second (TPS) on the inbound side of the network. Since each Tile uses one CPU core, the performance scales linearly with the number of cores used. Frankendancer achieves this feat by using only four cores and fully utilizing the 25 Gbps network interface cards (NICs) on each core.
When it comes to network outbound operations, Frankendancer has achieved significant improvements with its Turbine optimizations. Current standard node hardware achieves speeds of 6 Gbps per tile. This includes massive speed improvements in sharding (i.e. how blocks of data are divided and sent to the validator network). Compared to current standard Solana nodes, Frankendancer shows about 22% sharding speedup without Merkle trees and almost double when using Merkle trees. This is a huge improvement over current validator block propagation and transaction reception performance.
Firedancers network performance shows that it reaches the limits of its hardware, achieving maximum performance compared to todays standard validator hardware. This marks an important technology milestone, demonstrating the clients ability to handle extreme workloads effectively and efficiently.
Frankendancer has been launched on the testnet
Frankendancer is currently staking, voting, and producing blocks on the test network. It is compatible with Solana Labs and Jito and approximately 2900 other validators. This real-world deployment demonstrates the power of Firedancer on commodity hardware. It is currently deployed on an Equinix Metal m 3.large.x 86 server with an AMD EPYC 7513 CPU. Many other validators also use the same type of server. It offers an affordable solution, with on-demand pricing ranging from $3.10 to $4.65 per hour, which varies by location.
Firedancer’s progress toward mainnet launch opens up several possibilities for node hardware:
Current validator hardware enables higher per-node performance capacity;
Firedancer’s efficiency allows validators to use more affordable, lower-spec hardware while maintaining similar performance levels;
Firedancer is designed to take advantage of advances in hardware and bandwidth.
These developments, along with other initiatives like Wiredancer (the Firedancer team’s experiment with hardware acceleration) and the Rust-based modular runtime/SVM, make Firedancer a forward-thinking solution.
Firedancers progress has also sparked discussion about whether to have validators run the Solana Labs client alongside Firedancer, which is known as running in parallel. This approach maximizes network activity by leveraging the strengths of both clients and mitigating the potential impact of either client on the overall network. Additionally, this has led to speculation as to whether projects like Jito would consider forking Firedancer. This may further optimize MEV extraction and transaction processing efficiency. Only time will tell.
in conclusion
Developers often think of operations as occupying data space rather than physical space. With the speed of light as a natural limit, this assumption results in a system that is slower and unable to properly optimize its hardware. In a highly adversarial and competitive environment, we cannot simply throw more hardware into Solana and expect it to perform better. We need to optimize. Firedancer revolutionizes the structure and operation of validator clients. By building a reliable, highly modular and performant validator client, the Firedancer team is preparing for mass adoption of Solana.
Whether youre a junior developer or a regular Solana user, its crucial to understand Firedancer and what it means. This technological feat makes the fastest, highest performing blockchain on the market even better. Solana is designed to be a high-throughput, low-latency global state machine. Firedancer is a huge step toward perfecting these goals.





