




Original author: Yuxing
This article is for communication and learning purposes only and does not constitute any investment advice.

The popularity of ChatGPT and GPT-4 has shown us the power of artificial intelligence. Behind artificial intelligence, in addition to algorithms, what is more important is massive data. We have built a large-scale complex system around data, the value of which mainly comes from business intelligence (Business Intelligence, BI) and artificial intelligence (Artificial Intelligence, AI). Due to the rapid growth of data volume in the Internet era, data infrastructure efforts and best practices are also evolving rapidly. In the past two years, the core system of the data infrastructure technology stack has become very stable, and supporting tools and applications are also growing rapidly.
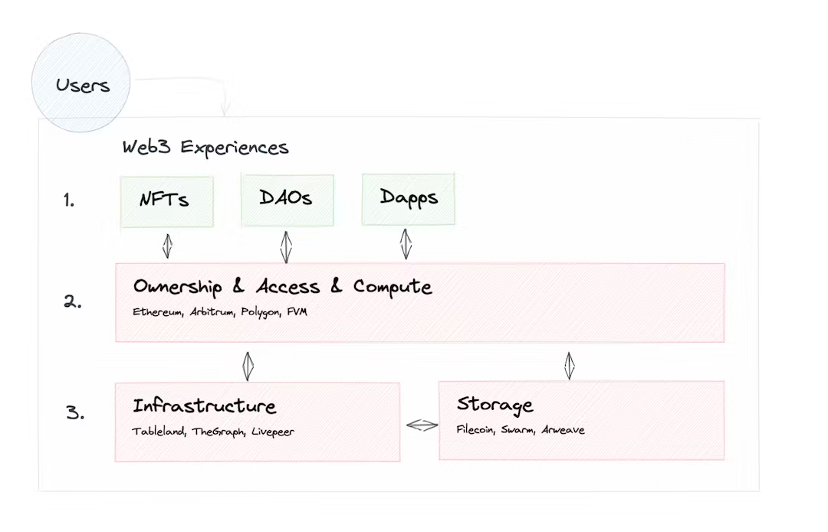
Web2 data infrastructure architecture
Cloud data warehouses (such as Snowflake, etc.) are growing rapidly, focusing mainly on SQL users and business intelligence user scenarios. Adoption of other technologies is also accelerating, customers of data lakes (such as Databricks) are growing at an unprecedented rate, and heterogeneity in the data technology stack will coexist.
Other core data systems, such as data acquisition and transformation, have proven equally durable. This is particularly evident in the modern world of data intelligence. Combinations of Fivetran and dbt (or similar technologies) can be found almost everywhere. But to a certain extent, this is also true in business systems. Combinations of Databricks/Spark, Confluent/Kafka, and Astronomer/Airflow are also starting to become de facto standards.
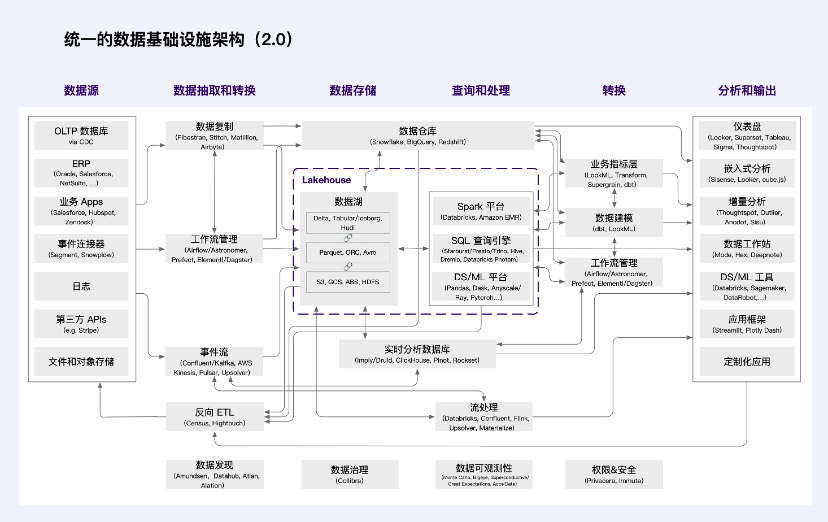
Source: a16z
in,
data sourceGenerate relevant business and business data on the terminal;
Data extraction and transformationResponsible for extracting data from business systems (E), transmitting to storage, aligning formats between data sources and destinations (L), and sending analyzed data back to business systems as required;
data storageStoring data in a format that can be queried and processed needs to be optimized towards low cost, high scalability and analytical workload;
Query and processingTranslate high-level programming languages (usually SQL, Python, or Java/Scala) into low-end data processing tasks. Use distributed computing to execute queries and data models based on stored data, including historical analysis (describing events that occurred in the past) and predictive analysis (describing events expected in the future);
ConvertTransform data into structures usable for analysis and manage processes and resources;
Analysis and outputIt provides analysts and data scientists with an interface that can trace insights and collaborate, display the results of data analysis to internal and external users, and embed data models into user-oriented applications.
With the rapid development of data ecology, the concept of data platform has emerged. From an industry perspective, the defining characteristic of a platform is the technological and economic interdependence of an influential platform provider and a large number of third-party developers. From a platform perspective, the data technology stack is divided into “front-end” and “back-end”.
The “backend” broadly includes data extraction, storage, processing, and transformation, has begun to consolidate around a small number of cloud service providers. As a result, customer data is collected in a standard set of systems, and vendors are investing heavily in making this data easily accessible to other developers. This is also a fundamental design principle of systems such as Databricks, and is implemented through systems such as SQL standards and custom computing APIs such as Snowflake.
Front-end engineers leverage this single point of integration to build a range of new applications.They rely on cleansed and integrated data in a data warehouse/lake without worrying about the underlying details of how it was generated. A single customer can build and purchase many applications on top of a core data system. We are even starting to see traditional enterprise systems, such as finance or product analytics, being restructured using warehouse-native architectures.
As the data technology stack gradually matures, data applications on the data platform also proliferate. As a result of standardization, adopting new data platforms has never been more important, and maintaining the platform accordingly has become extremely important. At scale, platforms can be extremely valuable. Today, there is intense competition among core data system vendors, not just for current business but for long-term platform status. The staggering valuations for data acquisition and transformation companies are easier to understand if you consider that data acquisition and transformation modules are core parts of emerging data platforms.
However, these technology stacks were formed under a data utilization approach dominated by large companies. As societys understanding of data deepens, people believe that data, like land, labor, capital, and technology, are production factors that can be allocated by the market. Data is one of the five major production factors, and what is reflected behind it is the asset value of data.
To realize the configuration of the data element market, the current technology stack is far from meeting the needs. In the Web3 field, which is closely integrated with blockchain technology, new data infrastructure is developing and evolving. These infrastructures will be embedded in modern data infrastructure architecture to realize data property rights definition, circulation transactions, income distribution and factor governance. These four areas are critical from a government regulatory perspective and therefore require special attention.
Web3 hybrid data infrastructure architecture
Inspired by a16z unified data infrastructure architecture (2.0), and integrating the understanding of Web3 infrastructure architecture, we propose the following Web3 hybrid data infrastructure architecture.
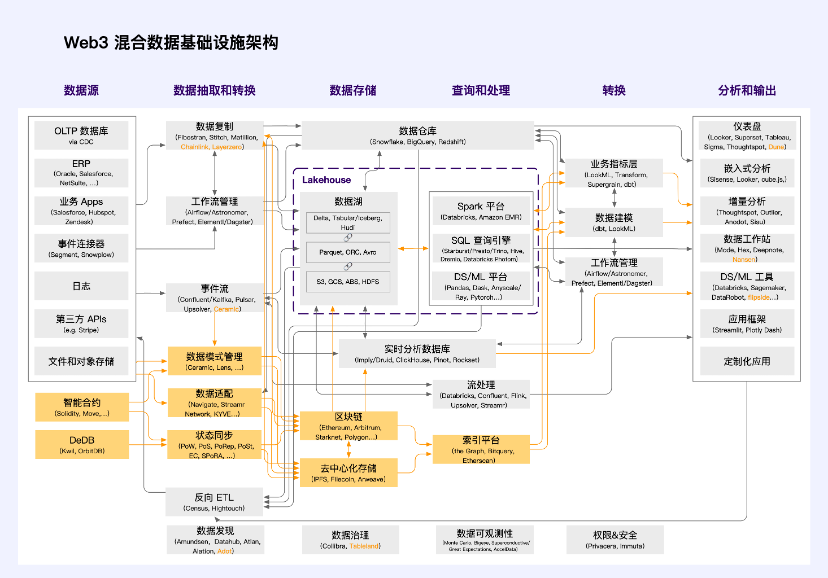
Orange is the technology stack unit unique to Web3. Since decentralized technology is still in its early stages of development, most applications in the Web3 field still use this hybrid data infrastructure architecture. The vast majority of applications are not truly superstructures. Superstructure has the characteristics of being unstoppable, free, valuable, scalable, permissionless, positive externalities and trustworthy neutrality. It exists as a public good in the digital world and is the public infrastructure of the Metaverse world. This requires a completely decentralized underlying architecture to support it.
Traditional data infrastructure architecture evolved based on enterprise business development. a16z summarizes it into two systems (analytical systems and business systems) and three scenarios (modern business intelligence, multi-model data processing, and artificial intelligence and machine learning). This is a summary from the perspective of the enterprise - data serves the development of the enterprise.
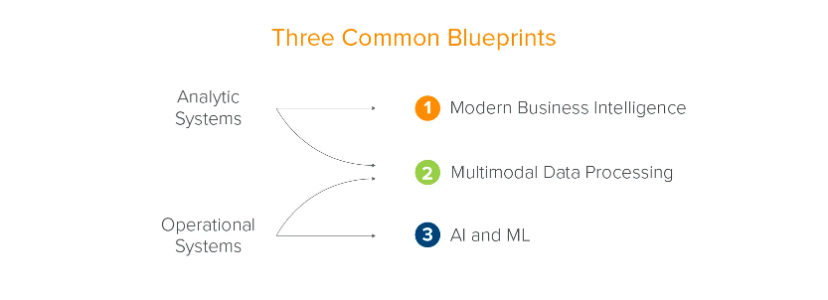
Source: a16z
However, it is not just businesses, society and individuals should benefit from the productivity gains brought by data elements. Countries around the world have introduced policies and regulations one after another, hoping to standardize the use of data from a regulatory level and promote the circulation of data. This includes various Data Banks commonly seen in Japan, data exchanges that have recently emerged in China, and trading platforms that have been widely used in Europe and the United States, such as BDEX (USA), Streamr (Switzerland), DAWEX (France), CARUSO, etc.
When data begins to define property rights, flow transactions, income distribution and governance, their systems and scenarios will not only empower the companys own decision-making and business development. These systems and scenarios either require the help of blockchain technology or rely heavily on policy supervision.
Web3 is the natural soil for the data factor market. It technically eliminates the possibility of cheating, greatly reduces regulatory pressure, and allows data to exist as a real production factor and be configured in a market-oriented manner.
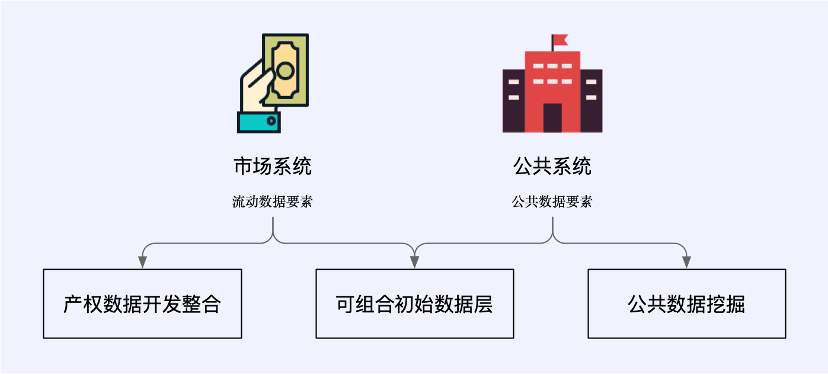
In the context of Web3, the new paradigm of data utilization includes market systems that carry flowing data elements and public systems that manage public data elements. They cover three new data business scenarios: property rights data development integration, composable initial data layer, and public data mining.
Some of these scenarios are closely integrated with traditional data infrastructure and belong to the Web3 hybrid data infrastructure architecture; some are separated from the traditional architecture and are completely supported by new technologies native to Web3.
Web3 and the data economy
The data economic market is the key to configuring data elements, including the development and integration of product data and the initial data layer market with composability. In an efficient and compliant data economy market, the following points are very important:
Data property rightsIt is the key to protecting rights and interests and compliant use. It should be structurally allocated and disposed. At the same time, data use needs to confirm the authorization mechanism. Each participant should have relevant rights and interests.
circulation transactionIt requires integration on and off-site as well as compliance and efficiency. It should be based on the four principles of confirmable data sources, definable scope of use, traceable circulation processes, and preventable security risks.
income distribution systemNeed to be efficient and fair. In accordance with the principle of whoever invests, who contributes, who benefits, the government can also play a guiding and regulatory role in the distribution of income from data elements.
Factor governance is safe, controllable, flexible and inclusive.This requires innovating the government data governance mechanism, establishing a data element market credit system, and encouraging enterprises to actively participate in the construction of the data element market. Focusing on data sources, data property rights, data quality, data usage, etc., we need to promote data vendors and third-party professional service organizations. Data circulation transaction statement and commitment system.
The above principles are the basic principles for regulatory authorities to consider the data economy. In the three scenarios of property rights data development and integration, composable initial data layer and public data mining, we can think based on these principles. What infrastructure do we need to support it? What value can these infrastructures capture at what stages?
Scenario 1: Development and integration of property rights data
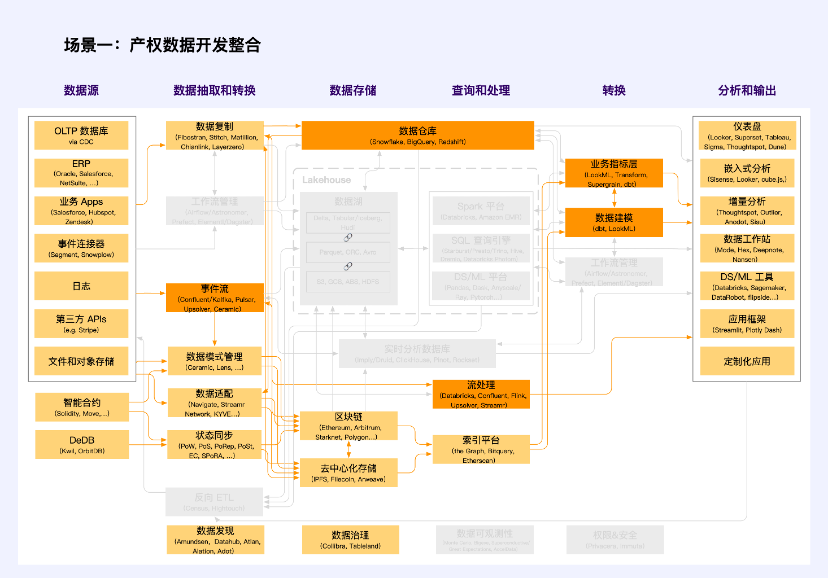
Note: Orange is the unit where Web2 and Web3 intersect
In the development process of property rights data, it is necessary to establish a classified and hierarchical rights confirmation and authorization mechanism to determine the ownership, use rights and operation rights of public data, enterprise data and personal data. According to the data source and generation characteristics, the property rights of the data are defined through data adaptation. Among them, typical projects include Navigate, Streamr Network and KYVE, etc. These projects achieve data quality standardization, data collection and interface standardization through technical means, confirm the rights of off-chain data in some form, and perform data classification and hierarchical authorization through smart contracts or internal logic systems.
The applicable data types in this scenario are non-public data, that is, enterprise data and personal data. The value of data elements should be activated in a market-oriented manner through “common use and shared benefits.”
Enterprise data includes data collected and processed by various market entities in production and business activities that does not involve personal information and public interests. Market entities have the rights to hold, use and obtain income in accordance with laws and regulations, as well as the right to receive reasonable returns for their labor and other factor contributions.
Personal data requires data processors to collect, hold, host and use data in accordance with laws and regulations within the scope of personal authorization. Use innovative technological means to promote the anonymization of personal information and ensure information security and personal privacy when using personal information. Explore a mechanism for trustees to represent personal interests and supervise the collection, processing, and use of personal information data by market entities. For special personal information data involving national security, relevant units can be authorized to use it in accordance with laws and regulations.
Scenario 2: Composable initial data layer
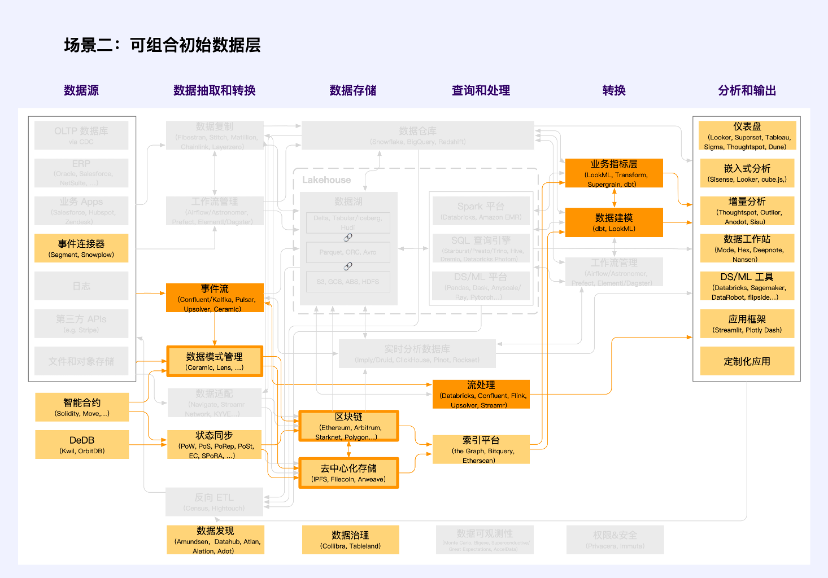
Note: Orange is the unit where Web2 and Web3 intersect
Composable initial data layers are an important part of the data economy market. Different from general property rights data, the most obvious feature of this part of data is the need to define the standard format of the data through data schema management. Different from the quality, collection and interface standardization of data adaptation, the emphasis here is on the standardization of data patterns, including standard data formats and standard data models. Ceramic and Lens are pioneers in this field. They ensure standard modes for off-chain (decentralized storage) and on-chain data respectively, making data composable.
Built on top of these data schema management tools is a composable initial data layer, often called a data layer, such as Cyberconnect, KNN 3, etc.
The composable initial data layer rarely involves the Web2 technology stack, but the hot data reading tool based on Ceramic breaks this, which will be a very critical breakthrough. Many similar data do not need to be stored on the blockchain, and are difficult to store on the blockchain, but they need to be stored on a decentralized network, such as users posts, likes and comments, etc. with high frequency and low value density. Data, Ceramic provides a storage paradigm for this type of data.
Composable initial data is a key scenario for innovation in the new era and an important symbol of the end of data hegemony and data monopoly. It can solve the cold start problem of start-ups in terms of data and combine mature data sets and new data sets, thereby enabling start-ups to build data competitive advantages faster. At the same time, start-ups are allowed to focus on incremental data value and data freshness, thereby gaining continued competitiveness for their innovative ideas. In this way, large amounts of data will not become a moat for large companies.
Scenario 3: Public data mining
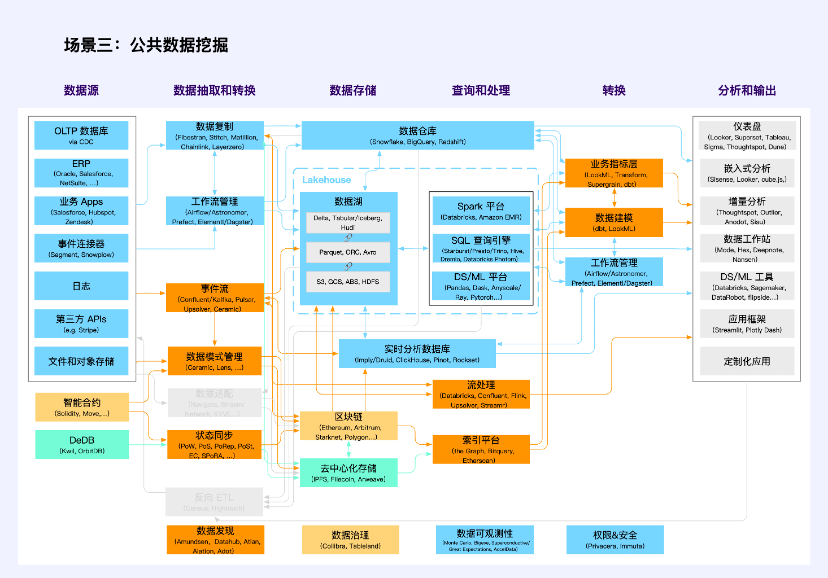
Note: Orange is a multi-category intersection unit
Public data mining is not a new application scenario, but in the Web3 technology stack, it has been highlighted as never before.
Traditional public data includes public data generated by party and government agencies, enterprises and institutions when they perform their duties in accordance with the law or provide public services. Regulatory agencies encourage the provision of such data to the society in the form of models, verification and other products and services in accordance with the requirements of the original data does not leave the domain and the data is available and invisible on the premise of protecting personal privacy and ensuring public safety. They use traditional technology stacks (blue and some orange, orange represents the intersection of multiple types of technology stacks, the same below).
In Web3, transaction data and activity data on the blockchain are another type of public data, which are characterized by available and visible. Therefore, they lack data privacy, data security and the ability to confirm authorization for data use, and are truly Public Goods. They adopt technology stacks (yellow and partially orange) with blockchain and smart contracts as the core.
The data on decentralized storage is mostly Web3 application data other than transactions. Currently, it is mainly file and object storage, and the corresponding technology stack is still immature (green and some orange). Common problems in the production and mining of such public data include hot and cold storage, indexing, state synchronization, permission management and calculation, etc.
Many data applications have emerged in this scenario, which are not data infrastructure but more data tools, including Nansen, Dune, NFTScan, 0x Scope and so on.
Case: Data Exchange
Data exchange refers to a platform for trading data as a commodity. They can be classified and compared based on transaction objects, pricing mechanisms, quality assurance, etc. DataStreamX, Dawex, and Ocean Protocol are several typical data exchanges on the market.
Ocean Protocol (200 million market cap) is an open source protocol designed to allow businesses and individuals to exchange and monetize data and data-based services. The protocol is based on the Ethereum blockchain and uses datatokens to control access to data sets. Data tokens are special ERC 20 tokens that represent ownership or usage rights of a data set or a data service. Users can purchase or earn data tokens to obtain the information they need.
The technical architecture of Ocean Protocol mainly includes the following parts:
Providers: refers to suppliers who provide data or data services. They can issue and sell their own data tokens through Ocean Protocol to earn income.
Consumers: refers to the demanders who purchase and use data or data services. They can purchase or earn the required data tokens through Ocean Protocol to gain access rights.
Marketplaces: refers to an open, transparent and fair data trading market provided by Ocean Protocol or a third party, which can connect providers and consumers around the world and provide data tokens in various types and fields. Markets can help organizations discover new business opportunities, increase revenue sources, optimize operational efficiency, and create more value.
Network: refers to a decentralized network layer provided by Ocean Protocol, which can support data exchange of different types and scales and ensure security, trustworthiness and transparency in the data transaction process. The network layer is a set of smart contracts used to register data, record ownership information, facilitate secure data exchange, and more.
Curator: refers to the role in an ecosystem responsible for screening, managing, and reviewing data sets. They are responsible for reviewing the source, content, format, and license information of the data set to ensure that the data set meets standards, and Can be trusted and used by other users.
Verifier: Refers to the role in an ecosystem responsible for verifying and reviewing data transactions and data services. They review and verify transactions between data service providers and consumers to ensure the quality, availability and quality of data services. accuracy.
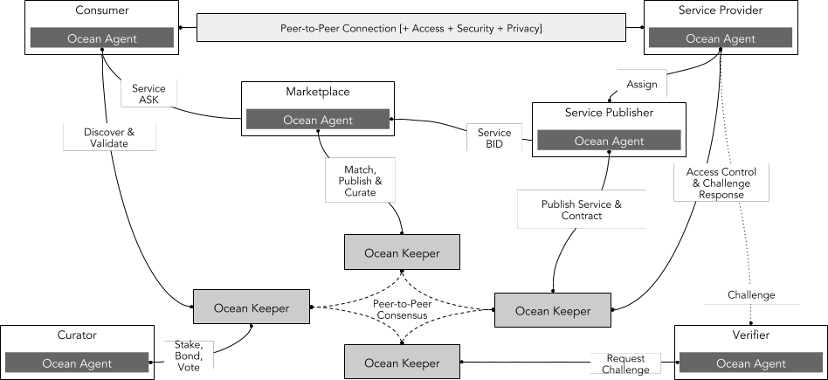
Source: Ocean Protocol
Data Services created by data providers include data, algorithms, computation, storage, analysis and curation. These components are tied to the services execution agreements (such as service level agreements), security calculations, access control, and permissions. Essentially, this is controlling access to a suite of cloud services through smart contracts.
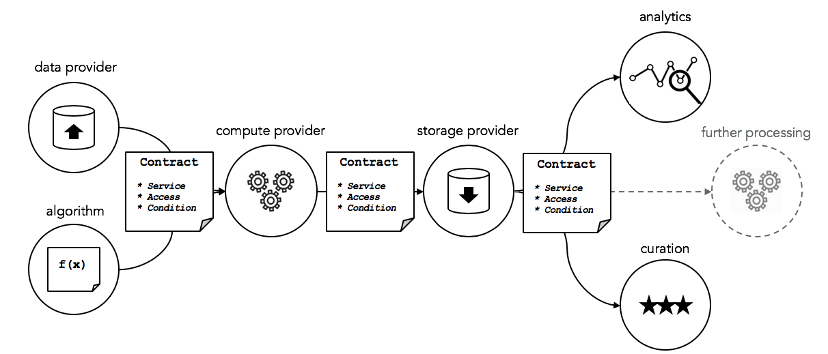
Source: Ocean Protocol
The advantage is,
Open source, flexible and extensible protocols help organizations and individuals create their own unique data ecosystems.
The decentralized network layer based on blockchain technology can ensure security, credibility and transparency in the data transaction process, while also protecting the privacy and rights of providers and consumers.
An open, transparent and fair data market can connect providers and consumers around the world and provide data tokens in multiple types and fields.
Ocean Protocol is a typical example of hybrid architecture. Its data can be stored in different places, including traditional cloud storage services, decentralized storage networks, or the data providers own servers. The protocol identifies and manages data ownership and access rights through data tokens and data NFTs. In addition, the protocol also provides compute-to-data functionality, allowing data consumers to analyze and process data without exposing the original data.
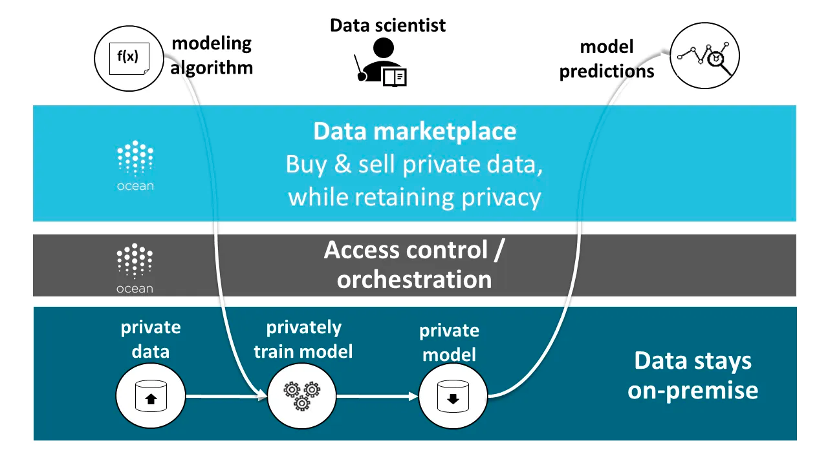
Source: Ocean Protocol
Although Ocean Protocol is one of the most complete data trading platforms on the market at this stage, it still faces many challenges:
Establish an effective trust mechanism, to increase trust between data providers and demanders and reduce transaction risks. For example, establish a data element market credit system to retain and verify certificates through the blockchain for the identification of untrustworthy behavior in data transactions, trustworthy incentives, untrustworthy punishment, credit repair, objection handling, etc.
Establish a reasonable pricing mechanism, to reflect the true value of data products, motivate data providers to provide high-quality data, and attract more demanders.
Establish a unified standard specification, to promote interoperability and compatibility between data of different formats, types, sources and uses.
Case: Data Model Market
In their Data Universe, Ceramic mentions the open data model marketplace they want to create, which can significantly boost productivity because data requires interoperability. Such a data model market is enabled by an emergent consensus on a data model, similar to the ERC contract standard in Ethereum, from which developers can choose as functional templates to have an application that conforms to all data of that data model. At this stage, such a market is not a trading market.
Regarding the data model, a simple example is that in a decentralized social network, the data model can be simplified to 4 parameters, which are:
PostList: stores the index of user posts
Post: stores a single post
Profile: stores user information
FollowList: stores the users follow list
So how can data models be created, shared, and reused on Ceramic, enabling cross-application data interoperability?
Ceramic provides a DataModels Registry, an open source, community-built repository of reusable application data models for Ceramic. This is where developers can openly register, discover and reuse existing data models - the foundation for customer operational applications built on shared data models. Currently, it is based on Github storage, and in the future it will be decentralized on Ceramic.
All data models added to the registry are automatically published to the npm plugin package of @datamodels. Any developer can use @datamodels/model-name to install one or more data models, making them available to store or retrieve data at runtime using any IDX client, including DID DataStore or Self.ID.
In addition, Ceramic has also built a DataModels forum based on Github. Each model in the data model registry has its own discussion thread on the forum, through which the community can comment and discuss. Its also a place for developers to post ideas for data models to get input from the community before adding them to the registry. Everything is currently in the early stages, and there are not many data models in the registry. The data models included in the registry should be evaluated by the community and are called CIP standards, just like Ethereums smart contract standards, which provide data Composability.
Case: Decentralized Data Warehouse
Space and Time is the first decentralized data warehouse connecting on-chain and off-chain data to support a new generation of smart contract use cases. Space and Time (SxT) has the most mature blockchain indexing service in the industry. The SxT data warehouse also uses a new cryptography called Proof of SQL™ to generate verifiable tamper-proof results, allowing developers to easily The SQL format joins trustless on-chain and off-chain data and loads results directly into smart contracts, powering sub-second queries and enterprise-grade analytics in a fully tamper-proof and blockchain-anchored manner.
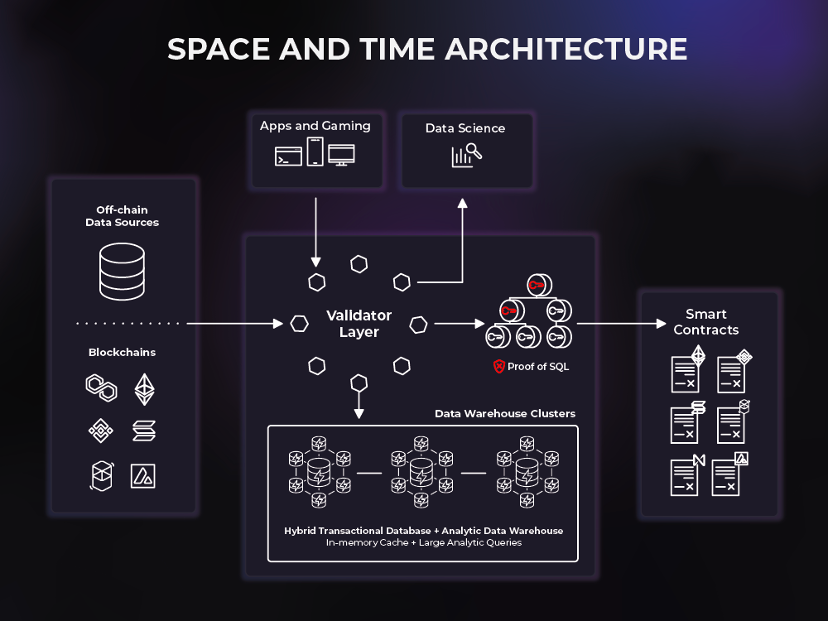
Space and Time is a two-layer network consisting of a validator layer and a data warehouse. The success of the SxT platform depends on the seamless interaction of validators and data warehouses to facilitate simple and secure querying of on-chain and off-chain data.
The data warehouse consists of database networks and computing clusters controlled by and routed to space and time validators. Space and time uses a very flexible warehousing solution: HTAP (Hybrid transactional/analytic processing).
Validator monitors, commands, and validates the services provided by these clusters, and then orchestrates the flow of data and queries between end users and the data warehouse cluster. Validators provide a means for data to enter a system (such as a blockchain index) and for data to exit a system (such as a smart contract).
Routing - enables transaction and query interaction with a decentralized data warehouse network
Streaming – Acts as a sink for high-volume customer streaming (event-driven) workloads
Consensus - Provides high-performance Byzantine fault tolerance for data entering and exiting the platform
Query Proof – Provide SQL proof to the platform
Table Anchor - provides storage proof to the platform by anchoring the table on the chain
Oracle - supports Web3 interactions, including smart contract event listening and cross-chain messaging/relaying
Security – prevents unauthenticated and unauthorized access to the platform
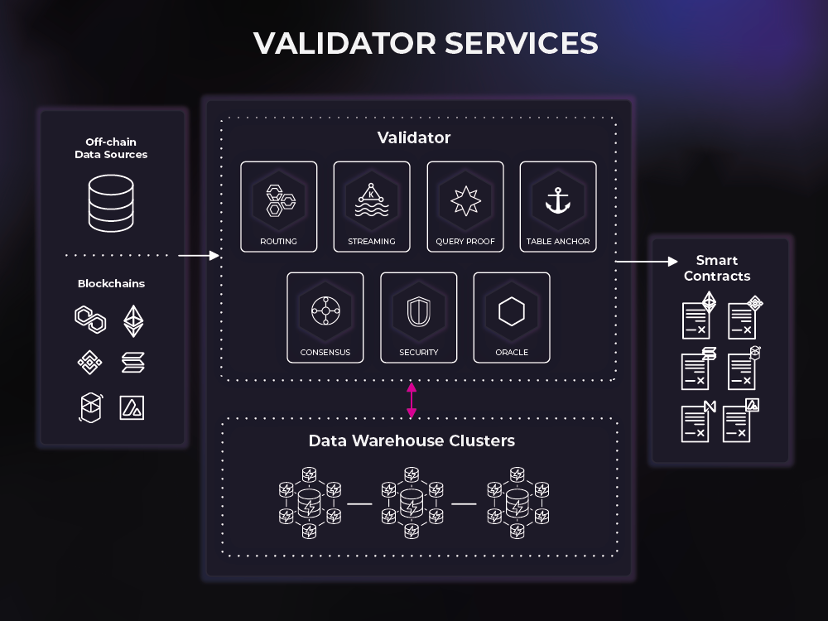
Space and Time as a platform is the worlds first decentralized data structure, opening up a powerful but underserved market: data sharing. Within the Space and Time platform, companies can share data freely and use smart contracts to trade the shared data. Additionally, data sets can be monetized in an aggregated manner through SQL proofs without giving consumers access to the raw data. Data consumers can trust that aggregations are accurate without seeing the data itself, so data providers no longer have to be data consumers. It is for this reason that the combination of SQL proofs and data structure schemas has the potential to democratize data operations as anyone can contribute in ingesting, transforming and serving data sets.
Web3 data governance and discovery
Currently, Web3 data infrastructure architecture lacks a practical and efficient data governance structure. However, a practical and efficient data governance infrastructure is crucial to configure the data elements of the relevant interests of each participant.
For the data source, it is necessary to have informed consent and the right to freely obtain, copy and transfer the data itself.
For data processors, they need to have the power to autonomously control, use data and obtain benefits.
For data derivatives, operating rights are required.
Currently, Web3 data governance capabilities are single, and assets and data (including Ceramic) can often only be controlled by controlling private keys, with almost no hierarchical classification configuration capabilities. Recently, the innovative mechanisms of Tableland, FEVM and Greenfield can achieve trustless governance of data to a certain extent. Traditional data governance tools such as Collibra can generally only be used within enterprises and only have platform-level trust. At the same time, non-decentralized technology also makes them unable to prevent personal evil and single points of failure. Through data governance tools such as Tableland, the security technology, standards and solutions required for the data circulation process can be guaranteed.
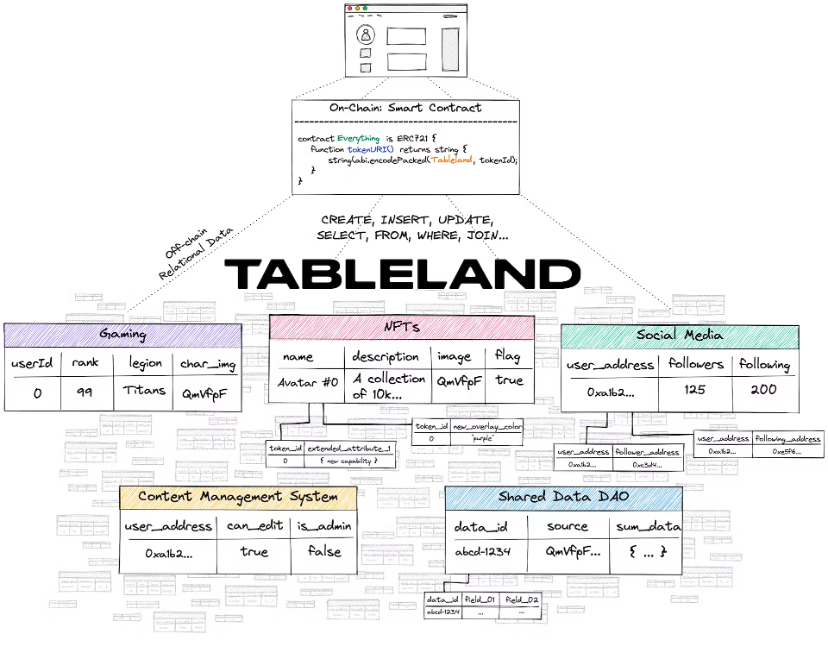
Case: Tableland
Tableland Network is a decentralized web3 protocol for structured relational data, starting with Ethereum (EVM) and EVM-compatible L2. With Tableland, it is now possible to implement traditional web2 relational database functionality by leveraging the blockchain layer for access control. However, Tableland is not a new database - it is just web3 native relational tables.
Tableland provides a new way for dapps to store relational data in the web3-native network without these trade-offs.
solution
With Tableland, metadata can be changed (using access control if needed), queried (using familiar SQL), and composable (with other tables on Tableland) - all in a completely decentralized manner.
Tableland breaks down traditional relational databases into two main components: an on-chain registry with access control logic (ACL) and an off-chain (decentralized) table. Every table in Tableland is initially minted as an ERC 721 token on a base EVM compatibility layer. Therefore, the on-chain table owner can set ACL permissions on the table, while the off-chain Tableland network manages the creation and subsequent changes to the table itself. Links between on-chain and off-chain are all handled at the contract level, which simply points to the Tableland network (using baseURI + tokenURI, much like many existing ERC 721 tokens that use an IPFS gateway or hosting server for metadata).
 Only people with the appropriate on-chain permissions can write to a specific table. However, table reads are not necessarily on-chain operations and can use the Tableland gateway; therefore, read queries are free and can come from simple front-end requests or even from other non-EVM blockchains. Now, in order to use Tableland, a table must first be created (i.e. minted on-chain as an ERC 721). The deployment address is initially set to the table owner, and this owner can set permissions for any other user who attempts to interact with the table to make changes. For example, the owner can set rules for who can update/insert/delete values, what data they can change, and even decide if they are willing to transfer ownership of the table to another party. Additionally, more complex queries can join data from multiple tables (owned or unowned) to create a fully dynamic and composable relational data layer.
Only people with the appropriate on-chain permissions can write to a specific table. However, table reads are not necessarily on-chain operations and can use the Tableland gateway; therefore, read queries are free and can come from simple front-end requests or even from other non-EVM blockchains. Now, in order to use Tableland, a table must first be created (i.e. minted on-chain as an ERC 721). The deployment address is initially set to the table owner, and this owner can set permissions for any other user who attempts to interact with the table to make changes. For example, the owner can set rules for who can update/insert/delete values, what data they can change, and even decide if they are willing to transfer ownership of the table to another party. Additionally, more complex queries can join data from multiple tables (owned or unowned) to create a fully dynamic and composable relational data layer.
Consider the following diagram, which summarizes a new users interaction with a table that has been deployed to Tableland by some dapp:
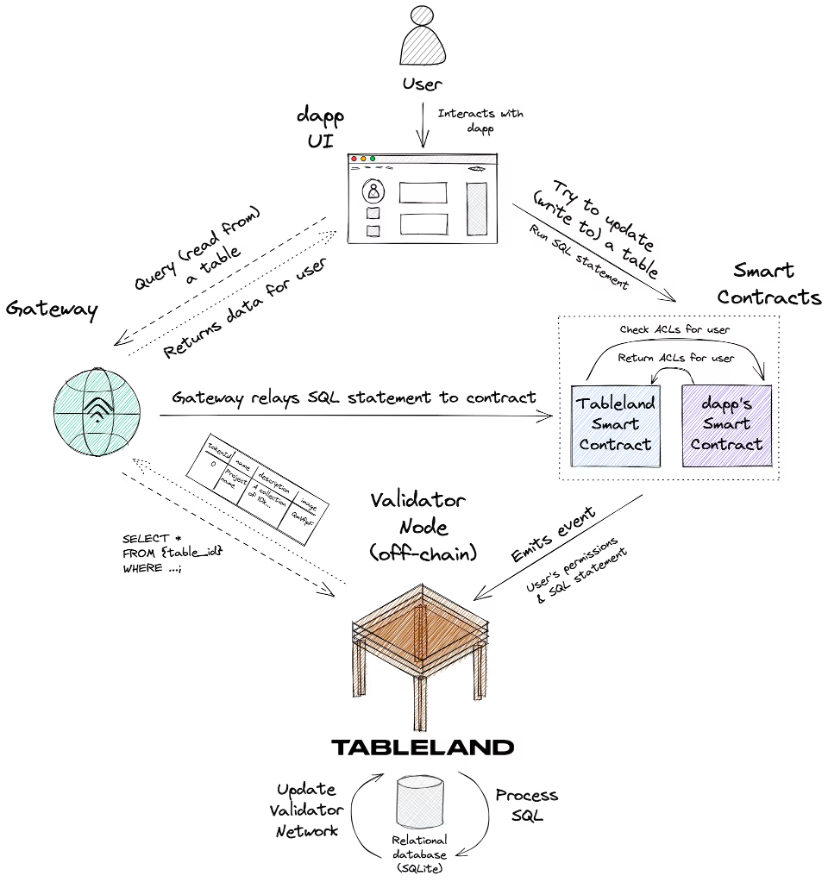
Here is the overall information flow:
1. A new user interacts with the dapps UI and attempts to update some information stored in a Tableland table.
2. The dapp calls the Tableland registration smart contract to run this SQL statement, and this contract checks the dapps smart contract, which contains a custom ACL that defines the permissions of this new user. There are a few points to note:
Custom ACLs in a dapps separate smart contract is a completely optional but advanced use case; developers do not need to implement a custom ACL and can use the default policy of the Tableland registry smart contract (only the owner has full permissions).
You can also use the gateway to write queries instead of directly calling the Tableland smart contract. There is always the option for dapps to call Tableland smart contracts directly, but any query can be sent through the gateway, which will relay the query to the smart contract itself in a subsidized manner.
3. The Tableland smart contract obtains the SQL statements and permissions of the user and incorporates these into emitted events that describe the SQL-based actions to be taken.
4. The Tableland Validator node listens for these events and then takes one of the following actions:
If the user has the correct permissions to write to the table, the validator will run the SQL command accordingly (for example, insert a new row into the table or update an existing value) and broadcast the confirmation data to the Tableland network.
If the user does not have the correct permissions, the Validator will not perform any operations on the table.
If the request is a simple read query, the appropriate data is returned; Tableland is a completely open relational data network where anyone can perform read-only queries on any table.
5. The dapp will be able to reflect any updates that occur on the Tableland network through the gateway.
(Usage scenario) What to avoid
Personally Identifiable Data - Tableland is an open network and anyone can read data from any table. Therefore, personal data should not be stored in Tableland.
High-frequency, sub-second writes – such as high-frequency trading bots.
Store every user interaction in the application - it may not make sense to save this data in a web3 table, such as keystrokes or clicks. Write frequency results in high cost.
Very large data sets - these should be avoided and are best handled via file storage, using solutions such as IPFS, Filecoin or Arweave. However, pointers to these locations and associated metadata are actually a good use case for Tableland tables.
Thoughts on value capture
Different units play an irreplaceable role in the entire data infrastructure architecture. The value captured is mainly reflected in market value/valuation and estimated income. The following conclusions can be drawn:
Data source is the module with the largest value capture in the entire architecture
Data replication, transformation, streaming and data warehousing are next
The analytical layer may have good cash flow, but there will be a cap on valuation
Simply put, the value capture of companies/projects on the left side of the entire structure diagram tends to be greater.
Industry concentration
According to incomplete statistical analysis, industry concentration can be judged as follows:
The two modules with the highest concentration in the industry are data storage and data query and processing.
The medium industry concentration is data extraction and transformation
The two modules with lower industry concentration are data source, analysis and output.
The concentration of data source, analysis and output industries is low. The initial judgment is that different business scenarios lead to the emergence of vertical scenario leaders in each business scenario, such as Oracle in the database field, Stripe in third-party services, and enterprise services. Salesforce, Tableau for dashboard analytics, Sisense for embedded analytics, and more.
As for the data extraction and conversion module with medium industry concentration, it is initially judged that the reason is due to the technology-oriented nature of the business attributes. The modular form of middleware also makes switching costs relatively low.
The data storage and data query and processing modules have the highest concentration in the industry. Preliminary judgment is that due to the single business scenario, high technical content, high startup costs and subsequent switching costs, the company/project has a strong first-mover advantage and has Network effects.
Data protocol business model and exit path
Judging from the establishment time and listing,
Most of the companies/projects established before 2010 were data source companies/projects. The mobile Internet had not yet emerged, and the amount of data was not very large. There were also some data storage and analysis output projects, mainly dashboards.
From 2010 to 2014, on the eve of the rise of the mobile Internet, data storage and query projects such as Snowflake and Databricks were born. Data extraction and conversion projects also began to appear. A set of mature big data management technology solutions gradually improved. During this period, There are a large number of analysis output type projects, mainly dashboard type.
From 2015 to 2020, query and processing projects have mushroomed, and a large number of data extraction and conversion projects have also emerged, allowing people to better leverage the power of big data.
Since 2020, newer real-time analysis databases and data lake solutions have emerged, such as Clickhouse and Tabular.
The improvement of infrastructure is the prerequisite for so-called mass adoption. During the period of large-scale application, there are still new opportunities, but these opportunities almost only belong to middleware, while the underlying data warehouse, data source and other solutions are almost a winner-take-all situation, unless there is technical substance. Sexual breakthrough, otherwise it will be difficult to grow.
Analytical output projects are opportunities for entrepreneurial projects in any period. But it is also constantly iterating and innovating, doing new things based on new scenarios. Tableau, which appeared before 2010, occupies most of the desktop dashboard analysis tools, and then new scenarios appeared, such as more professional-oriented DS/ML tools, A more comprehensive-oriented data workstation and a more SaaS-oriented embedded analysis, etc.
Look at the current data protocol of Web3 from this perspective:
The status of data source and storage projects is uncertain, but the leader is beginning to emerge. On-chain state storage is led by Ethereum (market value of 220 billion), while decentralized storage is led by Filecoin (market value of 2.3 billion) and Arweave (market value of 280 million). It is possible that There will be a sudden emergence of Greenfield. ——Highest value capture
There is still room for innovation in data extraction and conversion projects. The data oracle Chainlink (market value of 3.8 billion) is just the beginning. Ceramic, the event stream and stream processing infrastructure, and more projects will appear, but there is not much room. - Moderate value capture
For query and processing projects, the Graph (market value of 1.2 billion) has been able to meet most needs, and the type and number of projects have not yet reached the explosive stage. - Moderate value capture
Data analysis projects, mainly Nansen and Dune (valuation of 1 billion), require new scenarios to have new opportunities. NFTScan and NFTGo are somewhat similar to new scenarios, but they are only content updates, not the analysis logic/paradigm level. new needs. ——Mediocre value capture and considerable cash flow.
But Web3 is not a replica of Web2, nor is it entirely an evolution of Web2. Web3 has very native missions and scenarios, thus giving birth to business scenarios that are completely different from before (the first three scenarios are all abstractions that can be made currently).





