




Original author: Mike@Foresight Ventures
1. Concept introduction
Regarding the concept of co-processor, a very simple and easy-to-understand example is the relationship between a computer and a graphics card. The CPU can complete most tasks, but once a specific task is encountered, the graphics card needs the help because the CPU does not have enough computing power. For example, the machine Learning, graphics rendering, or running large-scale games. If we don’t want to drop frames or freeze when playing large-scale games, we definitely need a graphics card with good performance. In this scenario, the CPU is the processor and the graphics card is the co-processor. Mapping to the blockchain, the smart contract is the CPU and the ZK coprocessor is the GPU.
The key point is to hand over specific tasks to specific co-processors. Just like in a factory, the boss knows the steps of each link and can do it himself or teach employees the entire production process, but this is very inefficient and only He can produce one piece at a time, and only when one is finished can he produce the next one, so he hired a lot of specific employees. They each perform their duties and do the work they are good at in the production chain in their own workshops. The links in the chain can interact with each other. Communicate and coordinate but do not interfere with each others work. They only do what they are best at. Those with fast hands and strong physical strength can drive screws. Those who know how to operate machines can operate the machines. Those who know accounting can calculate production volume and costs. Asynchronous collaboration work to maximize work efficiency.
During the Industrial Revolution, capitalists had already discovered that this model could bring maximum production capacity to their factories. However, due to technology or other reasons, when one step in the production process encounters barriers, other steps may have to be outsourced. Specialized manufacturers do it. For example, for a company that produces mobile phones, the chips may be produced by other specialized chip companies. The mobile phone company is the central processor, and the chip company is the co-processor. Coprocessors can easily and asynchronously handle specific tasks that are too high-barrier and cumbersome for the central processor to handle on its own.

ZK coprocessor is relatively broad in a broad sense. Some projects call it their own coprocessor, and some call it ZKVM, but they all have the same idea: allowing smart contract developers to statelessly prove off-chain calculations on existing data. To put it simply, some on-chain calculation work is off-chain to reduce costs and increase efficiency. At the same time, ZK is used to ensure the reliability of calculations and protect the privacy of specific data. In the data-driven world of blockchain, this is especially important.
2. Why do we need ZK coprocessor?
One of the biggest bottlenecks facing smart contract developers remains the high costs associated with on-chain computation. Since Gas must be measured for each operation, the cost of complex application logic will quickly become too high to be executed, because although the archive nodes in the DA layer of the blockchain can indeed store historical data, this is why things like Dune Off-chain analysis applications such as Analytics, Nansen, 0x scope, and Etherscan can have so much data from the blockchain and can go back a long time, but it is not simple for smart contracts to access all this data. Able to easily access data stored in the virtual machine state, the latest block data, and other public smart contract data. For more data, smart contracts may have to spend a lot of effort to access:
Smart contracts in the Ethereum Virtual Machine (EVM) have access to the block header hashes of the most recent 256 blocks. These block headers contain all activity information in the blockchain up to the current block and are compressed into a 32-byte hash value using the Merkle tree and Keccak hashing algorithm.
Although the data is hash-packed, it can be decompressed—its just not easy. For example, if you want to leverage the most recent block header to trustlessly access specific data in the previous block, this involves a complex series of steps. First, you need to get the off-chain data from the archive node, and then build a Merkle tree and a validity proof of the block to verify the authenticity of the data on the blockchain. Subsequently, the EVM will process these validity proofs for verification and interpretation. This operation is not only cumbersome and time-consuming, but also very expensive in gas.
The fundamental reason for this challenge is that blockchain virtual machines (such as EVM) are not inherently suitable for handling large amounts of data and intensive computing tasks, such as the above-mentioned decompression work. The design focus of EVM is to execute smart contract code while ensuring security and decentralization, rather than processing large-scale data or performing complex computing tasks. Therefore, when it comes to tasks that require a lot of computing resources, it is often necessary to find other solutions, such as leveraging off-chain computing or other scaling technologies. At this time, the ZK coprocessor comes into being.

ZK rollups are actually the earliest ZK coprocessors, supporting the same type of calculations used on L1 at a larger scale and quantity. This processor is at the protocol level, and the ZK coprocessor we are talking about now is at the dapp level. The ZK coprocessor enhances the scalability of smart contracts by allowing them to trustlessly delegate historical on-chain data access and computation using ZK proofs. Rather than performing all operations in the EVM, developers can offload expensive operations to the ZK coprocessor and simply use the results on-chain. This provides a new way for smart contracts to scale by decoupling data access and computation from blockchain consensus.

The ZK coprocessor introduces a new design pattern for on-chain applications, eliminating the restriction that calculations must be completed in the blockchain virtual machine. This allows applications to access more data while controlling gas costs and run at greater scale than before, increasing smart contract scalability and efficiency without compromising decentralization and security.
3. Technical implementation
This part will use the Axiom architecture to explain how the zk coprocessor technically solves the problem. In fact, there are two cores: data capture and calculation. In these two processes, ZK ensures efficiency and privacy at the same time.
3.1 Data capture
One of the most important aspects of performing computations on the ZK coprocessor is ensuring that all input data is correctly accessed from the blockchain history. As mentioned earlier, this is actually quite difficult because smart contracts can only access the current blockchain state in their code, and even this access is the most expensive part of on-chain computation. This means that historical on-chain data such as transaction records or previous balances (interesting on-chain inputs in calculations) cannot be used natively by smart contracts to verify the results of the co-processor.
The ZK coprocessor solves this problem in three different ways, balancing cost, security, and development ease:
Store additional data in the blockchain state and use the EVM to store all data used on-chain by the read verification co-processor. This approach is quite expensive and cost-prohibitive for large amounts of data.
Trust Oracle or a network of signers to validate input data to the coprocessor. This requires the coprocessor user to trust Oracle or the multisig provider, which reduces security.
Use ZK proofs to check whether any on-chain data used in the co-processor has been committed in the blockchain history. Any block in the blockchain commits all past blocks and therefore any historical data, providing cryptographic guarantees of data validity and requiring no additional assumptions of trust from the user.
3.2 Calculation
Performing off-chain computations in the ZK coprocessor requires converting traditional computer programs into ZK circuits. Currently, all methods of achieving this have a huge impact on performance, with ZK proofs having an overhead ranging from 10,000 to 1,000,000 compared to native program execution. On the other hand, the computational model of ZK circuits differs from standard computer architectures (e.g. currently all variables must be encoded modulo a large cryptographic prime, and implementation may be non-deterministic), which means that developers are It is difficult to write them directly.
Therefore, the three main methods of specifying computations in ZK coprocessors are primarily trade-offs between performance, flexibility, and development ease:
Custom circuits: Developers write their own circuits for each application. This approach has the greatest performance potential, but requires significant developer effort.
eDSL/DSL for circuits: Developers write circuits for each application, but abstract away ZK-specific issues in an opinionated framework (similar to using PyTorch for neural networks). But the performance is slightly lower.
zkVM developers write circuits in existing virtual machines and verify their execution in ZK. This provides the simplest experience for developers when using existing VMs, but results in lower performance and flexibility due to the different computing models between VMs and ZK.
4. Application
ZK coprocessor has a wide range of applications. ZK coprocessor can theoretically cover all application scenarios that Dapp can cover. As long as it is a task related to data and computing, the ZK coprocessor can reduce costs, increase efficiency, and protect privacy. The following will start from different tracks and explore what the ZK processor can do at the application layer.
4.1 Defi
4.1.1 DEX
Take the hook in Uniswap V4 as an example:
Hook allows developers to perform specified operations at any key point in the entire life cycle of the liquidity pool - such as customizing liquidity pools, exchanges, fees before or after trading tokens, or before or after LP position changes How to interact with LP positions, for example:
Time Weighted Average Market Maker (TWAMM);
dynamic fees based on volatility or other inputs;
Chain price limit order;
Deposit out-of-scope liquidity into lending protocols;
Customized on-chain oracles, such as geometric mean oracles;
Automatically compound LP fees to LP positions;
Uniswap’s MEV profits are distributed to LP;
Loyalty discount programs for LPs or traders;
Simply put, it is a mechanism that allows developers to capture historical data on any chain and use it to customize the pool in Uniswap according to their own ideas. The emergence of Hook brings more composability and higher efficiency to transactions on the chain. capital efficiency. However, once the code logic that defines these becomes complicated, it will bring a huge gas burden to users and developers. Then zkcoprocessor comes in handy at this time, which can help save these gas fees and improve efficiency.
From a longer-term perspective, the ZK coprocessor will accelerate the integration of DEX and CEX. Since 2022, we have seen that DEX and CEX have become functionally consistent. All major CEXs are accepting this reality and adopting Web3 wallets, build EVM L2 and adopt existing infrastructure like Lightning Network or open source to embrace on-chain liquidity share. This phenomenon is inseparable from the boost of ZK co-processor. All functions that CEX can achieve, whether it is grid trading, follow-up, fast lending, or the use of user data, DEX can also be realized through ZK co-processor. , and the composability and freedom of Defi, as well as the transactions of small currencies on the chain, are difficult to achieve with traditional CEX. At the same time, ZK technology can also protect user privacy during execution.
4.1.2 Airdrop
If some projects want to conduct airdrops, they need smart contracts to query the historical activities of the address, but do not want to expose the users address information and execute it without introducing additional trust proof. For example, a project doing Defi lending wants to Through the interaction between the address and a series of lending protocols such as Aave, Compound, Fraxlend, and Spark as the standard for airdrops, the ZK coprocessors capture of historical data and privacy features can easily solve this need.
4.2 ZKML
Another exciting point of ZK coprocessor is in the area of machine learning. Since smart contracts can be given off-chain computing capabilities, high-efficiency machine learning on the chain will become possible. In fact, ZK coprocessor does It is also an indispensable part for the input and calculation of ZKML data. It can extract the input required for machine learning from the on-chain/off-chain historical data imported in the smart contract, and then write the calculation into a ZK circuit and throw it on the chain.
4.3 KYC
KYC is a big business, and now the web3 world is gradually embracing compliance. With the ZK coprocessor, you can make a smart contract verifiable proof by grabbing any off-chain data provided by the user, without the need for Exposing any unnecessary information of users, in fact, some projects are being implemented, such as Uniswaps KYC hook, which uses the ZK co-processor Pado to capture off-chain data without trust. Proof of assets, proof of academic qualifications, proof of travel, proof of driving, proof of law enforcement, proof of players, proof of transactions... All historical behaviors on and off the chain can even be packaged into a complete identity, and can be written with strong credibility. ZK proves being on-chain while protecting user privacy.
4.4 Social
The speculative attribute of Friend.tech is actually stronger than the social attribute. The core lies in its bonding curve. Is it possible to add a hook to the bonding curve of friend.tech so that users can customize the direction of the bonding curve, such as implementing After the craze for trading keys ends and speculators leave, the bonding curve will be smoothed, the entry barrier for real fans will be lowered, and real private domain traffic will grow. Or let the smart contract obtain the users on-chain/off-chain social graph, and be able to follow your friends on different social Dapps with one click. Or you can establish a private club on the chain, such as Degen club, and only addresses that meet the historical gas consumption conditions can enter, etc.
4.5 Gaming
In traditional Web2 games, user data is a very important parameter. Purchasing behavior, game style and contribution can make the game better operated and provide a better user experience, such as the ELO matching mechanism in MOBA games. The frequency of purchasing skins, etc., but these data are difficult to capture by smart contracts on the blockchain, so they can only be replaced with centralized solutions or simply abandoned. But the emergence of ZK coprocessor makes decentralized solutions possible.
5. Project Party
There are already some outstanding players in this track. The ideas are actually similar. They generate ZK proof through storage proof or consensus and then throw it on the chain. However, each has its own advantages in technical features and implemented functions.
5.1 Axiom
Axiom, the leader in ZK (zero-knowledge) coprocessors, focuses on enabling smart contracts to have trustless access to the entire Ethereum history and any ZK verification computation. Developers can submit on-chain queries to Axiom, which then processes them via ZK verification and propagates the results back to the developer’s smart contract in a trustless manner. This enables developers to build richer on-chain applications without relying on additional trust assumptions.
To implement these queries, Axiom performs the following three steps:
read: Axiom leverages ZK proofs to trustlessly read data from block headers, status, transactions, and receipts of Ethereum’s historical blocks. Since all Ethereum on-chain data is encoded in these formats, Axiom is able to access everything that archive nodes are able to access. Axiom verifies all input data to the ZK coprocessor via ZK proofs of Merkle-Patricia triples and block header hash chains. While this approach is more difficult to develop, it provides the best security and cost for end users because it ensures that all results returned by Axiom are cryptographically equivalent to on-chain computations performed in the EVM.
calculate: After data is ingested, Axiom applies validated calculations on it. Developers can specify their calculation logic in the JavaScript front-end, and the validity of each calculation is verified in ZK proofs. Developers can visit AxiomREPL or view the documentation to learn about the available computing primitives. Axiom allows users to access on-chain data and specify their own calculations through eDSL. It also allows users to write their own circuits using the ZK circuit library.
verify: Axiom provides ZK validity proofs for each query result. These proofs ensure that (1) the input data was correctly extracted from the chain and (2) the calculations were applied correctly. These ZK proofs are verified on-chain in Axiom smart contracts, ensuring that the final results are reliably used in the user’s smart contract.
Because results are verified via ZK proofs, Axioms results are cryptographically as secure as Ethereums results. This approach makes no assumptions about cryptoeconomics, incentives, or game theory. Axiom believes this approach will provide the highest possible level of assurance for smart contract applications. The Axiom team worked closely with the Uniswap Foundation and received Uniswap Grants to build a trustless oracle on Uniswap.
5.2 Risc Zero
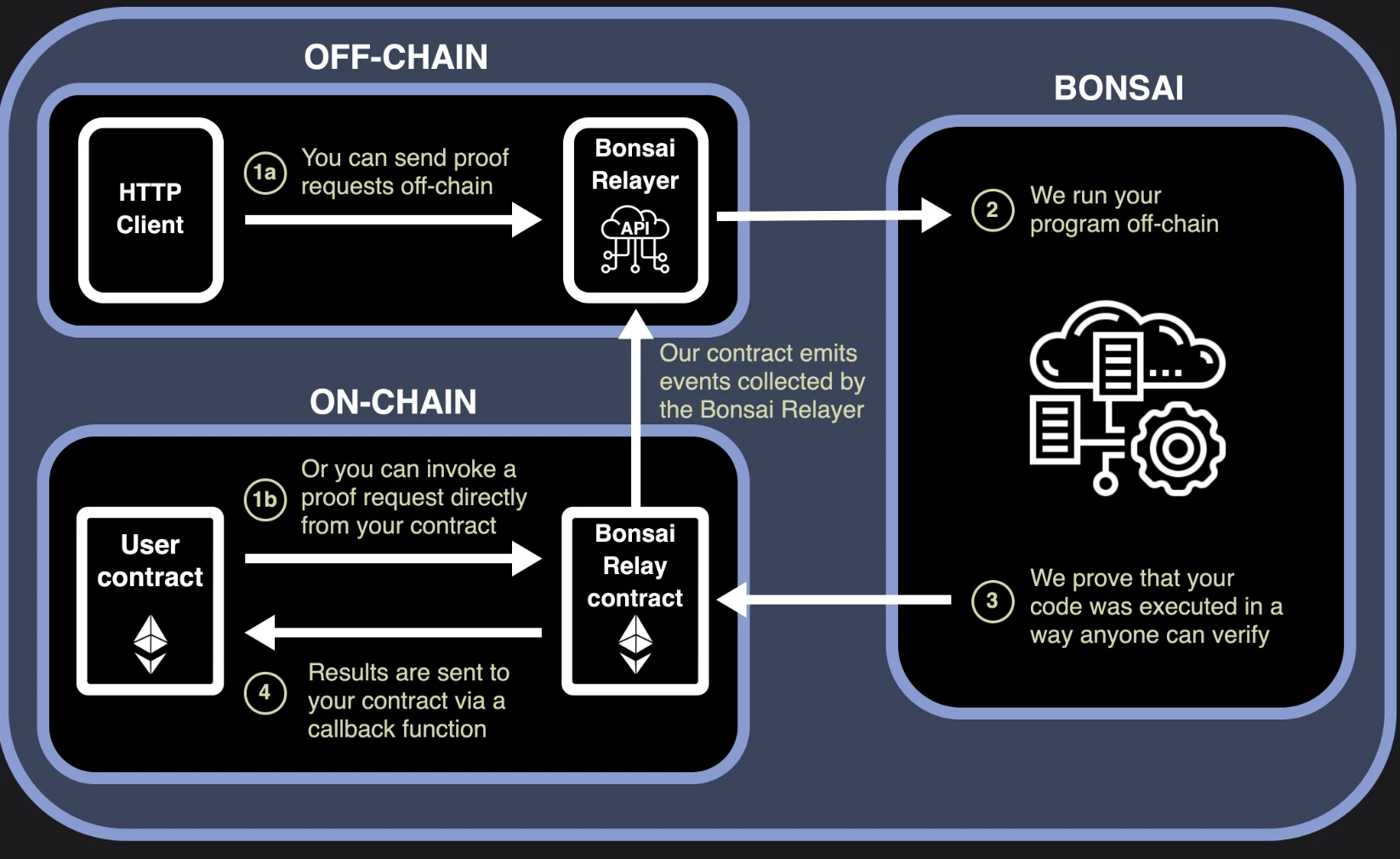
Bonsai:
In 2023, RISC Zero released Bonsai, a proof service that allows on-chain and off-chain applications to request and receive zkVM proofs. Bonsai is a universal zero-knowledge proof service that allows any chain, any protocol, and any application to leverage ZK proofs. It is highly parallelizable, programmable and high performance.
Bonsai enables you to integrate zero-knowledge proofs directly into any smart contract, without the need for custom circuitry. This allows ZK to be directly integrated into decentralized applications on any EVM chain, with the potential to support any other ecosystem.
zkVM is the foundation of Bonsai, enabling broad language compatibility, supporting provable Rust code, and potentially zero-knowledge provable code in any language that compiles to RISC-V (such as C++, Rust, Go, etc.). Through recursive proofs, custom circuit compilers, state continuation, and continued improvements to proof algorithms, Bonsai enables anyone to generate high-performance ZK proofs for a variety of applications.
RISC Zero zkVM:
First released in April 2022, RISC Zero zkVM can prove the correct execution of arbitrary code, allowing developers to build ZK applications in mature languages such as Rust and C++. This release is a major breakthrough in ZK software development: zkVM makes it possible to build ZK applications without building circuits and using custom languages.
By allowing developers to use Rust and leverage the maturity of the Rust ecosystem, zkVM enables developers to quickly build meaningful ZK applications without requiring a background in advanced mathematics or cryptography.
These applications include:
JSON: Prove the contents of an entry in a JSON file while keeping other data private.
Wheres Waldo: Proves that Waldo is present in the JPG file while keeping the rest of the image private.
ZK Checkmate: Prove you saw a move to checkmate without revealing the winning move.
ZK Proof of Exploit: Proof that you can exploit an Ethereum account without revealing the vulnerability.
ECDSA signature verification: Prove the validity of the ECDSA signature.
These examples are implemented by leveraging a mature software ecosystem: most Rust toolkits are available out of the box in Risc Zero zkVM. Being able to be compatible with Rust is a game-changer for the world of ZK software: projects that might take months or years to build on other platforms can be tackled with ease on RISC Zeros platform.
In addition to being easier to build, RISC Zero also delivers on performance. zkVM has GPU acceleration of CUDA and Metal, and realizes parallel proof of large programs through continuation.
Previously, Risc Zero received US$40 million in Series A financing from Galaxy Digital, IOSG, RockawayX, Maven 11, Fenbushi Capital, Delphi Digital, Algaé Ventures, IOBC and other institutions.
5.3 Brevis
Brevis, a subsidiary of Celer Network, focuses on capturing multi-chain historical data. It gives smart contracts the ability to read its complete historical data from any chain and perform comprehensive trustless customized calculations. Currently, it mainly supports Ethereum POS. Comos Tendermint and BSC.

Application interface:
Brevis’ current system supports efficient and concise ZK proofs, providing the following ZK-proven source chain information for decentralized application (dApp) contracts connected to the blockchain:
The block hash and associated status, transaction, and receipt roots of any block on the source chain.
Slot value and related metadata for any specific block, contract, slot on the source chain.
Transaction receipts and related metadata for any transaction on the source chain.
Transaction inputs and related metadata for any transaction on the source chain.
Any message sent by any entity on the source chain to any entity on the target chain.
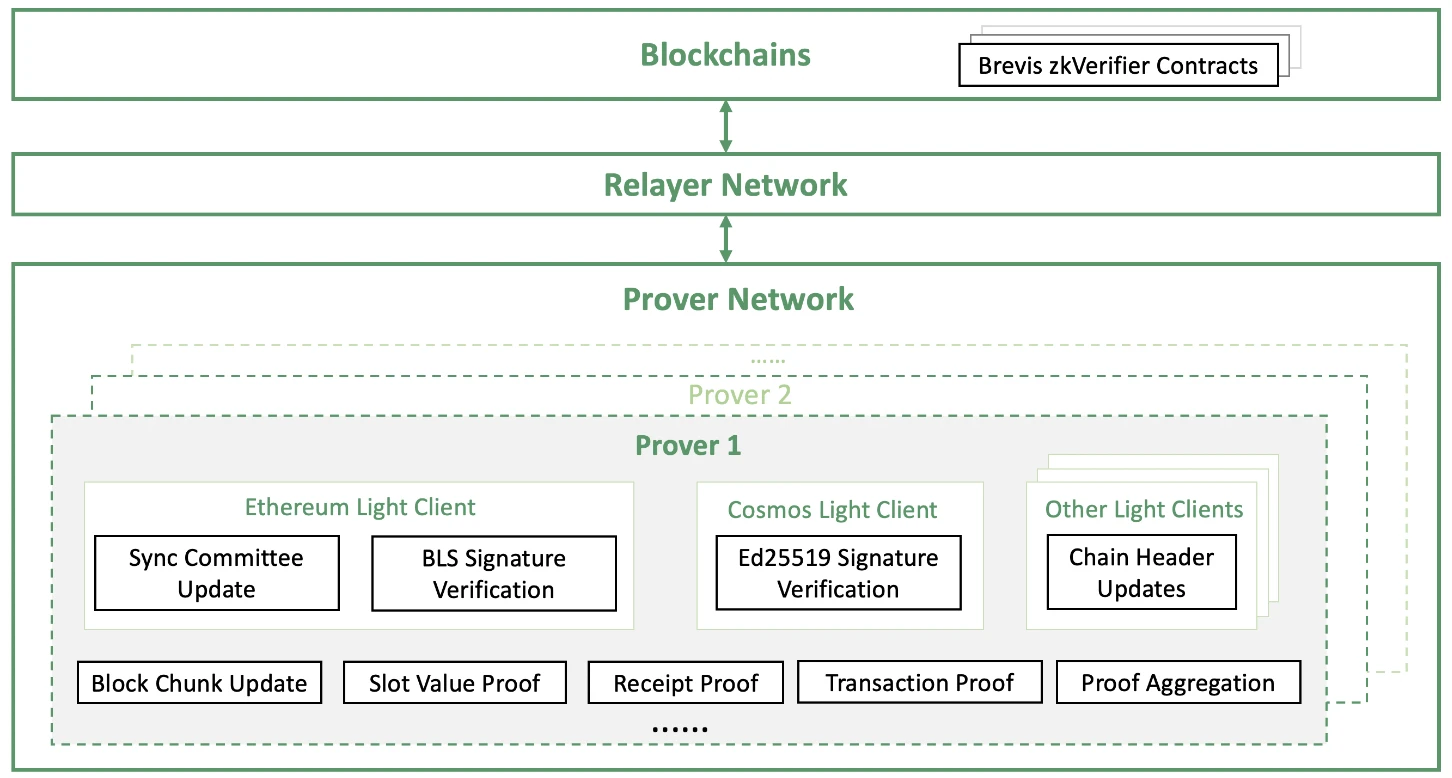
Architecture overview:
Brevis architecture consists of three main parts:
repeater network: It synchronizes block headers and on-chain information from different blockchains and forwards them to the validator network to generate validity proofs. It then submits the verified information and its associated proofs to the connected blockchain.
prover network: Implement circuits for each blockchain’s light client protocol, block updates, and generate proofs of requested slot values, transactions, receipts, and integrated application logic. To minimize proof time, cost, and on-chain verification costs, a network of provers can aggregate distributed proofs generated simultaneously. Additionally, it can leverage accelerators such as GPUs, FPGAs, and ASICs to increase efficiency.
Connecting validator contracts on the blockchain: Receive zk-verified data and related proofs generated by the validator network, and then feed the verified information back to the dApp contract.
This integrated architecture enables Brevis to ensure high efficiency and security when providing cross-chain data and computation, allowing dApp developers to fully utilize the potential of the blockchain. With this modular architecture, Brevis can provide fully trustless, flexible, and efficient data access and computing capabilities for on-chain smart contracts on all supported chains. This provides a completely new paradigm for dApp development. Brevis has a wide range of use cases, such as data-driven DeFi, zkBridges, on-chain user acquisition, zkDID, social account abstraction, etc., increasing data interoperability.
5.4 Langrange
Langrange and Brevis have a similar vision to enhance interoperability between multiple chains through the ZK Big Data Stack, which can create universal proof of state on all major blockchains. By integrating with the Langrange protocol, applications are able to submit aggregated proofs of multi-chain state, which can then be verified non-interactively by contracts on other chains.
Unlike traditional bridging and messaging protocols, the Langrange protocol does not rely on a specific group of nodes to deliver information. Instead, it leverages cryptography to coordinate proofs of cross-chain state in real time, including those submitted by untrusted users. Under this mechanism, even if the source of the information is not trustworthy, the application of encryption technology ensures the validity and security of the certificate.
The Langrange protocol will initially be compatible with all EVM-compatible L1 and L2 rollups. In addition, Langrange also plans to support non-EVM compatible chains in the near future, including but not limited to Solana, Sui, Aptos, and popular public chains based on the Cosmos SDK.
The differences between the Langrange protocol and traditional bridging and messaging protocols:
Traditional bridging and messaging protocols are primarily used to transfer assets or messages between a specific pair of chains. These protocols typically rely on a set of intermediate nodes to confirm the source chain’s latest block header on the target chain. This mode is mainly optimized for single-to-single chain relationships, based on the current status of the two chains. In contrast, the Langrange protocol provides a more general and flexible method of cross-chain interaction, enabling applications to interact within the broader blockchain ecosystem rather than being limited to a single chain-to-chain relationship.
The Langrange protocol specifically optimizes the mechanism for proving the state of inter-chain contracts, rather than just the transmission of information or assets. This feature allows the Langrange protocol to efficiently handle complex analysis involving current and historical contract states, which may span multiple chains. This capability enables Langrange to support a range of complex cross-chain application scenarios, such as calculating the moving average of asset prices on multi-chain decentralized exchanges (DEX), or analyzing the volatility of money market interest rates on multiple different chains.
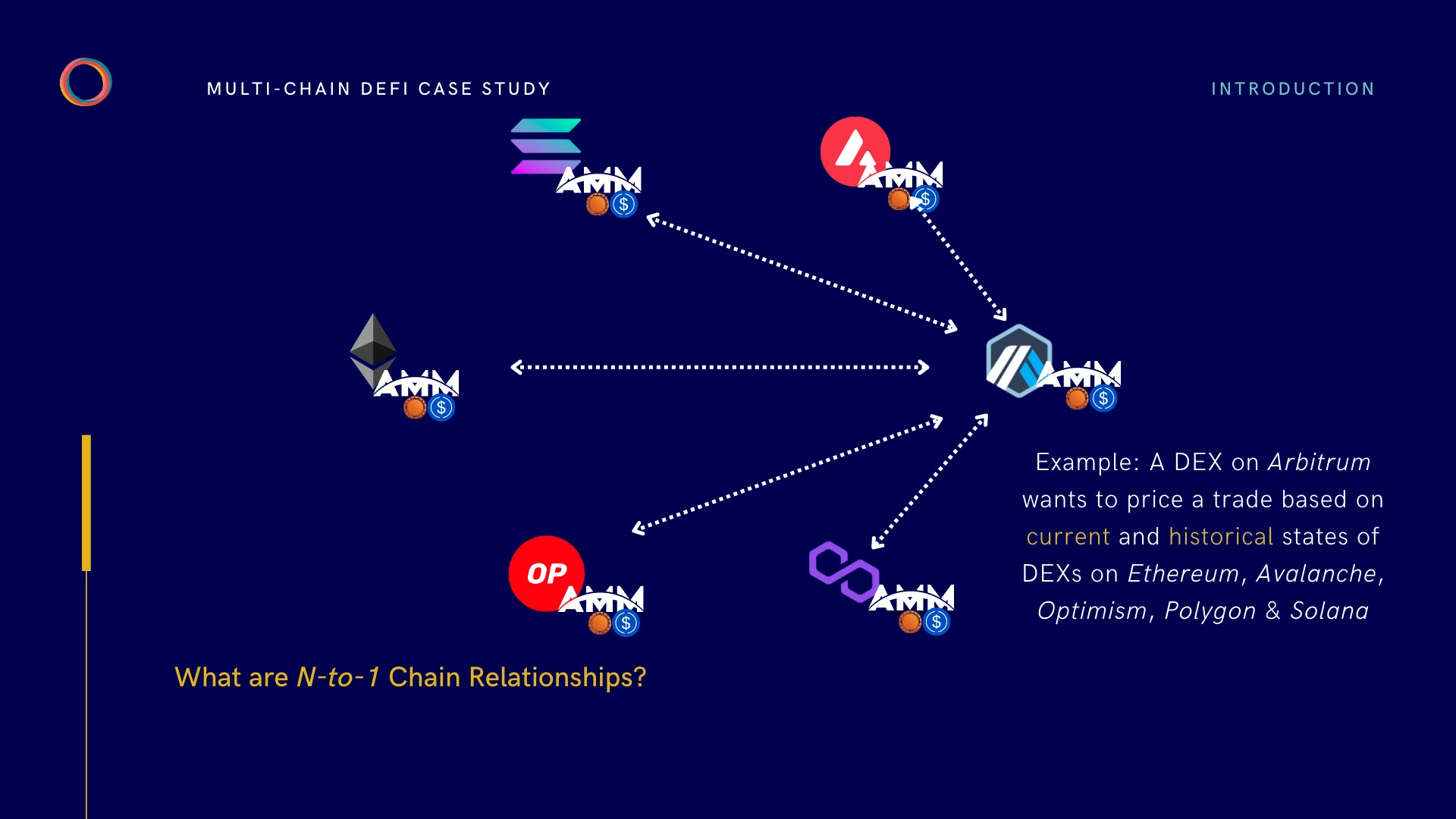
Therefore, Langrange state proofs can be viewed as optimizations for many-to-one (n-to-1) chain relations. In this cross-chain relationship, a decentralized application (DApp) on one chain relies on the aggregation of real-time and historical state data from multiple other chains (n). This feature greatly expands the functionality and efficiency of DApps, allowing them to aggregate and analyze data from multiple different blockchains to provide deeper, more comprehensive insights. This method is significantly different from the traditional single chain or one-to-one chain relationship, and provides a broader potential and application scope for blockchain applications.
Langrange has previously received investments from 1kx, Maven 11, Lattice, CMT Digital and gumi crypto.
5.5 Herodotus
Herodotus is designed to provide smart contracts with synchronous on-chain data access from other Ethereum layers. They believe that proof of storage can unify the state of multiple Rollups and even allow synchronous reads between Ethereum layers. To put it simply, it is data capture between the EVM main chain and rollup. Currently supports ETH mainnet, Starknet, Zksync, OP, Arbitrum and Polygon.
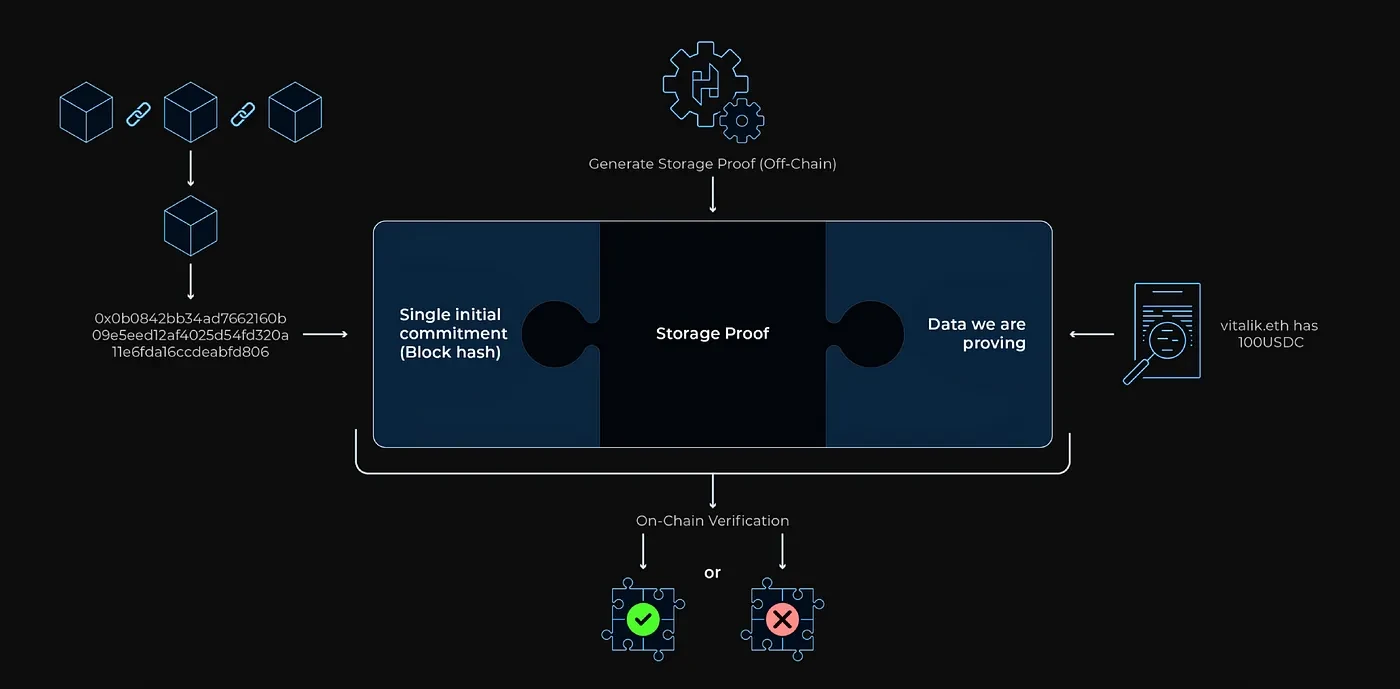
Storage Proof as defined by Herodotus is a composite proof that can be used to verify the validity of one or more elements in a large data set, such as the data in the entire Ethereum blockchain.
The storage proof generation process is roughly divided into three steps:
Step 1: Obtain the block header storage accumulator of verifiable commitments
This step is to obtain a commitment that we can verify. If the accumulator does not yet contain the latest block header we need to prove, we first need to prove chain continuity to ensure we cover the range of blocks containing our target data. For example, if the data we want to prove is in block 1, 000, 001, and the smart contract stored in the block header only covers block 1, 000, 000, then we need to update the header storage.
If the target block is already in the accumulator, you can proceed directly to the next step.
Step 2: Prove the existence of a specific account
This step requires generating a proof of inclusion from the State Trie consisting of all accounts in the Ethereum network. The state root is an important part of deriving the block commitment hash and is also part of the header storage. It is important to note that the block header hash in the accumulator may differ from the actual hash of the block because a different hashing method may have been used for efficiency.
Step 3: Prove specific data in the account tree
In this step, proofs of inclusion can be generated for data such as nonces, balances, storage roots, or codeHash. Each Ethereum account has a storage triplet (Merkle Patricia Tree), which is used to save the accounts storage data. If the data we want to prove is in the account store, then we need to generate additional proofs of inclusion for the specific data points in that store.
After generating all necessary inclusion proofs and computational proofs, a complete storage proof is formed. This proof is then sent to the chain, where it is verified against either a single initial commitment (such as a blockhash) or the MMR root of the header store. This process ensures the authenticity and integrity of the data while also maintaining the efficiency of the system.
Herodotus is already backed by Geometry, Fabric Ventures, Lambda Class, and Starkware.
5.6 HyperOracle
Hyper Oracle is specifically designed for programmable zero-knowledge oracles to keep blockchains secure and decentralized. Hyper Oracle makes on-chain data and on-chain equivalent computations practical, verifiable, and fast final through its zkGraph standard. It provides developers with a completely new way to interact with the blockchain.
Hyper Oracles zkOracle node is mainly composed of two components: zkPoS and zkWASM.
zkPoS: This component is responsible for obtaining the block header and data root of the Ethereum blockchain through zero-knowledge (zk) proof to ensure the correctness of the Ethereum consensus. zkPoS also acts as an external circuit to zkWASM.
zkWASM: It uses data obtained from zkPoS as key input for running zkGraphs. zkWASM is responsible for running custom data maps defined by zkGraphs and generating zero-knowledge proofs for these operations. Operators of zkOracle nodes can select the number of zkGraphs they want to run, which can be from one to all deployed zkGraphs. The process of generating zk proofs can be delegated to a distributed network of provers.
The output of zkOracle is off-chain data that developers can use through Hyper Oracles zkGraph standard. The data also comes with zk certificates to verify the validity of the data and calculations.
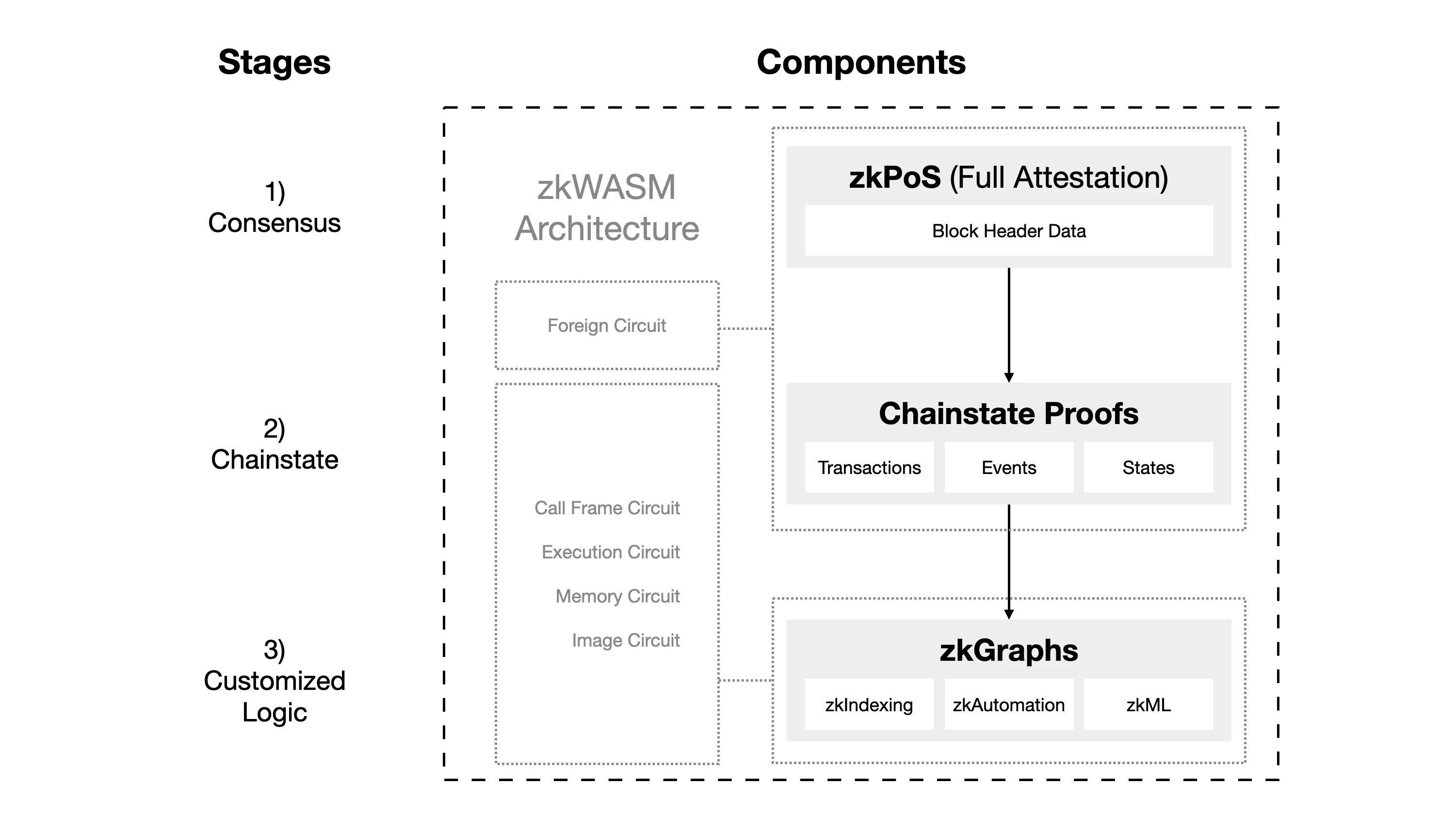
To maintain network security, a Hyper Oracle network requires only one zkOracle node. However, multiple zkOracle nodes can exist in the network, operating against zkPoS and per zkGraph. This allows zk proofs to be generated in parallel, significantly improving performance. Overall, Hyper Oracle provides developers with an efficient and secure blockchain interaction platform by combining advanced zk technology and flexible node architecture.
In January 2023, Hyper Oracle announced that it had received US$3 million in pre-seed financing jointly participated by Dao 5, Sequoia China, Foresight Ventures, and FutureMoney Group.
5.7 Pado
Pado is a relatively special existence among ZK co-processors. Other co-processors focus on capturing on-chain data, while Pado provides a path to capture off-chain data, aiming to bring all Internet data into smart contracts. It replaces the function of the oracle to a certain extent while ensuring privacy and eliminating the need to trust external data sources.
5.8 Comparison between ZK coprocessor and oracle
Latency: The oracle is asynchronous, so the latency when accessing flat data is longer compared to the ZK coprocessor.
Cost: While many oracles do not require computational proofs and are therefore less expensive, they are less secure. Storing proofs is more expensive, but more secure.
Security: The maximum security of data transmission is capped by the security level of the oracle itself. In contrast, the ZK coprocessor matches the security of the chain. Additionally, oracles are vulnerable to manipulation attacks due to the use of off-chain proofs.
The following figure shows Pados workflow:
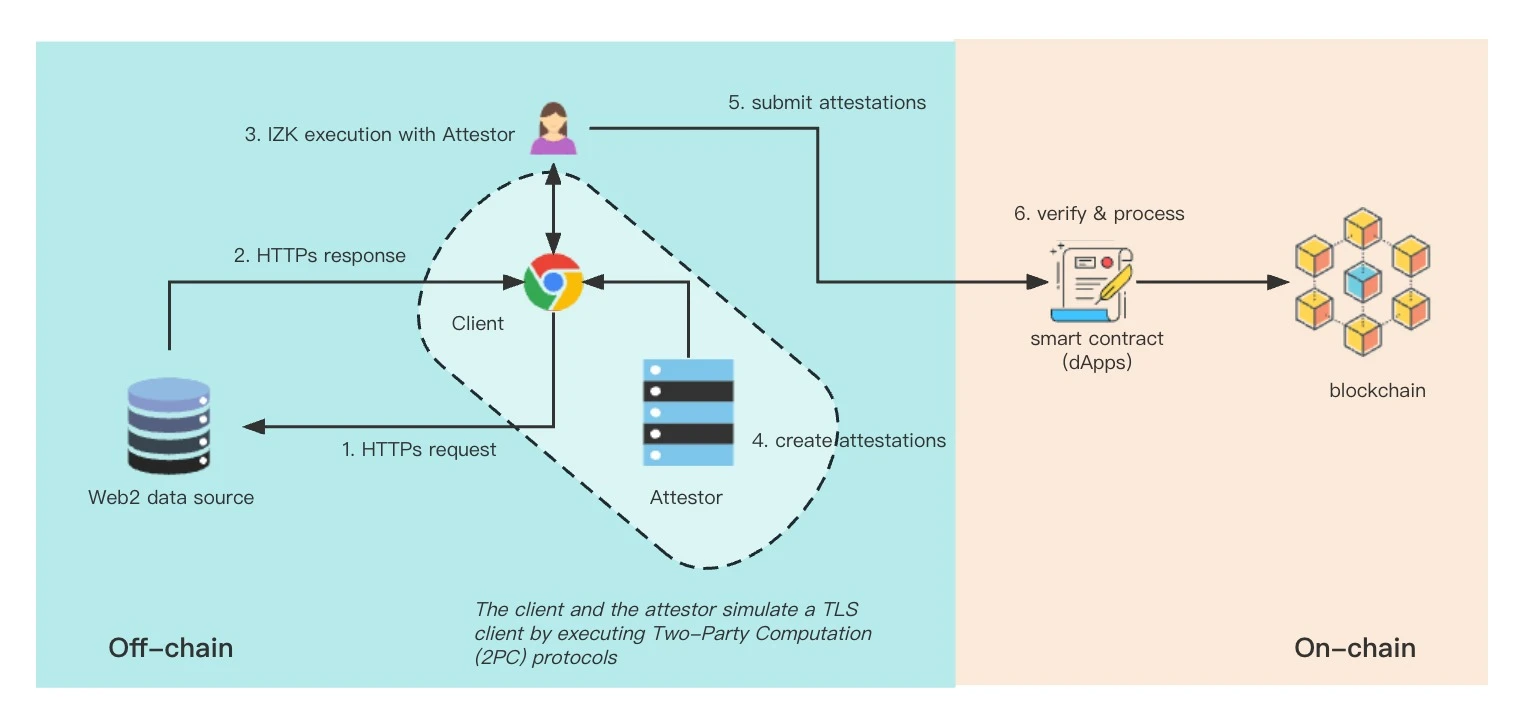
Pado uses crypto nodes as backend provers. In order to reduce trust assumptions, the Pado team will adopt an evolutionary strategy and gradually improve the decentralization of the prover service. The prover actively participates in the user data retrieval and sharing process while proving the authenticity of user data obtained from network data sources. Uniquely, Pado leverages MPC-TLS (Transport Layer Secure Multi-Party Computation) and IZK (Interactive Zero-Knowledge Proof) to enable provers to"blind"prove the data. This means that validators cannot see any original data, including public and private user information. However, the verifier can still ensure the origin of any transmitted TLS data through cryptographic methods.
1. MPC-TLS: TLS is a security protocol used to protect the privacy and data integrity of Internet communications. When you visit a website and see the lock icon and https on the URL, it means your visit is secured via TLS. MPC-TLS mimics the functionality of a TLS client, enabling Pados authenticator to work with the TLS client to perform the following tasks:
Establish a TLS connection, including calculating the master key, session key, authentication information, etc.
Execute queries over a TLS channel, including generating encrypted requests and decrypting server responses.
It is important to note that these TLS-related operations are performed between the client and the verifier via the Two-Party Computation (2 PC) protocol. The design of MPC-TLS relies on some encryption technologies, such as obfuscation circuit (GC), forget transmission (OT), IZK, etc.
2. IZK: Interactive zero-knowledge proof is a zero-knowledge proof in which the prover and the verifier can interact. In the IZK protocol, the verifiers outcome is to accept or reject the provers claim. Compared with simple NIZKs (such as zk-STARKs or zk-SNARKs), the IZK protocol has several advantages, such as high scalability to large claims, low computational cost, no need for trusted setup, and minimized memory usage.
Pado is actively developing Uniswap’s kyc hook, seeking more data on-chain application scenarios, and was selected into the first batch of Consensys Fellowship program.
6. Future Outlook
ZK coprocessor allows the blockchain to capture more data and obtain off-chain computing resources at a lower cost without harming decentralization. At the same time, it decouples the workflow of smart contracts and increases Scalability and efficiency.
From the demand side alone, ZK coprocessor is a necessity. From the perspective of the DEX track alone, this hook has great potential and can do many things. If sushiswap does not have hooks, it will not be able to compete with uniswap, and it will be severely criticized. It will be eliminated soon. If zkcoprocessor is not used for hooks, gas will be very expensive for developers and users, because hooks introduce new logic and make smart contracts more complex, which is counterproductive. So currently, using zk coprocessor is the best solution. Whether from the perspective of data capture or calculation, several methods have different advantages and disadvantages. The coprocessor suitable for specific functions is a good coprocessor. The on-chain verifiable computing market has broad prospects and will reflect new value in more fields.
In the future development of blockchain, it has the potential to break the traditional data barriers of web2. Information will no longer be isolated islands and achieve stronger interoperability. ZK co-processors will become powerful middleware to ensure security. , privacy and trust-free conditions to reduce costs and increase efficiency for data capture, calculation, and verification of smart contracts, liberate the data network, open up more possibilities, and become the infrastructure for real intent applications and on-chain AI Agents. Only if you cant think of it, you cant do it.

Imagine a scenario in the future: using ZK’s high reliability and privacy for data verification, online ride-hailing drivers can build an aggregation network in addition to their own platforms. This data network can cover Uber, Lyft, Didi , bolt, etc., online ride-hailing drivers can provide data on their own platforms. You take a piece, I take a piece, and put it together on the blockchain. Slowly, a network independent of their own platform is established and aggregated. All driver data has become a large aggregator of online ride-hailing data, and at the same time, it can make drivers anonymous and not leak their privacy.
7. Index
https://blog.axiom.xyz/what-is-a-zk-coprocessor/
https://crypto.mirror.xyz/BFqUfBNVZrqYau3Vz9WJ-BACw5FT3W30iUX3mPlKxtA
https://dev.risczero.com/api
https://blog.uniswap.org/uniswap-v4
https://blog.celer.network/2023/03/21/brevis-a-zk-omnichain-data-attestation-platform/
https://lagrange-labs.gitbook.io/lagrange-labs/overview/what-is-the-lagrange-protocol
https://docs.herodotus.dev/herodotus-docs/
https://docs.padolabs.org/
Thanks to Yiping Lu for his suggestions and guidance on this article
About Foresight Ventures
Foresight Ventures is betting on the innovation process of cryptocurrency in the next few decades. It manages multiple funds: VC funds, secondary active management funds, multi-strategy FOF, and special purpose S fund Foresight Secondary Fund l. The total asset management scale exceeds 4 One hundred million U.S. dollars. Foresight Ventures adheres to the concept of Unique, Independent, Aggressive, Long-term and provides extensive support for projects through strong ecological power. Its team comes from senior people from top financial and technology companies including Sequoia China, CICC, Google, Bitmain and other top financial and technology companies.





