




Written by Geekcartel
As the AI narrative continues to heat up, more and more attention is focused on this track. Geekcartel has conducted an in-depth analysis of the technical logic, application scenarios and representative projects of the Web3-AI track to present you with a comprehensive overview and development trends of this field.
1. Web3-AI: Analysis of technical logic and emerging market opportunities
1.1 The integration logic of Web3 and AI: How to define the Web-AI track
In the past year, AI narratives have been extremely popular in the Web3 industry, and AI projects have sprung up like mushrooms after rain. Although there are many projects involving AI technology, some projects only use AI in certain parts of their products, and the underlying token economics have no substantial connection with AI products. Therefore, such projects are not included in the discussion of Web3-AI projects in this article.
This article focuses on projects that use blockchain to solve production relationship problems and AI to solve productivity problems. These projects provide AI products themselves and use the Web3 economic model as a production relationship tool. The two complement each other. We classify such projects as the Web3-AI track. In order to help readers better understand the Web3-AI track, Geekcartel will introduce the development process and challenges of AI, as well as how the combination of Web3 and AI can perfectly solve problems and create new application scenarios.
1.2 AI development process and challenges: from data collection to model reasoning
AI technology is a technology that allows computers to simulate, expand and enhance human intelligence. It enables computers to perform a variety of complex tasks, from language translation, image classification to face recognition, autonomous driving and other application scenarios. AI is changing the way we live and work.
The process of developing an AI model usually includes the following key steps: data collection and data preprocessing, model selection and tuning, model training and inference. For example, to develop a model to classify cat and dog images, you need:
Data collection and data preprocessing: Collect a dataset containing images of cats and dogs. You can use a public dataset or collect real data yourself. Then label each image with a category (cat or dog) to ensure that the label is accurate. Convert the images into a format that the model can recognize and divide the dataset into training, validation, and test sets.
Model selection and tuning: Choose a suitable model, such as a convolutional neural network (CNN), which is more suitable for image classification tasks. Tune the model parameters or architecture according to different requirements. Generally speaking, the network layer of the model can be adjusted according to the complexity of the AI task. In this simple classification example, a shallower network layer may be sufficient.
Model training: You can use GPU, TPU or high-performance computing cluster to train the model. The training time is affected by the complexity of the model and the computing power.
Model inference: The model training file is usually called the model weight. The inference process refers to the process of using the trained model to predict or classify new data. In this process, the test set or new data can be used to test the classification effect of the model. Usually, indicators such as accuracy, recall rate, and F1-score are used to evaluate the effectiveness of the model.
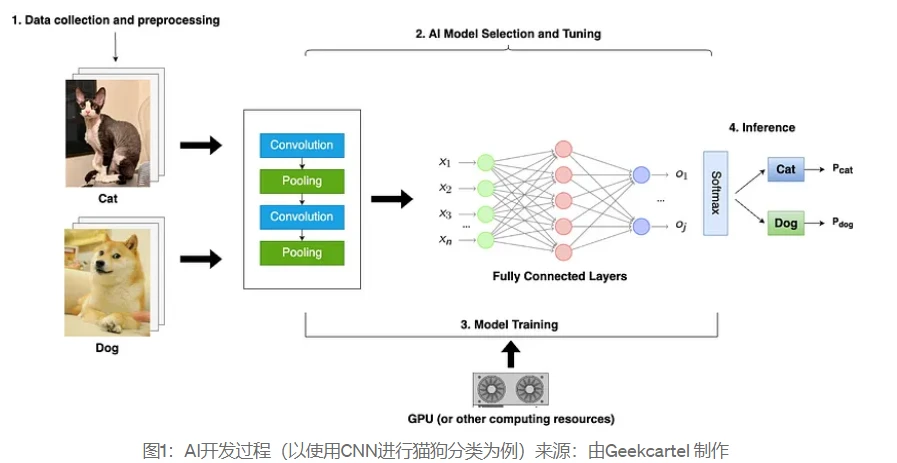
As shown in the figure, after data collection and data preprocessing, model selection and tuning, and training, the trained model is inferred on the test set to obtain the predicted value P (probability) of cats and dogs, that is, the probability that the model infers that it is a cat or a dog.
The trained AI model can be further integrated into various applications to perform different tasks. In this example, the AI model for cat and dog classification can be integrated into a mobile app, and users can upload pictures of cats or dogs to get classification results.
However, the centralized AI development process has some problems in the following scenarios:
User privacy: In centralized scenarios, the AI development process is usually opaque. User data may be stolen and used for AI training without knowing it.
Data source acquisition: When small teams or individuals acquire data in specific fields (such as medical data), they may face the limitation that the data is not open source.
Model selection and tuning: For small teams, it is difficult to obtain domain-specific model resources or cost a lot to tune models.
Obtaining computing power: For individual developers and small teams, the high cost of purchasing GPUs and renting cloud computing power can be a significant financial burden.
AI asset income: Data labelers often cannot earn income that matches their efforts, and the research results of AI developers are difficult to match with buyers in need.
The challenges existing in centralized AI scenarios can be solved by combining with Web3. As a new type of production relationship, Web3 is naturally adapted to AI, which represents a new type of productivity, thereby promoting the simultaneous advancement of technology and production capabilities.
1.3 Synergy between Web3 and AI: Role Transformation and Innovative Applications
The combination of Web3 and AI can enhance user sovereignty, provide users with an open AI collaboration platform, and transform users from AI users in the Web2 era to participants, creating AI that everyone can own. At the same time, the integration of the Web3 world and AI technology can also collide with more innovative application scenarios and gameplay.
Based on Web3 technology, the development and application of AI will usher in a brand new collaborative economic system. Peoples data privacy can be guaranteed, the data crowdsourcing model promotes the progress of AI models, many open source AI resources are available to users, and shared computing power can be obtained at a lower cost. With the help of decentralized collaborative crowdsourcing mechanisms and open AI markets, a fair income distribution system can be achieved, thereby motivating more people to promote the advancement of AI technology.
In Web3 scenarios, AI can have a positive impact on multiple tracks. For example, AI models can be integrated into smart contracts to improve work efficiency in different application scenarios, such as market analysis, security detection, social clustering and other functions. Generative AI not only allows users to experience the role of artist, such as using AI technology to create their own NFTs, but also to create rich and diverse game scenarios and interesting interactive experiences in GameFi. The rich infrastructure provides a smooth development experience, and both AI experts and novices who want to enter the field of AI can find a suitable entry in this world.
2. Web3-AI Ecosystem Project Map and Architecture Interpretation
We mainly studied 41 projects in the Web3-AI track and divided these projects into different levels. The division logic of each layer is shown in the figure below, including the infrastructure layer, the middle layer and the application layer, and each layer is divided into different sections. In the next chapter, we will conduct an in-depth analysis of some representative projects.
The infrastructure layer covers the computing resources and technical architecture that support the entire AI life cycle. The middle layer includes data management, model development, and verification reasoning services that connect infrastructure and applications. The application layer focuses on various applications and solutions directly facing users.
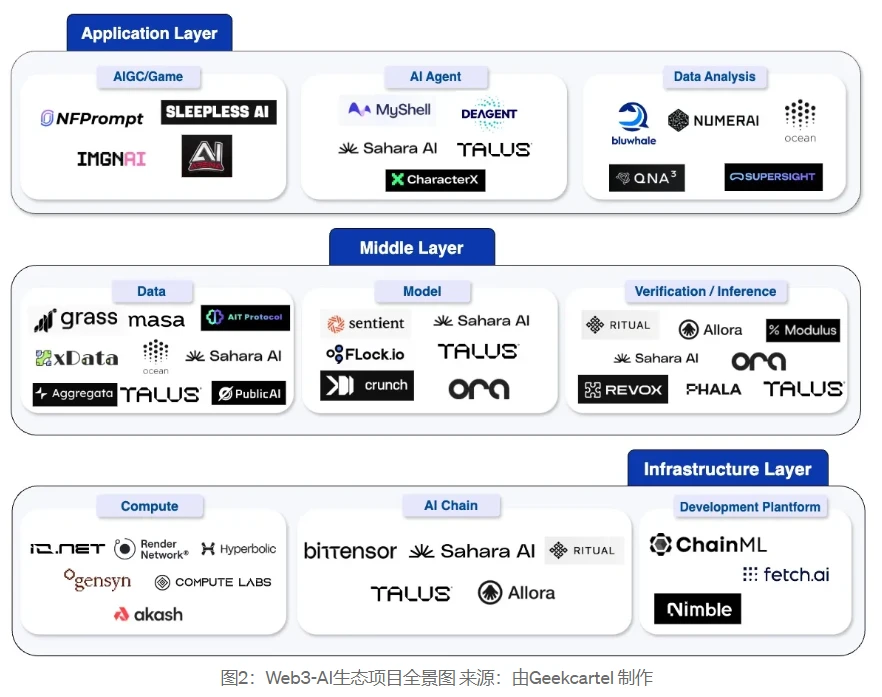
Infrastructure layer:
The infrastructure layer is the foundation of the AI life cycle. This article classifies computing power, AI Chain, and development platform as the infrastructure layer. It is the support of these infrastructures that enables the training and reasoning of AI models, and presents powerful and practical AI applications to users.
Decentralized computing network: It can provide distributed computing power for AI model training, ensuring efficient and economical use of computing resources. Some projects provide a decentralized computing power market, where users can rent computing power or share computing power at low cost to gain benefits. Representative projects include IO.NET and Hyperbolic. In addition, some projects have derived new ways of playing, such as Compute Labs, which proposed a tokenization protocol. Users can participate in computing power leasing in different ways to gain benefits by purchasing NFTs representing GPU entities.
AI Chain: Using blockchain as the foundation of the AI life cycle, it realizes seamless interaction between on-chain and off-chain AI resources and promotes the development of the industry ecosystem. The decentralized AI market on the chain can trade AI assets such as data, models, agents, etc., and provide AI development frameworks and supporting development tools, with representative projects such as Sahara AI. AI Chain can also promote the advancement of AI technology in different fields, such as Bittensor promoting subnet competition of different AI types through innovative subnet incentive mechanisms.
Development platform: Some projects provide AI agent development platforms and can also implement AI agent transactions, such as Fetch.ai and ChainML. One-stop tools help developers create, train and deploy AI models more conveniently, such as Nimble. These infrastructures promote the widespread application of AI technology in the Web3 ecosystem.
Middle layer:
This layer involves AI data, models, reasoning and verification, and the use of Web3 technology can achieve higher work efficiency.
Data: The quality and quantity of data are key factors affecting the effectiveness of model training. In the Web3 world, through crowdsourcing data and collaborative data processing, resource utilization can be optimized and data costs can be reduced. Users can have data autonomy and sell their own data under privacy protection to avoid data being stolen by bad businesses and making high profits. For data demanders, these platforms provide a wide range of choices and extremely low costs. Representative projects such as Grass use user bandwidth to crawl Web data, and xData collects media information through user-friendly plug-ins and supports users to upload tweet information.
In addition, some platforms allow domain experts or ordinary users to perform data preprocessing tasks, such as image annotation and data classification. These tasks may require professional knowledge of financial and legal tasks. Users can tokenize their skills to achieve collaborative crowdsourcing of data preprocessing. Representative AI markets such as Sahara AI have data tasks in different fields and can cover data scenarios in multiple fields; and AIT Protocolt annotates data through human-machine collaboration.
Model: In the AI development process mentioned above, different types of requirements need to match the appropriate model. Common models for image tasks include CNN and GAN. The Yolo series can be selected for object detection tasks. RNN, Transformer and other models are common for text tasks. Of course, there are also some specific or general large models. Tasks of different complexity require different model depths, and sometimes the model needs to be tuned.
Some projects support users to provide different types of models or collaboratively train models through crowdsourcing. For example, Sentient allows users to place trusted model data in the storage layer and distribution layer for model optimization through modular design. The development tools provided by Sahara AI have built-in advanced AI algorithms and computing frameworks, and have the ability of collaborative training.
Reasoning and verification: After the model is trained, a model weight file will be generated, which can be used directly for classification, prediction or other specific tasks. This process is called reasoning. The reasoning process is usually accompanied by a verification mechanism to verify whether the source of the reasoning model is correct, whether there is malicious behavior, etc. Web3 reasoning can usually be integrated into smart contracts, and reasoning is performed by calling the model. Common verification methods include ZKML, OPML and TEE technologies. Representative projects such as ORA on-chain AI oracle (OAO) introduced OPML as the verifiable layer of the AI oracle. ORAs official website also mentioned their research on ZKML and opp/ai (ZKML combined with OPML).
Application layer:
This layer mainly consists of user-oriented applications that combine AI with Web3 to create more interesting and innovative ways to play. This article mainly sorts out projects in the areas of AIGC (AI generated content), AI agents, and data analysis.
AIGC: AIGC can be extended to NFT, games and other tracks in Web3. Users can directly generate text, images and audio through prompts (prompts given by users), and even generate customized gameplay according to their preferences in games. NFT projects such as NFPrompt allow users to generate NFTs through AI and trade them in the market; games such as Sleepless allow users to shape the personality of their virtual partners through dialogue to match their preferences;
AI agent: refers to an artificial intelligence system that can perform tasks and make decisions autonomously. AI agents usually have the ability to perceive, reason, learn and act, and can perform complex tasks in various environments. Common AI agents include language translation, language learning, image-to-text, etc. In Web3 scenarios, they can generate trading robots, generate meme pictures, and perform on-chain security detection. For example, MyShell, as an AI agent platform, provides various types of agents, including educational learning, virtual companions, trading agents, etc., and provides user-friendly agent development tools, so you can build your own agents without code.
Data analysis: By integrating AI technology and databases in related fields, data analysis, judgment, and prediction can be achieved. In Web3, users can be assisted in investment decisions by analyzing market data and smart money trends. Token prediction is also a unique application scenario in Web3. Representative projects such as Ocean have officially set up long-term challenges for token prediction, and will also release data analysis tasks on different topics to encourage user participation.
3. Panoramic analysis of cutting-edge projects in the Web3-AI track
Some projects are exploring the possibility of combining Web3 with AI. GeekCartel will sort out the representative projects in this track to lead everyone to experience the charm of WEB3-AI and understand how the projects can achieve the integration of Web3 and AI and create new business models and economic value.
Sahara AI: An AI blockchain platform dedicated to the collaborative economy
Sahara AI is very competitive in the entire track. It is committed to building a comprehensive AI blockchain platform that covers a full range of AI resources such as AI data, models, agents, and computing power. The underlying architecture safeguards the collaborative economy of the platform. Through blockchain technology and unique privacy technology, decentralized ownership and governance of AI assets are ensured throughout the entire AI development cycle to achieve fair incentive distribution. The team has a deep background in AI and Web3, which enables it to perfectly integrate these two major fields. It has also been favored by top investors and has shown great potential in the track.
Sahara AI is not limited to Web3, because it breaks the unequal distribution of resources and opportunities in the traditional AI field. Through decentralization, key AI elements including computing power, models and data are no longer monopolized by centralized giants. Everyone has the opportunity to find a position that suits them in this ecosystem to benefit, and be inspired to be creative and work together.
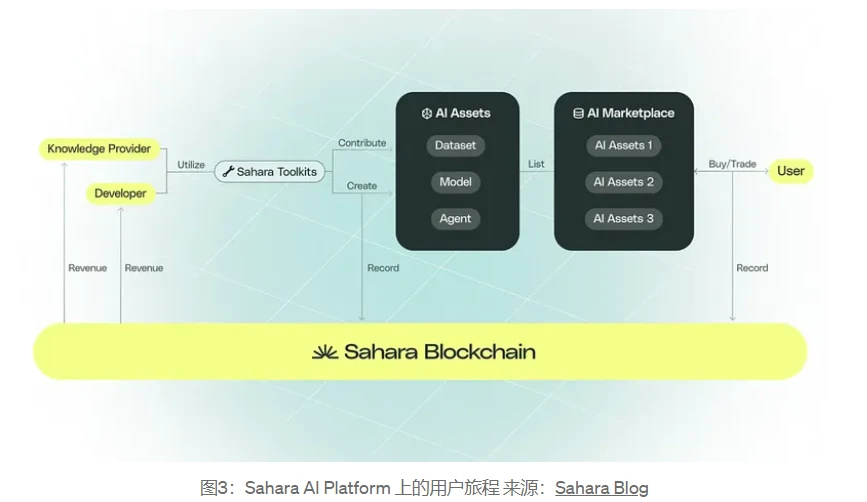
As shown in the figure, users can use the toolkit provided by Sahara AI to contribute or create their own data sets, models, AI agents and other assets, and place these assets in the AI market to make profits while also receiving platform incentives. Consumers can trade AI assets on demand. At the same time, all these transaction information will be recorded on the Sahara Chain. Blockchain technology and privacy protection measures ensure the tracking of contributions, the security of data and the fairness of rewards.
In the economic system of Sahara AI, in addition to the roles of developers, knowledge providers, and consumers mentioned above, users can also act as investors, providing funds and resources (GPU, cloud servers, RPC nodes, etc.) to support the development and deployment of AI assets, as operators to maintain the stability of the network, and as validators to maintain the security and integrity of the blockchain. Regardless of how users participate in the Sahara AI platform, they will receive rewards and income based on their contributions.
The Sahara AI blockchain platform is built on a layered architecture, with on-chain and off-chain infrastructure enabling users and developers to effectively contribute to and benefit from the entire AI development cycle. The architecture of the Sahara AI platform is divided into four layers:
Application Layer
The application layer serves as the user interface and primary interaction point, providing natively built-in toolkits and applications to enhance the user experience.
Functional components:
Sahara ID — ensures secure access to AI assets and tracks user contributions;
Sahara Vault — protects the privacy and security of AI assets from unauthorized access and potential threats;
Sahara Agent — has role alignment (interactions that match user behavior), lifelong learning, multimodal perception (can process multiple types of data), and multi-tool execution capabilities;
Interactive components:
Sahara Toolkit — enables technical and non-technical users to create and deploy AI assets;
Sahara AI Marketplace — For publishing, monetizing, and trading AI assets, with flexible licensing and multiple monetization options.
Transaction Layer
Sahara AIs transaction layer uses the Sahara blockchain, which is equipped with protocols for managing ownership, attribution, and AI-related transactions on the platform, and plays a key role in maintaining the sovereignty and provenance of AI assets. The Sahara blockchain integrates the innovative Sahara AI native precompilation (SAP) and Sahara blockchain protocol (SBP) to support basic tasks throughout the AI life cycle.
SAP is a built-in function at the native operation level of the blockchain, focusing on the AI training/reasoning process respectively. SAP helps to call, record and verify the off-chain AI training/reasoning process, ensure the credibility and reliability of the AI models developed within the Sahara AI platform, and guarantee the transparency, verifiability and traceability of all AI reasoning at the same time. At the same time, faster execution speed, lower computing overhead and gas cost can be achieved through SAP.
SBP implements AI-specific protocols through smart contracts to ensure that AI assets and computational results are handled transparently and reliably, including functions such as AI asset registration, licensing (access control), ownership, and attribution (contribution tracking).
Data Layer
Sahara AIs data layer is designed to optimize data management throughout the AI lifecycle. It acts as an important interface, connecting the execution layer to different data management mechanisms and seamlessly integrating on-chain and off-chain data sources.
Data component: includes on-chain and off-chain data. On-chain data includes metadata, ownership, commitments and certifications of AI assets, while data sets, AI models and supplementary information are stored off-chain.
Data Management: Sahara AI’s data management solution provides a set of security measures to ensure that data is protected both in transit and at rest through a unique encryption solution. Working with AI licensed SBPs to achieve strict access control and verifiability, while providing private domain storage, users’ sensitive data can achieve enhanced security features.
Execution Layer
The execution layer is the off-chain AI infrastructure of the Sahara AI platform, interacting seamlessly with the transaction layer and data layer to execute and manage protocols related to AI computations and functions. Depending on the execution task, it securely extracts data from the data layer and dynamically allocates computing resources for optimal performance. Complex AI operations are coordinated through a set of specially designed protocols that are designed to facilitate efficient interactions between various abstractions, and the underlying infrastructure is designed to support high-performance AI computing.
Infrastructure: Sahara AIs execution layer infrastructure is designed to support high-performance AI computing, with features such as fast and efficient, elastic and highly available. It ensures that the system remains stable and reliable under high traffic and failure conditions through efficient coordination of AI computing, automatic expansion mechanism and fault-tolerant design.
Abstractions: Core abstractions are the basic components that form the basis of AI operations on the Sahara AI platform, including abstractions of resources such as datasets, models, and computing resources; high-level abstractions are built on top of core abstractions, namely the execution interfaces behind Vaults and agents, which can realize higher-level functions.
Protocol: The abstract execution protocol is used to execute interactions with Vaults, interactions and coordination of agents, and collaborative computing. The collaborative computing protocol can realize joint AI model development and deployment among multiple participants, support computing resource contribution and model aggregation. The execution layer also includes a low computing cost technology module (PEFT), a privacy protection computing module, and a computing anti-fraud module.
The AI blockchain platform that Sahara AI is building is committed to realizing a comprehensive AI ecosystem. However, this grand vision will inevitably encounter many challenges in the process of realization, requiring strong technical and resource support and continuous optimization and iteration. If it can be successfully realized, it will become the mainstay supporting the Web3-AI field and is expected to become the ideal garden in the hearts of Web2-AI practitioners.
Team Information:
The Sahara AI team is composed of a group of outstanding and creative members. Co-founder Sean Ren is a professor at the University of Southern California and has won honors such as Samsungs annual AI researcher, MIT TR 35 under 35 innovator, and Forbes 30 under 30. Co-founder Tyler Zhou graduated from the University of California, Berkeley, has a deep understanding of Web3, and leads a global team of talents with experience in AI and Web3.
Since the creation of Sahara AI, the team has received millions of dollars in revenue from top companies including Microsoft, Amazon, MIT, Snapchat, and Character AI. Currently, Sahara AI is serving more than 30 corporate clients and has more than 200,000 AI trainers worldwide. The rapid growth of Sahara AI has enabled more and more participants to contribute and benefit from the sharing economy model.
Financing Information:
As of August this year, Sahara Labs has successfully raised $43 million. The latest round of financing was co-led by Pantera Capital, Binance Labs and Polychain Capital. In addition, it has also received support from pioneers in the field of AI such as Motherson Group, Anthropic, Nous Research, and Midjourney.
Bittensor: New gameplay under the incentive of subnet competition
Bittensor itself is not an AI commodity, nor does it produce or provide any AI products or services. Bittensor is an economic system that provides a highly competitive incentive structure for AI commodity producers, so that producers can continuously optimize the quality of AI. As an early project of Web3-AI, Bittensor has received widespread attention from the market since its launch. According to CoinMarketCap data, as of October 17, its market value has exceeded US$4.26 billion and its FDV (fully diluted valuation) has exceeded US$12 billion.
Bittensor has built a network architecture consisting of many subnet networks. AI commodity producers can create subnets with customized incentives and different use cases. Different subnets are responsible for different tasks, such as machine translation, image recognition and generation, language large models, etc. For example, Subnet 5 can create AI images like Midjourney. When excellent tasks are completed, TAO (Bittensors token) will be rewarded.
Incentive mechanisms are a fundamental part of Bittensor. They drive the behavior of subnet miners and control the consensus among subnet validators. Each subnet has its own incentive mechanism, where miners are responsible for performing tasks and validators score the results of subnet miners.
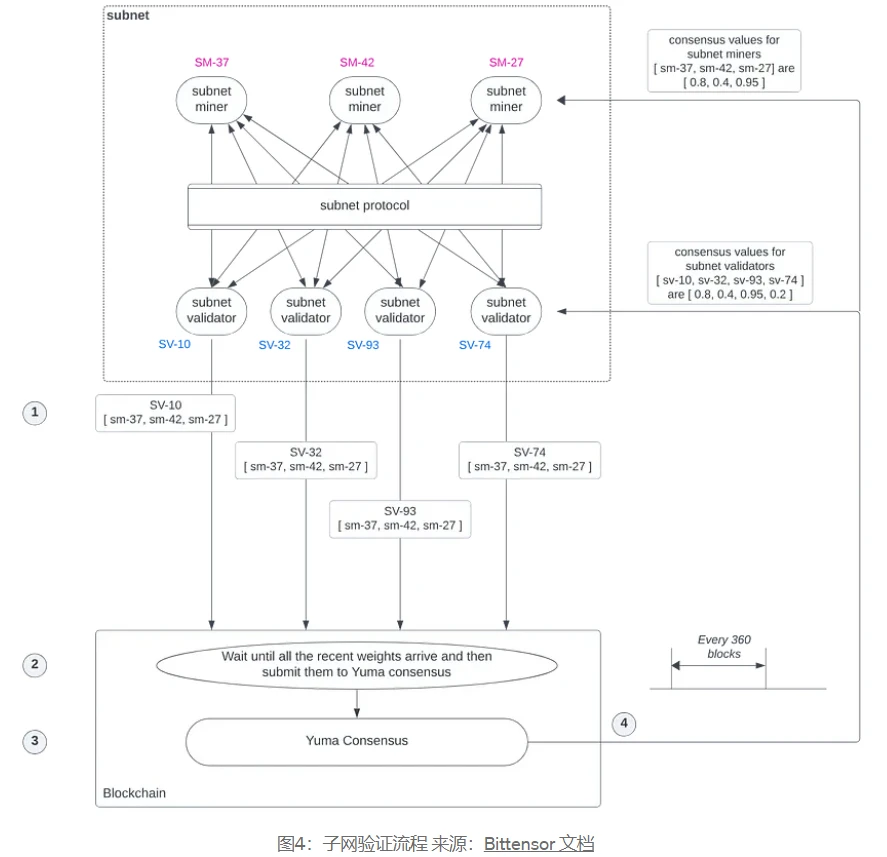
As shown in the figure, the workflow between subnet miners and subnet validators is demonstrated with an example:
The three subnet miners in the figure correspond to UID 37, 42 and 27 respectively; the four subnet validators correspond to UID 10, 32, 93 and 74 respectively.
Each subnet validator maintains a weight vector. Each element of the vector represents the weight assigned to a subnet miner, which is determined based on the subnet validators evaluation of the miners task completion. Each subnet validator ranks all subnet miners by the weight vector and operates independently, transmitting its miner ranking weight vector to the blockchain. Typically, each subnet validator transmits an updated ranking weight vector to the blockchain every 100-200 blocks.
The blockchain (subtensor) waits for the latest ranking weight vectors from all subnet validators of a given subnet to arrive on the blockchain. The ranking weight matrix formed by these ranking weight vectors is then provided as input to the on-chain Yuma consensus module.
The on-chain Yuma consensus uses this weight matrix along with the stake amount associated with the UID on that subnet to calculate rewards.
Yuma consensus calculates the consensus distribution of TAO and distributes the newly minted reward TAO to the account associated with the UID.
Subnet validators can transfer their ranking weight vectors to the blockchain at any time. However, the subnets Yuma consensus cycle uses the latest weight matrix at the beginning of every 360 blocks (i.e. 4320 seconds or 72 minutes, 12 seconds per block). If the ranking weight vector of a subnet validator arrives after a 360-block cycle, then that weight vector will be used at the beginning of the next Yuma consensus cycle. TAO rewards are issued at the end of each cycle.
Yuma consensus is Bittensors core algorithm for achieving fair node allocation. It is a hybrid consensus mechanism that combines elements of PoW and PoS. Similar to the Byzantine Fault Tolerant consensus mechanism, if the honest validators in the network are in the majority, they will eventually reach a consensus on the correct decision.
The Root Network is a special subnet, which is Subnet 0. By default, the 64 subnet validators with the most stakes in all subnets are validators in the root network. The root network validators will evaluate and rank according to the quality of each Subnets output. The evaluation results of the 64 validators will be aggregated, and the final emission result will be obtained through the Yuma Consensus algorithm. The final result will be used to allocate the newly issued TAO to each Subnet.
Although Bittensors subnet competition model improves the quality of AI products, it also faces some challenges. First, the incentive mechanism established by the subnet owner determines the miners income and may directly affect the miners work enthusiasm. Another problem is that the validator determines the token allocation amount of each subnet, but there is a lack of clear incentives to select subnets that are beneficial to Bittensors long-term productivity. This design may cause validators to prefer subnets with which they have a relationship or those that provide additional benefits. To solve this problem, contributors to the Opentensor Foundation proposed BIT 001: Dynamic TAO Solution, which proposes that the subnet token allocation amount for all TAO stakers to compete should be determined through a market mechanism.
Team Information:
Co-founder Ala Shaabana is a postdoctoral fellow at the University of Waterloo with an academic background in computer science. Another co-founder Jacob Robert Steeves graduated from Simon Fraser University in Canada, has nearly 10 years of experience in machine learning research, and worked as a software engineer at Google.
Financing Information:
In addition to receiving funding from the OpenTensor Foundation, a non-profit organization that supports Bittensor, Bittensor has announced in its community announcement that well-known crypto VCs Pantera and Collab Currency have become holders of TAO tokens and will provide more support for the projects ecological development. Other major investors include well-known investment institutions and market makers including Digital Currency Group, Polychain Capital, FirstMark Capital, GSR, etc.
Talus: On-chain AI agent ecosystem based on Move
Talus Network is an L1 blockchain built on MoveVM, designed for AI agents. These AI agents can make decisions and take actions based on predefined goals, achieve smooth inter-chain interactions, and be verifiable. Users can use the development tools provided by Talus to quickly build AI agents and integrate them into smart contracts. Talus also provides an open AI market for resources such as AI models, data, and computing power, where users can participate in various forms and tokenize their contributions and assets.
One of the major features of Talus is its parallel execution and secure execution capabilities. With the entry of capital into the Move ecosystem and the expansion of high-quality projects, Taluss dual highlights of secure execution based on Move and AI agent integrated smart contracts are expected to attract widespread attention in the market. At the same time, the multi-chain interaction supported by Talus can also improve the efficiency of AI agents and promote the prosperity of AI on other chains.
According to the official Twitter information, Talus recently launched Nexus, the first fully on-chain autonomous AI agent framework, which gives Talus a first-mover advantage in the field of decentralized AI technology and provides it with important competitiveness in the rapidly developing blockchain AI market. Nexus enables developers to create AI-driven digital assistants on the Talus network, ensuring anti-censorship, transparency, and composability. Unlike centralized AI solutions, through Nexus, consumers can enjoy personalized intelligent services, securely manage digital assets, automate interactions, and enhance daily digital experiences.
As the first developer toolkit for on-chain agents, Nexus provides the foundation for building the next generation of consumer crypto AI applications. Nexus provides a range of tools, resources, and standards to help developers create agents that can execute user intent and communicate with each other on the Talus chain. Among them, the Nexus Python SDK bridges the gap between AI and blockchain development, making it easy for AI developers to get started without learning smart contract programming. Talus provides user-friendly development tools and a range of infrastructure, and is expected to become an ideal platform for developer innovation.
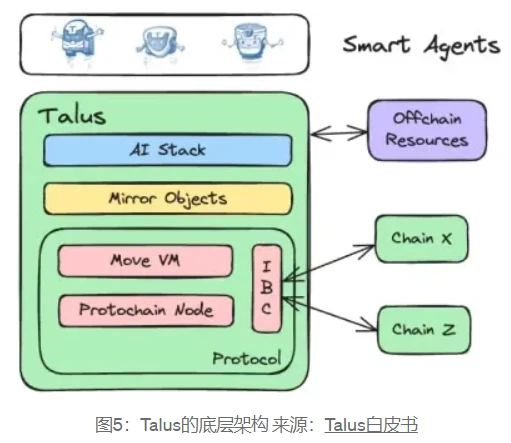
As shown in Figure 5, the underlying architecture of Talus is based on a modular design, with the flexibility of off-chain resources and multi-chain interactions. Based on the unique design of Talus, a prosperous on-chain smart agent ecosystem is formed.
The protocol is the core of Talus and provides the foundation for consensus, execution, and interoperability, on top of which on-chain smart agents can be built to utilize off-chain resources and cross-chain functions.
Protochain Node: A PoS blockchain node based on Cosmos SDK and CometBFT. Cosmos SDK has modular design and high scalability. CometBFT is based on the Byzantine Fault Tolerant consensus algorithm, with high performance and low latency. It provides strong security and fault tolerance, and can continue to operate normally in the event of some node failures or malicious behavior.
Sui Move and MoveVM: Using Sui Move as the smart contract language, the design of the Move language inherently enhances security by eliminating critical vulnerabilities such as reentrancy attacks, missing access control checks for object ownership, and unexpected arithmetic overflow/underflow. The architecture of the Move VM supports efficient parallel processing, enabling Talus to scale by processing multiple transactions simultaneously without losing security or integrity.
IBC (The Inter-Blockchain Communication protocol):
Interoperability: IBC facilitates seamless interoperability between different blockchains, enabling smart agents to interact and utilize data or assets on multiple chains.
Cross-chain atomicity: IBC supports cross-chain atomic transactions, which is critical for maintaining the consistency and reliability of operations performed by smart agents, especially in financial applications or complex workflows.
Scalability through Sharding: IBC indirectly supports scalability through sharding by enabling smart agents to operate on multiple blockchains. Each blockchain can be viewed as a shard that processes a portion of transactions, thereby reducing the load on any single chain. This enables smart agents to manage and execute tasks in a more distributed and scalable manner.
Customizability and Specialization: With IBC, different blockchains can focus on specific functions or optimizations. For example, a smart agent might use one chain that allows for fast transactions for payment processing and another chain that is specialized for secure data storage for record keeping.
Security and Isolation: IBC maintains security and isolation between chains, which is beneficial for smart agents that handle sensitive operations or data. Since IBC ensures secure verification of inter-chain communications and transactions, smart agents can confidently operate between different chains without compromising on security.
Mirror Object:
In order to represent the off-chain world in the on-chain architecture, mirror objects are mainly used to verify and link AI resources, such as: resource uniqueness representation and proof, off-chain resource tradability, ownership proof representation or ownership verifiability.
Image objects include three different types of image objects: model objects, data objects, and calculation objects.
Model Objects: Model owners can bring their AI models into the ecosystem through a dedicated model registry, bringing off-chain models to the chain. Model objects encapsulate the essence and capabilities of the model and build ownership, management, and monetization frameworks directly on top of them. Model objects are flexible assets that can be enhanced through additional fine-tuning processes or completely reshaped through extensive training to meet specific needs when necessary.
Data Object: A data (or dataset) object exists as a digital representation of a unique dataset owned by someone. This object can be created, transferred, licensed or converted into an open data source.
Computational Object: The buyer proposes a computational task to the owner of the object, who then provides the computational result and the corresponding proof. The buyer holds the key that can be used to decrypt the commitment and verify the result.
AI Stack:
Talus provides an SDK and integration components that support the development of intelligent agents and their interaction with off-chain resources. The AI stack also includes integration with Oracles, ensuring that intelligent agents can make decisions and react using off-chain data.
On-chain smart agent:
Talus provides an economy of smart agents that can operate autonomously, make decisions, execute transactions, and interact with on-chain and off-chain resources.
Intelligent agents have autonomy, social capabilities, responsiveness, and initiative. Autonomy enables them to operate without human intervention, social capabilities enable them to interact with other agents and humans, responsiveness enables them to perceive environmental changes and respond in a timely manner (Talus supports agents to respond to on-chain and off-chain events through listeners), and initiative enables them to take actions based on goals, predictions, or expected future states.
In addition to the development architecture and infrastructure of a series of intelligent agents provided by Talus, AI agents built on Talus also support multiple types of verifiable AI reasoning (opML, zkML, etc.) to ensure the transparency and credibility of AI reasoning. A set of facilities designed by Talus specifically for AI agents can realize multi-chain interaction and mapping functions between on-chain and off-chain resources.
The on-chain AI agent ecosystem launched by Talus is of great significance to the development of the integration technology of AI and blockchain, but it is still difficult to implement. Talus infrastructure enables the development of AI agents with flexibility and interoperability, but as more and more AI agents run on the Talus chain, whether the interoperability and efficiency between these agents can meet user needs remains to be verified. At present, Talus is still in the private testnet stage and is constantly being developed and updated. It is expected that Talus can promote the further development of the on-chain AI agent ecosystem in the future.
Team Information:
Mike Hanono is the founder and CEO of Talus Network. He holds a bachelors degree in industrial and systems engineering and a masters degree in applied data science from the University of Southern California. He has participated in the Wharton School of the University of Pennsylvania and has extensive experience in data analysis, software development, and project management.
Financing Information:
In February this year, Talus completed its first round of financing of US$3 million, led by Polychain Capital, with participation from Dao 5, Hash 3, TRGC, WAGMI Ventures, Inception Capital, etc. Angel investors mainly came from Nvidia, IBM, Blue 7, Symbolic Capital and Render Network.
ORA: The cornerstone of on-chain verifiable AI
ORAs product OAO (On-chain AI Oracle) is the worlds first AI oracle that uses opML, which can bring off-chain AI reasoning results onto the chain. This means that smart contracts can interact with OAO to implement AI functions on the chain. In addition, ORAs AI oracle can be seamlessly combined with the Initial Model Issuance (IMO) to provide a full-process on-chain AI service.
ORA has a first-mover advantage in both technology and the market. As a trustless AI oracle on Ethereum, it will have a profound impact on its broad user base, and more innovative AI application scenarios are expected to emerge in the future. Developers can now use the models provided by ORA in smart contracts to achieve decentralized reasoning, and can build verifiable AI dApps on Ethereum, Arbitrum, Optimism, Base, Polygon, Linea, and Manta. In addition to providing verification services for AI reasoning, ORA also provides model issuance services (IMO) to promote the contribution of open source models.
ORA’s two main products are: Initial Model Issuance (IMO) and On-Chain AI Oracle (OAO), which work perfectly together to enable the acquisition of on-chain AI models and the verification of AI reasoning.
IMO incentivizes long-term open source contributions by tokenizing the ownership of open source AI models, and token holders will receive a portion of the revenue generated by the use of the model on the chain. ORA also provides funding for AI developers to incentivize the community and open source contributors.
OAO brings verifiable AI reasoning on the chain. ORA introduces opML as the verification layer of AI oracle. Similar to the workflow of OP Rollup, the verifier or any network participant can check the results during the challenge period. If the challenge is successful, the wrong result is updated on the chain. After the challenge period, the result is finalized and immutable.
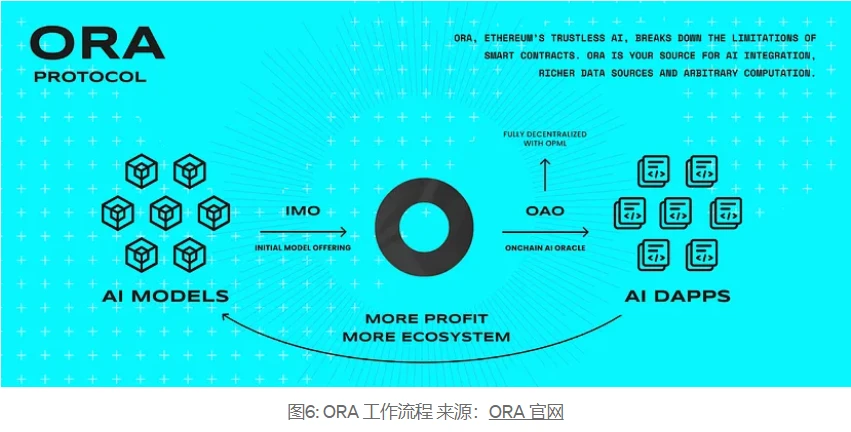
To build a verifiable and decentralized oracle network, it is crucial to ensure the computational validity of the results on the blockchain. This process involves a system of proofs that ensure the computation is reliable and authentic.
To this end, ORA provides three proof system frameworks:
AI Oracles opML (currently ORAs AI oracle already supports opML)
keras 2c ircoms zkML (mature and high-performance zkML framework)
zk+opML combines the privacy of zkML and the scalability of opML to realize future on-chain AI solutions through opp/ai
opML:
opML (Optimistic Machine Learning) was invented and developed by ORA, combining machine learning with blockchain technology. By leveraging similar principles to Optimistic Rollups, opML ensures the validity of computations in a decentralized manner. The framework allows on-chain verification of AI computations, increasing transparency and promoting trust in machine learning reasoning.
To ensure security and correctness, opML employs the following fraud protection mechanisms:
Result submission: The service provider (submitter) performs machine learning calculations off-chain and submits the results to the blockchain.
Verification period: The verifier (or challenger) has a predefined period (challenge period) to verify the correctness of the submitted results.
Dispute Resolution: If a validator finds that a result is incorrect, they initiate an interactive dispute game. This dispute game effectively determines the exact computational step where the error occurred.
On-chain verification: Only the disputed computation steps are verified on-chain through the Fraud Proof Virtual Machine (FPVM), minimizing resource usage.
Finalization: If no disputes are raised during the challenge period, or once a dispute is resolved, the result will be finalized on the blockchain.
ORAs opML enables computation to be performed off-chain in an optimized environment, processing only minimal data on-chain in the event of a dispute. This avoids the expensive proof generation required for zero-knowledge machine learning (zkML) and reduces computational costs. This approach is able to handle large-scale computations that are difficult to achieve with traditional on-chain methods.
keras 2c ircom (zkML):
zkML is a proof framework that uses zero-knowledge proofs to verify machine learning reasoning results on-chain. Due to its privacy, it can protect private data and model parameters during training and reasoning, thereby solving privacy issues. Since the actual calculation of zkML is completed off-chain, the chain only needs to verify the validity of the results, thus reducing the computational load on the chain.
Keras 2C ircom, built by ORA, is the first high-level, battle-tested zkML framework. According to a benchmark of leading zkML frameworks from the Ethereum Foundation ESP funding proposal [FY 23 – 1290], Keras 2C ircom and its underlying circomlib-ml were shown to be more performant than other frameworks.
opp/ai (opML + zkML):
ORA also proposed OPP/AI (Optimistic Privacy-Preserving AI on Blockchain), which integrates zero-knowledge machine learning (zkML) for privacy with optimistic machine learning (opML) for efficiency, creating a hybrid model tailored for on-chain AI. By strategically partitioning machine learning (ML) models, opp/ai balances computational efficiency and data privacy, thereby achieving secure and efficient on-chain AI services.
opp/ai divides ML models into multiple sub-models based on privacy requirements: the zkML sub-model is used to process components with sensitive data or proprietary algorithms, and is executed using zero-knowledge proofs to ensure the confidentiality of data and models; the opML sub-model is used to process components that prioritize efficiency over privacy, and is executed using opMLs optimistic approach to achieve maximum efficiency.
In summary, ORA innovatively proposed three proof frameworks: opML, zkML, and opp/ai (a combination of opML and zkML). The diverse proof frameworks enhance data privacy and computing efficiency, bringing higher flexibility and security to blockchain applications.
As the first AI oracle, ORA has great potential and broad imagination space. ORA has published a large number of research and results, demonstrating its technical advantages. However, the reasoning process of AI models has certain complexity and verification costs. Whether the reasoning speed of on-chain AI can meet user needs has become a question that needs to be verified. After time verification and continuous optimization of user experience, such AI products may be a great tool to improve the efficiency of on-chain Dapps.
Team Information:
Co-founder Kartin graduated from the University of Arizona with a degree in computer science and has served as a technical leader at Tiktok and a software engineer at Google.
Chief Scientist Cathie holds a masters degree in computer science from the University of Southern California and a doctorate in psychology and neuroscience from the University of Hong Kong. She was a zkML researcher at the Ethereum Foundation.
Financing Information:
On June 26 this year, ORA announced the completion of a 20 million financing round, with investors including Polychain Capital, HF 0, Hashkey Capital, SevenX Ventures and Geekcartel.
Grass: The data layer for AI models
Grass focuses on turning public network data into AI datasets. Grasss network uses users excess bandwidth to scrape data from the Internet without obtaining users personal privacy information. This type of network data is indispensable for the development of artificial intelligence models and the operation of many other industries. Users can run nodes and earn Grass points. Running a node on Grass is as easy as registering and installing a Chrome extension.
Grass links AI demanders and data providers, creating a win-win situation. Its advantages are: simple installation operations and future airdrop expectations greatly promote user participation, which also provides more data sources for demanders. As data providers, users do not need to perform complex settings and actions, and data capture, cleaning and other operations can be performed without user perception. In addition, there are no special requirements for equipment, which lowers the threshold for user participation, and its invitation mechanism also effectively promotes more users to join quickly.
Since Grass needs to perform data crawling operations to reach tens of millions of web requests per minute. These all need to be verified, which will require more throughput than any L1 can provide. The Grass team announced in March that it will build a Rollup plan to support users and builders to verify the source of data. The plan batches metadata through the ZK processor for verification, and the proof of each dataset metadata will be stored on Solanas settlement layer and generate a data ledger.
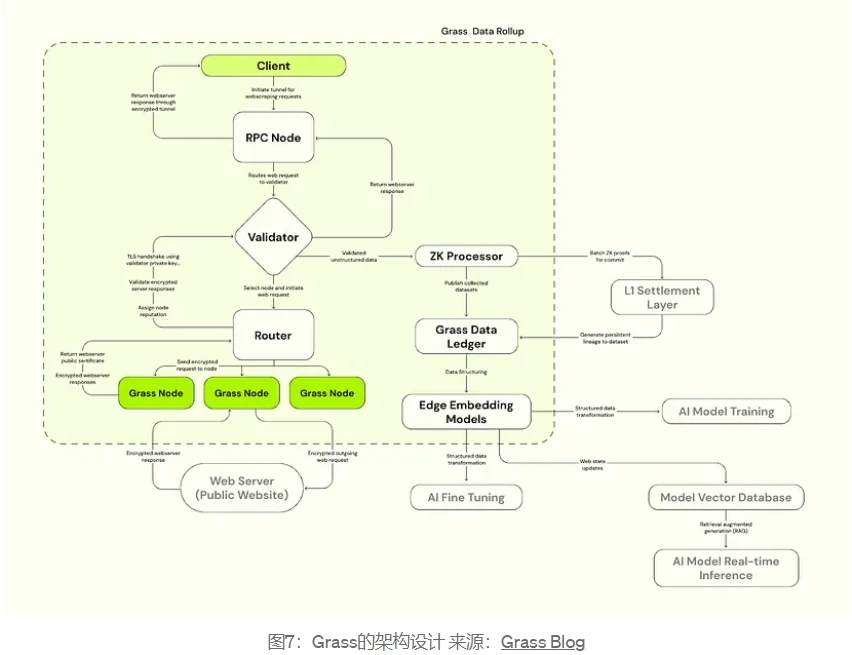
As shown in the figure, clients make web requests, which pass through validators and are ultimately routed to Grass nodes, and the websites server responds to web page requests, allowing its data to be fetched and returned. The purpose of the ZK processor is to help record the source of the datasets fetched on the Grass network. This means that every time a node fetches the network, they can get their rewards without revealing any information about their identity. After being recorded in the data ledger, the collected data is cleaned and structured through the graph embedding model (Edge Embedding) for AI training.
In summary, Grass allows users to contribute excess bandwidth to capture network data to earn passive income while protecting personal privacy. This design not only brings economic benefits to users, but also provides AI companies with a decentralized way to obtain a large amount of real data.
Although Grass has greatly lowered the threshold for user participation and is conducive to increasing user participation, the project side needs to consider that the participation of real users and the influx of wool parties may bring a large amount of spam, which will increase the burden of data processing. Therefore, the project side needs to set up a reasonable incentive mechanism and price the data to obtain truly valuable data. This is an important influencing factor for both the project side and the users. If users feel confused or unfair about the airdrop allocation, they may distrust the project side, which will affect the consensus and development of the project.
Team Information:
Founder Dr. Andrej graduated from York University in Canada with a degree in Computational and Applied Mathematics. Chief Technology Officer Chris Nguyen has many years of experience in data processing, and the data company he founded has won many honors, including the IBM Cloud Embedded Excellence Award, Enterprise Technology Top 30, and Forbes Cloud 100 Rising Stars.
Financing Information:
Grass is the first product launched by the Wynd Network team, which completed a $3.5 million seed round of financing led by Polychain Capital and Tribe Capital in December 2023, with participation from Bitscale, Big Brain, Advisors Anonymous, Typhon V, Mozaik, etc. Previously, No Limit Holdings led the Pre-see round of financing, with a total financing amount of $4.5 million.
In September this year, Grass completed its Series A financing, led by Hack VC and participated by Polychain, Delphi Digital, Brevan Howard Digital, Lattice fund and others. The amount of financing was not disclosed.
IO.NET: Decentralized computing resource platform
IO.NET aggregates idle network computing resources around the world by building a decentralized GPU network on Solana. This enables AI engineers to obtain the required GPU computing resources at a lower cost, easier to obtain, and more flexible. ML teams can build model training and reasoning service workflows on a distributed GPU network.
IO.NET not only provides income for users with idle computing power, but also greatly reduces the computing power burden of small teams or individuals. With Solanas high throughput and efficient execution efficiency, it has an inherent advantage in GPU network scheduling.
IO.NET has received a lot of attention and favor from top institutions since its launch. According to CoinMarketCap, as of October 17, the market value of its tokens has exceeded US$220 million, and the FDV has exceeded US$1.47 billion.
One of the core technologies of IO.NET is IO-SDK, which is based on a dedicated fork of Ray. (Ray is an open source framework used by OpenAI that can scale AI and Python applications such as machine learning to clusters to handle large amounts of computation). Using Rays native parallelism, IO-SDK can parallelize Python functions and also supports integration with mainstream ML frameworks such as PyTorch and TensorFlow. Its memory storage enables fast data sharing between tasks, eliminating serialization delays.

Product Components:
IO Cloud: Designed for on-demand deployment and management of decentralized GPU clusters, it integrates seamlessly with IO-SDK to provide a comprehensive solution for scaling AI and Python applications. It provides computing power while simplifying the deployment and management of GPU/CPU resources. It reduces potential risks through firewalls, access control, and modular design, and isolates different functions to increase security.
IO Worker: Users can manage their GPU node operations through this web application interface, including computing activity monitoring, temperature and power consumption tracking, installation assistance, security measures and revenue status.
IO Explorer: Mainly provides users with comprehensive statistics and visualization of various aspects of GPU Cloud, allowing users to view network activity, key statistics, data points and reward transactions in real time.
IO ID: Users can view their personal account status, including wallet address activity, wallet balance, and claim earnings.
IO Coin: Supports users to view the token status of IO.NET.
BC 8.AI: This is an AI image generation website powered by IO.NET, where users can implement the AI generation process of text to image.
IO.NET uses idle computing power from cryptocurrency miners, projects like Filecoin and Render, and other projects to aggregate more than one million GPU resources, allowing AI engineers or teams to customize and purchase GPU computing services according to their needs. By utilizing idle computing resources around the world, users who provide computing power can tokenize their earnings. IO.NET not only optimizes resource utilization, but also reduces high computing costs, promoting a wider range of AI and computing applications.
As a decentralized computing power platform, IO.NET should focus on user experience, computing power resource richness and resource scheduling and monitoring, which are important chips for winning in the decentralized computing power track. However, there have been disputes about resource scheduling before, and some people questioned the mismatch between resource scheduling and user orders. Although we cannot confirm the authenticity of this matter, it also reminds related projects that they should pay attention to the optimization of these aspects and the improvement of user experience. Without the support of users, the exquisite products are just vases.
Team Information:
Founder Ahmad Shadid was previously a quantitative system engineer at WhalesTrader and a contributor and mentor to the Ethereum Foundation. CTO Gaurav Sharma previously worked as a senior development engineer at Amazon, an architect at eBay, and worked in the engineering department at Binance.
Financing Information:
On May 1, 2023, the company officially announced the completion of a $10 million seed round of financing;
On March 5, 2024, it announced the completion of a US$30 million Series A financing round, led by Hack VC, with participation from Multicoin Capital, 6th Man Ventures, M 13, Delphi Digital, Solana Labs, Aptos Labs, Foresight Ventures, Longhash, SevenX, ArkStream, Animoca Brands, Continue Capital, MH Ventures, Sandbox Games, etc.
MyShell: An AI agent platform connecting consumers and creators
MyShell is a decentralized AI consumer layer that connects consumers, creators, and open source researchers. Users can use the AI agents provided by the platform, or build their own AI agents or applications on MyShells development platform. MyShell provides an open market for users to freely trade AI agents. In MyShells AIpp store, you can see a variety of AI agents, including virtual companions, trading assistants, and AIGC-type agents.
As a low-threshold alternative to various types of AI chatbots such as ChatGPT, MyShell provides a wide range of AI functional platforms, lowering the threshold for users to use AI models and agents, enabling users to get a comprehensive AI experience. For example, users may want to use Claude for document organization and writing optimization, while using Midjourney to generate high-quality images. Usually, this requires users to register multiple accounts on different platforms and pay for some services. MyShell provides a one-stop service, providing free AI quotas every day, and users do not need to register and pay fees repeatedly.
In addition, some AI products have restrictions on certain regions, but on the MyShell platform, users can generally use various AI services smoothly, which significantly improves the user experience. These advantages of MyShell make it an ideal choice for user experience, providing users with a convenient, efficient and seamless AI service experience.
The MyShell ecosystem is built on three core components:
Self-developed AI models: MyShell has developed multiple open source AI models, including AIGC and large language models, which users can use directly; you can also find more open source models on the official Github.
Open AI development platform: Users can easily build AI applications. The MyShell platform allows creators to leverage different models and integrate external APIs. With native development workflows and modular toolkits, creators can quickly transform their ideas into functional AI applications, accelerating innovation.
Fair incentive ecosystem: MyShells incentive method encourages users to create content that meets their personal preferences. Creators can receive native platform rewards when using self-built applications, and can also receive funds from consumers.
In MyShells Workshop, you can see that it supports users to build AI robots in three modes. Both professional developers and ordinary users can match the appropriate mode. Use the classic mode to set model parameters and instructions, which can be integrated into social media software; the development mode requires users to upload their own model files; using the ShellAgent mode, you can build AI robots in a code-free form.
MyShell combines the concept of decentralization with AI technology, and is committed to providing an open, flexible and fair incentive ecosystem for consumers, creators and researchers. Through self-developed AI models, open development platforms and multiple incentive methods, it provides users with a wealth of tools and resources to realize their creativity and needs.
MyShell has integrated a variety of high-quality models, and the team is also continuously developing many AI models to improve the user experience. However, MyShell still faces some challenges in use. For example, some users reported that some models support for Chinese needs to be improved. However, by looking at the MyShell code repository, you can see that the team is continuously updating and optimizing, and actively listening to feedback from the community. I believe that with continuous improvement, the user experience will be better in the future.
Team Information:
Co-founder Zengyi Qin focuses on voice algorithm research and holds a Ph.D. from MIT. While pursuing a bachelors degree at Tsinghua University, he has published several top conference papers. He also has professional experience in robotics, computer vision, and reinforcement learning. Another co-founder, Ethan Sun, graduated from Oxford University with a degree in computer science and has many years of work experience in the AR+AI field.
Financing Information:
In October 2023, it raised $5.6 million in seed round financing. Led by INCE Capital, Hashkey Capital, Folius Ventures, SevenX Ventures, OP Crypto and others participated in the investment.
In March 2024, it received $11 million in financing in its latest Pre-A round of financing. The financing was led by Dragonfly, and participated by investment institutions such as Delphi Digital, Bankless Ventures, Maven 11 Capital, Nascent, Nomad, Foresight Ventures, Animoca Ventures, OKX Ventures and GSR. In addition, this round of financing also received support from angel investors such as Balaji Srinivasan, Illia Polosukhin, Casey K. Caruso, and Santiago Santos.
In August this year, Binance Labs announced an investment in MyShell through its sixth season incubation program, with the specific amount not disclosed.
IV. Challenges and considerations that need to be addressed
Although the track is still in its infancy, practitioners should think about some important factors that affect the success of the project. Here are some aspects to consider:
Balance between supply and demand of AI resources: For Web3-AI ecological projects, it is extremely important to achieve a balance between supply and demand of AI resources and attract more people with real needs and who are willing to contribute. For example, users who have model, data, and computing power needs may have become accustomed to obtaining AI resources on the Web2 platform. At the same time, how to attract AI resource providers to contribute to the Web3-AI ecosystem, and how to attract more demanders to obtain resources and achieve a reasonable match of AI resources is also one of the challenges facing the industry.
Data challenge: Data quality directly affects the model training effect. Ensuring data quality during data collection and data preprocessing, and filtering out the large amount of junk data brought by wool users will be important challenges faced by data projects. Project owners can improve the credibility of data through scientific data quality control methods and more transparently display the effect of data processing, which will also be more attractive to data demanders.
Security issues: In the Web3 industry, it is necessary to use blockchain and privacy technologies to achieve on-chain and off-chain interactions of AI assets to prevent malicious actors from affecting the quality of AI assets and to ensure the security of AI resources such as data and models. Some project parties have proposed solutions, but the field is still under construction. As the technology continues to improve, higher and proven security standards are expected to be achieved.
User Experience:
Web2 users are usually accustomed to traditional operating experience, while Web3 projects are usually accompanied by complex smart contracts, decentralized wallets and other technologies, which may have a high threshold for ordinary users. The industry should consider how to further optimize user experience and educational facilities to attract more Web2 users to enter the Web3-AI ecosystem.
For Web3 users, establishing an effective incentive mechanism and a continuously operating economic system is the key to promoting long-term user retention and healthy development of the ecosystem. At the same time, we should think about how to maximize the use of AI technology to improve the efficiency of the Web3 field and innovate more application scenarios and gameplay combined with AI. These are all key factors that affect the healthy development of the ecosystem.
As the development trend of Internet+ continues to evolve, we have witnessed countless innovations and changes. At present, many fields have been combined with AI. Looking forward to the future, the era of AI+ may blossom everywhere and completely change our way of life. The integration of Web3 and AI means that the ownership and control of data will return to users, making AI more transparent and trustworthy. This integration trend is expected to build a more fair and open market environment and promote efficiency improvement and innovative development in all walks of life. We look forward to industry builders working together to create better AI solutions.
References
https://ieeexplore.ieee.org/abstract/document/9451544
https://docs.ora.io/doc/oao-onchain-ai-oracle/introduction
https://saharalabs.ai/
https://saharalabs.ai/blog/sahara-ai-raise-43m
https://bittensor.com/
https://docs.bittensor.com/yuma-consensus
https://docs.bittensor.com/emissions#emission
https://twitter.com/myshell_ai
https://twitter.com/SubVortexTao
https://foresightnews.pro/article/detail/49752
https://www.ora.io/
https://docs.ora.io/doc/imo/introduction
https://github.com/ora-io/keras2c ircom
https://arxiv.org/abs/2401.17555
https://arxiv.org/abs/2402.15006
https://x.com/OraProtocol/status/1805981228329513260
https://x.com/getgrass_io
https://www.getgrass.io/blog/grass-the-first-ever-layer-2-data-rollup
https://wynd-network.gitbook.io/grass-docs/architecture/overview#edge-embedding-models
http://IO.NET
https://www.ray.io/
https://www.techflowpost.com/article/detail_17611.html
https://myshell.ai/
https://www.chaincatcher.com/article/2118663
Acknowledgements
There is still a lot of research and work to be done in this emerging infrastructure paradigm, and there are many areas that are not covered in this article. If you are interested in related research topics, please contact Chloe.
Many thanks to Severus and JiaYi for their insightful comments and feedback on this article. Finally, thanks to JiaYi for her cat love appearance.





