




原作者: Zeke、YBB Capital

序文
GPT-3 の誕生以来、生成 AI は、その驚くべきパフォーマンスと幅広い応用シナリオにより、人工知能の分野に爆発的な転換点をもたらし、テクノロジーの巨人が AI トラックに飛び込むために集まり始めています。しかし、問題も発生します。大規模言語モデル (LLM) のトレーニングと推論には大量の計算能力が必要です。モデルの反復的なアップグレードにより、計算能力の要件とコストが指数関数的に増加します。 GPT-2とGPT-3を例にとると、GPT-2とGPT-3のパラメータ量の差は1166倍(GPT-2は1億5000万パラメータ、GPT-3は1750億パラメータ)です。 GPT-3 コストは当時のパブリック GPU クラウドの価格モデルに基づいて計算され、GPT-2 の 200 倍である最大 1,200 万米ドルでした。実際の使用では、すべてのユーザーの質問には推論計算が必要であり、今年初めの 1,300 万のユニーク ユーザー訪問に基づくと、対応するチップ需要は 30,000 A 100 GPU 以上になります。その場合、初期投資コストは 8 億ドルという驚異的な金額になり、1 日あたりのモデル推論コストは 70 万ドルと見積もられます。
不十分なコンピューティング能力と高コストは AI 業界全体が直面する問題となっていますが、同じ問題がブロックチェーン業界でも悩まされているようです。一方で、ビットコインの4度目の半減期とETFの採用が目前に迫っており、将来的に価格が上昇するにつれて、マイナーのコンピューティングハードウェアに対する需要が大幅に増加することは避けられません。一方、ゼロ知識証明 ("Zero-Knowledge Proof"、略してZKP)テクノロジーは急成長しており、ヴィタリック氏は、今後10年間のブロックチェーン分野に対するZKの影響はブロックチェーン自体と同じくらい重要になると繰り返し強調しました。ブロックチェーン業界はこの技術の将来性に大きな期待を寄せていますが、ZKもAIと同様に複雑な計算プロセスのため、証明の生成に多くの計算能力と時間を消費します。
近い将来、コンピューティングパワーの不足は避けられないでしょう。では、分散型コンピューティングパワー市場は良いビジネスとなるでしょうか?
分散型コンピューティング市場の定義
分散型コンピューティングのパワー市場は、実際には基本的に分散型クラウド コンピューティングのトラックに相当しますが、分散型クラウド コンピューティングと比較すると、この用語は後で説明する新しいプロジェクトを説明するのにより適切であると個人的には考えています。分散型コンピューティング電力市場は、DePIN (分散型物理インフラストラクチャ ネットワーク) のサブセットに属する必要があります。その目標は、オープンなコンピューティング電力市場を作成することです。トークン インセンティブを通じて、アイドル状態のコンピューティング電力リソースを持つ人は誰でも、そのリソースをこの市場で提供できます。主にBエンドユーザーと開発者グループにサービスを提供しています。分散型 GPU ベースのレンダリング ソリューション ネットワークである Render Network や、クラウド コンピューティングの分散型ピアツーピア マーケットである Akash Network など、より身近なプロジェクトの観点から見ると、両方ともこのトラックに属します。
以下では、基本概念から始めて、このトラックの下で 3 つの新興市場、AGI コンピューティング能力市場、ビットコイン コンピューティング能力市場、ZK ハードウェア アクセラレーション市場の AGI コンピューティング能力市場について説明します。 「潜在的なトラックプレビュー: 分散型コンピューティングパワー市場 (パート 2)」で説明します。
コンピューティング能力の概要
計算能力の概念の起源は、コンピュータの発明の初期にまで遡ることができます。元のコンピュータは、計算タスクを完了するために機械装置を使用していました。計算能力とは、機械装置の計算能力を指します。コンピュータ技術の発展に伴い、コンピューティング能力の概念も進化しました。今日のコンピューティング能力とは、通常、コンピュータのハードウェア (CPU、GPU、FPGA など) とソフトウェア (オペレーティング システム、コンパイラ、アプリケーション プログラムなど) の共同作業を指します。 .) 能力。
意味
コンピューティング能力とは、コンピュータまたはその他のコンピューティング デバイスが処理できるデータの量、または一定期間内に完了するコンピューティング タスクの数を指します。コンピューティング能力は、通常、コンピュータまたはその他のコンピューティング デバイスのパフォーマンスを説明するために使用され、コンピューティング デバイスの処理能力を示す重要な指標です。
メトリクス
計算能力は、計算速度、計算エネルギー消費量、計算精度、並列処理など、さまざまな方法で測定できます。コンピューター分野で一般的に使用されるコンピューティング能力の指標には、FLOPS (1 秒あたりの浮動小数点演算数)、IPS (1 秒あたりの命令数)、TPS (1 秒あたりのトランザクション数) などが含まれます。
FLOPS (1 秒あたりの浮動小数点演算) は、浮動小数点演算 (精度の問題や丸め誤差を考慮する必要がある、小数点を含む数値の数学的演算) を処理するコンピューターの能力を指し、コンピューターが 1 秒間にどれだけの処理を完了できるかを測定します。浮動小数点演算。 FLOPS はコンピューターの高性能コンピューティング能力の尺度であり、スーパーコンピューター、高性能コンピューティング サーバー、グラフィックス プロセッシング ユニット (GPU) などのコンピューティング能力を測定するために一般的に使用されます。たとえば、コンピュータ システムの FLOPS は 1 TFLOPS (1 秒あたり 1 兆回の浮動小数点演算) であり、1 秒あたり 1 兆回の浮動小数点演算を完了できることを意味します。
IPS (1 秒あたりの命令数) は、コンピューターが命令を処理する速度を指し、コンピューターが 1 秒あたりに実行できる命令の数の尺度です。 IPS はコンピュータの単一命令のパフォーマンスの尺度であり、通常は中央処理装置 (CPU) などのパフォーマンスを測定するために使用されます。たとえば、IPS が 3 GHz (1 秒あたり 3 億命令) の CPU は、1 秒あたり 3 億命令を実行できることを意味します。
TPS (1 秒あたりのトランザクション数) は、コンピュータのトランザクション処理能力を指し、コンピュータが 1 秒間に完了できるトランザクションの数を測定します。通常、データベース サーバーのパフォーマンスを測定するために使用されます。たとえば、データベース サーバーの TPS は 1000 で、1 秒あたり 1000 のデータベース トランザクションを処理できることを意味します。
さらに、推論速度、画像処理速度、音声認識精度など、特定のアプリケーション シナリオ向けのコンピューティング能力指標がいくつかあります。
コンピューティング能力の種類
GPU の計算能力とは、グラフィックス プロセッサ (グラフィックス プロセッシング ユニット) の計算能力を指します。 GPU は CPU (中央処理装置) とは異なり、画像やビデオなどのグラフィックス データを処理するために特別に設計されたハードウェアであり、多数の処理ユニットと効率的な並列計算能力を備え、同時に多数の浮動小数点演算を実行できます。 。 GPU はもともとゲーム グラフィックス処理用に設計されているため、通常、複雑なグラフィックス操作をサポートするために CPU よりも高いクロック周波数と広いメモリ帯域幅を備えています。
CPUとGPUの違い
アーキテクチャ: CPU と GPU は異なるコンピューティング アーキテクチャを持っています。通常、CPU は 1 つ以上のコアを採用しており、各コアはさまざまな異なる操作を実行できる汎用プロセッサです。 GPU には多数のストリーム プロセッサとシェーダがあり、これらは画像処理に関連する操作を実行するために特に使用されます。
並列コンピューティング: GPU は通常、より高い並列コンピューティング機能を備えています。 CPU には限られた数のコアがあり、各コアは 1 つの命令しか実行できませんが、GPU には複数の命令と操作を同時に実行できる数千のストリーム プロセッサを搭載できます。したがって、GPU は一般に、大量の並列コンピューティングを必要とする機械学習や深層学習などの並列コンピューティング タスクの実行に CPU よりも適しています。
プログラミング: GPU プログラミングは CPU よりも複雑で、特定のプログラミング言語 (CUDA や OpenCL など) の使用と、GPU の並列コンピューティング機能を利用するための特定のプログラミング手法の使用が必要です。これに対し、CPUプログラミングはよりシンプルで汎用のプログラミング言語やプログラミングツールを利用できます。
コンピューティング能力の重要性
産業革命の時代、石油は世界の血液となり、あらゆる産業に浸透しました。コンピューティング パワーはブロックチェーンにあり、来るべき AI 時代では、コンピューティング パワーは世界の「デジタル オイル」となります。大手企業による AI チップと 1 兆を超える Nvidia 株の狂信的な買収から、最近の米国による中国からのハイエンドチップの封鎖まで、その詳細にはコンピューティング能力、チップ面積、さらには GPU クラウドを禁止する計画さえ含まれています。重要性は自明ですが、コンピューティング能力は次の時代の商品になります。

汎用人工知能の概要
人工知能(Artificial Intelligence)は、人間の知能をシミュレート、拡張、拡張するための理論、方法、技術、およびアプリケーションシステムを研究および開発する新しい技術科学です。 1950年代から1960年代に誕生し、半世紀以上の進化を経て、象徴主義、コネクショニズム、行動主体という3つの波が絡み合って発展し、現在では新興の汎用技術として社会を推進しています。人生とあらゆる分野。現段階での一般的な生成 AI のより具体的な定義は次のとおりです: 汎用人工知能 (AGI)、さまざまなタスクや分野で優れたパフォーマンスを発揮できる、幅広い理解能力を備えた人工知能システム。 。 AGI には基本的に、ディープ ラーニング (DL)、ビッグ データ、大規模なコンピューティング能力の 3 つの要素が必要です。
ディープラーニング
ディープ ラーニングは機械学習 (ML) のサブ分野であり、ディープ ラーニング アルゴリズムは人間の脳をモデルにしたニューラル ネットワークです。たとえば、人間の脳には相互接続された何百万ものニューロンが含まれており、それらが連携して情報を学習し、処理します。同様に、深層学習ニューラル ネットワーク (または人工ニューラル ネットワーク) は、コンピューター内で連携して動作する複数の人工ニューロン層で構成されます。人工ニューロンは、数学的計算を使用してデータを処理するノードと呼ばれるソフトウェア モジュールです。人工ニューラル ネットワークは、これらのノードを使用して複雑な問題を解決する深層学習アルゴリズムです。
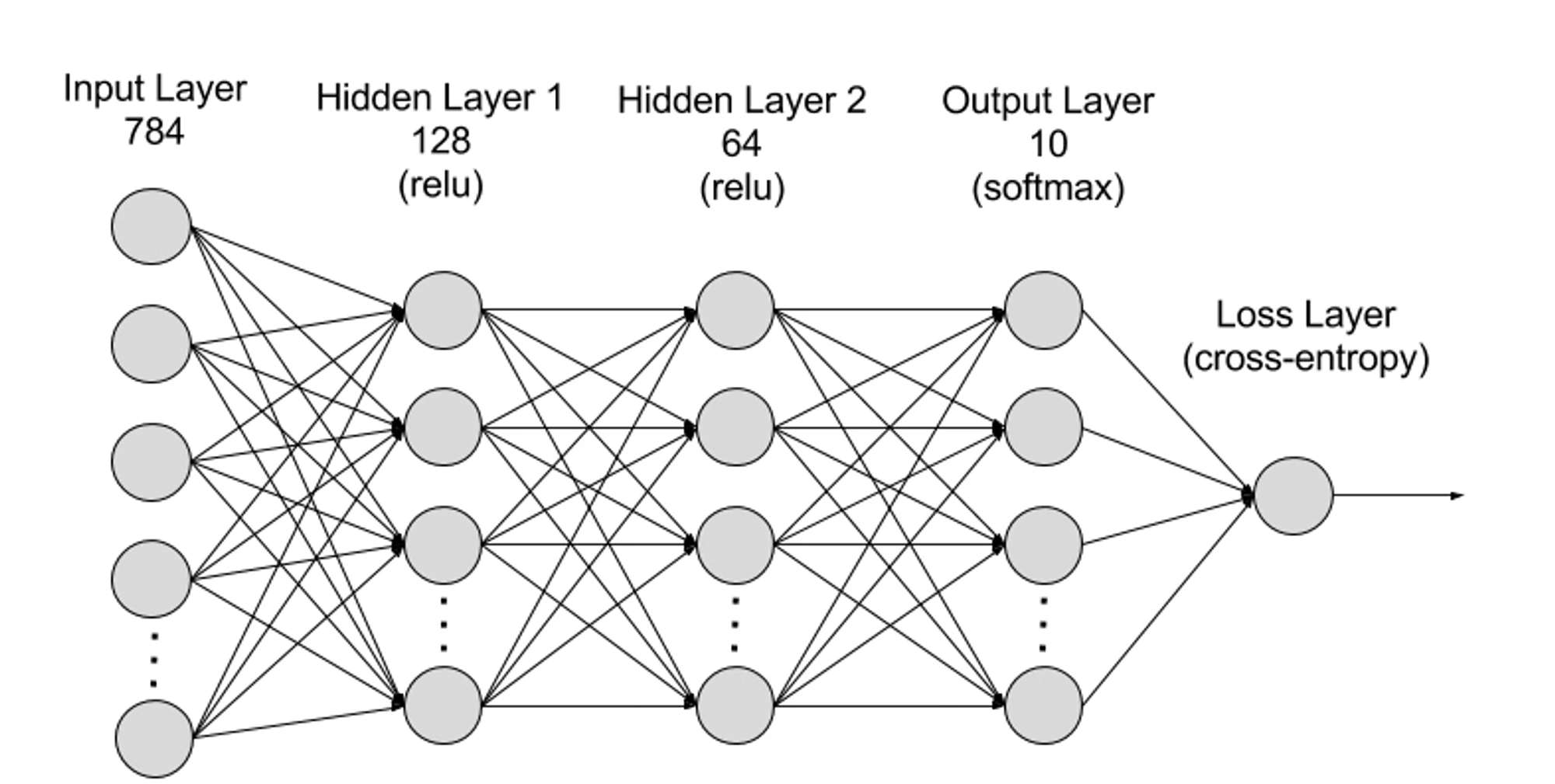
ニューラルネットワークは階層的に入力層、隠れ層、出力層に分けることができ、パラメータは異なる層間で接続されます。
入力層: 入力層はニューラル ネットワークの最初の層であり、外部入力データの受信を担当します。入力層の各ニューロンは、入力データの特徴に対応します。たとえば、画像データを処理する場合、各ニューロンは画像内のピクセル値に対応する場合があります。
隠れ層: 入力層はデータを処理し、それをニューラル ネットワークのさらなる層に渡します。これらの隠れ層はさまざまなレベルで情報を処理し、新しい情報を受け取るとその動作を調整します。深層学習ネットワークには何百もの隠れ層があり、さまざまな観点から問題を分析するために使用できます。たとえば、分類する必要がある未知の動物の画像が与えられた場合、それをすでに知っている動物と比較できます。たとえば、耳の形、足の数、瞳孔の大きさによって、それが何の動物であるかがわかります。ディープ ニューラル ネットワークの隠れ層も同様に機能します。深層学習アルゴリズムが動物の画像を分類しようとしている場合、その隠れ層のそれぞれが動物の異なる特徴を処理し、正確に分類しようとします。
出力層: 出力層はニューラル ネットワークの最後の層であり、ネットワークの出力の生成を担当します。出力層の各ニューロンは、可能な出力カテゴリまたは値を表します。たとえば、分類問題では、各出力層のニューロンがカテゴリに対応する場合がありますが、回帰問題では、出力層には、値が予測結果を表すニューロンが 1 つだけ含まれる場合があります。
パラメーター: ニューラル ネットワークでは、異なるレイヤー間の接続は重みとバイアスのパラメーターによって表され、ネットワークがデータ内のパターンを正確に識別して予測できるようにトレーニング プロセス中に最適化されます。パラメーターの増加により、ニューラル ネットワークのモデル能力、つまりデータ内の複雑なパターンを学習して表現するモデルの能力が向上します。しかし、それに応じてパラメータが増加すると、計算能力の需要も増加します。
ビッグデータ
ニューラル ネットワークを効果的にトレーニングするには、通常、複数のソースからの大量の多様で高品質のデータが必要です。これは、機械学習モデルのトレーニングと検証の基礎です。ビッグデータを分析することで、機械学習モデルはデータ内のパターンと関係を学習して、予測や分類を行うことができます。
大規模なコンピューティング能力
ニューラル ネットワークの多層の複雑な構造、多数のパラメーター、ビッグ データ処理要件、反復トレーニング方法 (トレーニング フェーズでは、モデルを繰り返し反復する必要があり、順伝播と逆伝播を行う必要があります) (活性化関数の計算、損失関数の計算、勾配計算、重みの更新を含む)、高精度のコンピューティング要件、並列コンピューティング機能、最適化と正則化技術、およびモデルの評価と検証のプロセスを総合的に導きました。ディープラーニングにより、AGI の進歩に伴い、大規模な計算能力の要件は毎年約 10 倍に増加しています。これまでの最新モデルである GPT-4 には、1 兆 8,000 億のパラメータが含まれており、1 回のトレーニングにかかるコストは 6,000 万米ドルを超え、必要な計算能力は 2.15 e 25 FLOPS (21,500 兆の浮動小数点計算) です。その後のモデルトレーニングのためのコンピューティングパワーの需要は依然として拡大しており、新しいモデルも追加されています。
AI 計算経済学
将来の市場規模
IDC (International Data Corporation)、Inspur Information、清華大学グローバル産業研究所が共同でまとめた最も権威ある計算である「2022-2023 年グローバル コンピューティング パワー インデックス評価レポート」によると、世界の AI コンピューティング市場規模は 2022 年から 2023 年までに増加すると予想されています。 2022年。生成AIコンピューティング市場は195億米ドルから2026年には346億6000万米ドルに、2022年の8億2000万米ドルから2026年には109億9000万米ドルに成長すると予想されます。ジェネレーティブ AI コンピューティングは、AI コンピューティング市場全体の 4.2% から 31.7% に成長すると予想されます。
コンピューティングパワーの経済独占
AI GPU の生産は NVIDA によって独占されており、非常に高価であり (最新の H 100 は 1 チップあたり 40,000 米ドルで販売されています)、GPU は発売されるとすぐにシリコンバレーの大手企業によって買い占められ、これらのデバイスは自社製品に使用されています 新しいモデルのトレーニング。残りの部分は、クラウド プラットフォームを通じて AI 開発者にレンタルされており、Google、Amazon、Microsoft などのクラウド コンピューティング プラットフォームには、サーバー、GPU、TPU などの多数のコンピューティング リソースがあります。コンピューティング能力は巨大企業によって独占される新たなリソースとなっており、多くの AI 関連開発者は専用の GPU を値上げしなければ購入することさえできず、最新の機器を使用するには AWS や Microsoft のクラウド サーバーをレンタルする必要があります。有価証券報告書を見る限り非常に利益率の高い事業であり、AWSのクラウドサービスの売上総利益率は61%であるのに対し、マイクロソフトの売上総利益率は72%とさらに高い。

それでは、私たちはこの集中的な権限と管理を受け入れ、コンピューティング リソースに対して 72% の利益料金を支払わなければならないのでしょうか? Web2を独占する巨人は次の時代も独占するのだろうか?
分散型 AGI コンピューティング能力の問題
独占禁止に関して言えば、通常、分散化が最適な解決策ですが、既存のプロジェクトから判断すると、DePIN のストレージ プロジェクトと RDNR などのアイドル GPU 利用プロトコルを通じて、AI に必要な大規模なコンピューティング パワーを実現できるでしょうか?答えは「いいえ」です。ドラゴンを倒す道はそれほど単純ではありません。初期のプロジェクトは、AGI のコンピューティング能力を考慮して特別に設計されておらず、実行可能ではありませんでした。チェーンにコンピューティング能力を追加するには、少なくとも次の 5 つの課題に直面する必要があります。
1. 作業の検証: 真にトラストレス コンピューティング ネットワークを構築し、参加者に経済的インセンティブを提供するには、ネットワークに深層学習コンピューティングの作業が実際に実行されているかどうかを検証する方法が必要です。この問題の核心は、深層学習モデルの状態依存性です。深層学習モデルでは、各層の入力は前の層の出力に依存します。これは、その前のすべてのレイヤーを考慮せずに、モデル内の特定のレイヤーだけを検証することはできないことを意味します。各レイヤーの計算は、以前のすべてのレイヤーの結果に基づいています。したがって、特定のポイント (特定のレイヤーなど) で行われた作業を検証するには、モデルの先頭からその特定のポイントまでのすべての作業を実行する必要があります。
2. 市場: AI コンピューティング電力市場は新興市場であるため、コールド スタート問題などの需要と供給のジレンマにさらされており、市場が順調に成長するには、供給と需要の流動性が最初からほぼ一致している必要があります。コンピューティング能力の潜在的な供給を獲得するには、参加者にコンピューティング能力リソースと引き換えに明確なインセンティブを提供する必要があります。市場には、完了したコンピューティング作業を追跡し、それに応じてプロバイダーに適時に支払うメカニズムが必要です。従来のマーケットプレイスでは、仲介業者が管理やオンボーディングなどのタスクを処理しながら、最低支払額を設定することで運営コストを削減します。ただし、このアプローチは市場規模が拡大するとコストが高くなります。経済的に効率的に獲得できるのは供給量のごく一部だけであり、市場がそれ以上成長できずに限られた供給量しか獲得および維持できない限界均衡状態につながります。
3. 停止問題: 停止問題はコンピューティング理論の基本的な問題であり、指定されたコンピューティング タスクが限られた時間内に完了するか、停止しないかを決定する必要があります。この問題は解決不可能です。つまり、すべてのコンピューティング タスクが有限時間内に停止するかどうかを予測できる普遍的なアルゴリズムは存在しません。たとえば、イーサリアムでのスマート コントラクトの実行も同様のダウンタイムの問題に直面しています。つまり、スマート コントラクトの実行にどれだけのコンピューティング リソースが必要になるか、またはスマート コントラクトの実行が妥当な時間内に完了するかどうかを事前に判断することは不可能です。
(深層学習のコンテキストでは、モデルとフレームワークが静的なグラフ構築から動的な構築と実行に切り替わるため、この問題はさらに複雑になります。)
4. プライバシー: プライバシーを意識した設計と開発は、プロジェクト関係者にとって必須です。公開データセットを使用して大量の機械学習研究を実行できますが、モデルのパフォーマンスを向上させ、特定のアプリケーションに適応させるために、通常は独自のユーザー データに基づいてモデルを微調整する必要があります。この微調整プロセスには個人データの処理が含まれる場合があるため、プライバシー保護要件を考慮する必要があります。
5. 並列化: これは、現在のプロジェクトを実行不可能にする重要な要素です。深層学習モデルは通常、独自のアーキテクチャと非常に低い遅延を備えた大規模なハードウェア クラスター上で並行してトレーニングされます。また、分散コンピューティング ネットワーク内の GPU は、頻繁なデータ交換によって導入される必要があります。レイテンシーがあり、最低パフォーマンスの GPU によって制限されます。計算電源が信頼できず、信頼できない場合、異種並列化をどのように実現するかが解決すべき問題ですが、現時点で実現可能な方法は、並列性の高いスイッチトランスなどのトランスモデルを用いて並列化を実現することです。
解決策: AGI コンピューティング電力市場を分散化する現在の試みはまだ初期段階にありますが、分散型ネットワークのコンセンサス設計と、モデルのトレーニングと推論における分散型コンピューティング電力ネットワークの実装を最初に解決したプロジェクトが 2 つあります。 .プロセス。以下では、Gensyn と Together を例として、分散型 AGI コンピューティング電力市場の設計方法と問題を分析します。
Gensyn

Gensyn は、まだ構築段階にある AGI コンピューティングパワー市場であり、分散型ディープラーニングコンピューティングのさまざまな課題を解決し、ディープラーニングの現在のコストを削減することを目的としています。 Gensyn は基本的に、Polkadot ネットワークに基づく第 1 層のプルーフ オブ ステーク プロトコルであり、機械学習タスクのコンピューティングと実行のためにアイドル状態の GPU デバイスと引き換えに、スマート コントラクトを通じてソルバー (Solver) に直接報酬を与えます。
上の質問に戻りますが、真にトラストレス コンピューティング ネットワークを構築する核心は、完了した機械学習作業を検証することにあります。これは非常に複雑な問題であり、複雑性理論、ゲーム理論、暗号化、最適化の交差点の間でバランスを見つける必要があります。
Gensyn は、ソルバーが完了した機械学習タスクの結果を送信するためのシンプルなソリューションを提案しています。これらの結果が正確であることを検証するために、別の独立した検証者が同じ作業を再実行しようとします。このアプローチは、1 つのバリデータのみが再実行を実行するため、単一レプリケーションと呼ぶことができます。これは、元の作業の正確さを検証するための追加の作業が 1 つだけであることを意味します。ただし、作品を検証した人が元の作品の依頼者ではない場合、信頼の問題が残ります。なぜなら、検証者自身が正直ではない可能性があり、彼らの仕事は検証される必要があるからです。これにより、作業を検証する人が元の作業の要求者ではない場合、その作業を検証するために別の検証者が必要になるという潜在的な問題が発生します。ただし、この新しいバリデーターが信頼されていない可能性もあるため、その作業を検証するには別のバリデーターが必要になり、これが永遠に続き、無限のレプリケーション チェーンが作成される可能性があります。ここでは、無限連鎖問題を解決するために 3 つの重要な概念を導入し、それらを織り交ぜて 4 つの役割を持つ参加者システムを構築する必要があります。
確率的学習証明: 勾配ベースの最適化プロセスのメタデータを使用して、完了した作業の証明書を作成します。特定の段階を複製することで、これらの証明書を迅速に検証して、作業が期待どおりに完了したことを確認できます。
グラフベースの正確な位置特定プロトコル: 複数の粒度、グラフベースの正確な位置特定プロトコル、および相互評価の一貫した実行を使用します。これにより、検証作業を再実行して比較して一貫性を確保し、最終的にはブロックチェーン自体によって確認することができます。
Truebit スタイルのインセンティブ ゲーム: ステーキングとスラッシュを使用して、経済的に合理的なすべての参加者が誠実に行動し、意図したタスクを実行することを保証するインセンティブ ゲームを構築します。
参加者システムは、提出者、解決者、検証者、および報告者で構成されます。
提出者:
送信者は、計算されるタスクを提供し、完了した作業単位に対して支払いを行うシステムのエンド ユーザーです。
ソルバー:
ソルバーはシステムの主要な作業者であり、モデルのトレーニングを実行し、検証者によってチェックされる証明を生成します。
検証者:
ベリファイアは、非決定論的なトレーニング プロセスを決定論的な線形計算にリンクし、ソルバーの証明の一部を複製し、予想されるしきい値との距離を比較するための鍵となります。
内部告発者:
内部告発者は最後の防衛線であり、バリデーターの仕事をチェックし、寛大な報奨金の支払いを期待して異議申し立てを発行します。
システム運用
このプロトコルによって設計されたゲーム システムの操作には、タスクの送信から最終検証までの完全なプロセスを完了するために、4 つの主要な参加者の役割をカバーする 8 つの段階が含まれます。
1. タスクの送信: タスクは、次の 3 つの特定の情報で構成されます。
タスクとハイパーパラメータを説明するメタデータ。
モデルバイナリ(または基本スキーマ)。
公的にアクセス可能な、事前処理されたトレーニング データ。
2. タスクを送信するには、送信者はタスクの詳細を機械可読形式で指定し、モデル バイナリ (または機械可読スキーマ) および前処理されたトレーニング データの公的にアクセス可能な場所とともにチェーンに送信します。パブリック データは、AWS S3 などの単純なオブジェクト ストレージ、または IPFS、Arweave、Subspace などの分散ストレージに保存できます。
3. プロファイリング: プロファイリング プロセスでは、学習検証の証明のためのベースライン距離のしきい値を決定します。バリデーターは分析タスクを定期的にクロールし、学習の証明比較のための変異しきい値を生成します。しきい値を生成するために、検証者はさまざまなランダム シードを使用してトレーニングの一部を決定論的に実行および再実行し、独自の証明を生成してチェックします。このプロセス中に、検証者は検証ソリューションとして使用できる非決定的作業の全体的な予想距離のしきい値を確立します。
4. トレーニング: 分析後、タスクはパブリック タスク プール (イーサリアムの Mempool と同様) に入ります。タスクを実行するソルバーを選択し、タスク プールからタスクを削除します。ソルバーは、送信者によって送信されたメタデータと、提供されたモデルおよびトレーニング データに基づいてタスクを実行します。トレーニング タスクを実行するとき、ソルバーは定期的にチェックポイントを作成し、パラメーターを含むトレーニング プロセスからのメタデータを保存することで学習の証明も生成します。これにより、検証者は次の最適化ステップをできるだけ正確に複製できます。
5. プルーフの生成: ソルバーは、モデルの重みまたは更新と、重みの更新を生成するために使用されるサンプルを識別するトレーニング データ セットへの対応するインデックスを定期的に保存します。チェックポイントの頻度を調整して、より強力な保証を提供したり、ストレージ領域を節約したりできます。証明は「積み重ね」ることができます。つまり、証明は、重みの初期化に使用されるランダムな分布から、または独自の証明を使用して生成された事前訓練された重みから開始できます。これにより、プロトコルは、より具体的なタスクに合わせて微調整できる、実証済みの事前トレーニングされたベース モデル (つまり、ベース モデル) のセットを構築できます。
6. 証明の検証: タスクが完了すると、ソルバーはタスクの完了をチェーンに登録し、検証者がアクセスできる公開された場所にその学習証明を表示します。検証者はパブリック タスク プールから検証タスクを取得し、計算作業を実行して証明の一部を再実行し、距離の計算を実行します。結果として得られた距離は、検証が証明と一致するかどうかを判断するために (分析フェーズ中に計算されたしきい値とともに) チェーンによって使用されます。
7. グラフベースのピンポイントチャレンジ:学習証明を検証した後、内部告発者は検証者の作業をコピーして、検証作業自体が正しく行われたかどうかを確認できます。内部告発者が、検証が(悪意があるかどうかにかかわらず)不正に実行されたと信じる場合、報酬を受け取るために契約仲裁に異議を申し立てることができます。この報酬は、ソルバーとバリデーターのデポジット (真陽性の場合)、または宝くじの賞金プール (偽陽性の場合) から得られ、チェーン自体を使用して仲裁が実行されます。内部告発者(彼らの場合は検証者)は、適切な報酬を受け取ることが期待できる場合にのみ、業務を検証し、その後異議を申し立てます。実際には、これは、内部告発者が、他のアクティブな内部告発者の数に基づいて(つまり、ライブデポジットと異議申し立てを使用して)ネットワークに参加したり脱退したりすることが期待されることを意味します。したがって、内部告発者にとって予想されるデフォルトの戦略は、他の内部告発者の数が少ないときにネットワークに参加し、デポジットを預け、アクティブなタスクをランダムに選択し、検証プロセスを開始することです。最初のタスクが終了すると、別のランダムなアクティブなタスクを取得し、内部告発者の数が決められた支払いしきい値を超えるまで繰り返し、その後ネットワークを離れます (あるいは、ハードウェアの機能に応じてネットワークに切り替えて別のタスクを実行する可能性が高くなります)状況が再び逆転するまで、役割 - 検証者または解決者)。
8. 契約の仲裁: バリデーターが内部告発者から異議を申し立てられた場合、バリデーターはチェーンのプロセスに入り、争点となっている操作または入力の場所を見つけます。最終的にチェーンは最終的な基本操作を実行し、異議申し立てが正当であるかどうかを判断します。合理的な。内部告発者の正直さを保ち、バリデーターのジレンマを克服するために、ここでは定期的な強制エラーとジャックポットの支払いが導入されています。
9. 決済: 決済プロセス中、参加者は確率と確実性のチェックの結果に基づいて支払いを受けます。シナリオが異なれば、以前の検証とチャレンジの結果に基づいて支払いも異なります。作業が正しく実行され、すべてのチェックに合格したとみなされた場合、ソリューションプロバイダーと検証者は、実行されたアクションに基づいて報酬を受け取ります。
プロジェクトの簡単なレビュー
Gensyn は検証層とインセンティブ層で素晴らしいゲーム システムを設計しており、ネットワーク内の分岐点を見つけることでエラーを迅速に特定できますが、現在のシステムにはまだ多くの詳細が欠けています。たとえば、しきい値を高く設定しすぎずに、報酬と罰が適切であることを保証するパラメーターを設定するにはどうすればよいでしょうか?ゲーム内の極限状況とソルバーのさまざまな計算能力を考慮したことがありますか?現在のバージョンのホワイトペーパーには異種並列処理についての詳細な説明はなく、現時点では Gensyn の実現にはまだ長い道のりがあります。
Together.ai
Together は、大規模モデルに重点を置き、分散型 AI コンピューティング パワー ソリューションに注力するオープンソース企業であり、誰でも、どこからでも AI にアクセスして使用できることを願っています。厳密に言えば、Togetter はブロックチェーン プロジェクトではありませんが、このプロジェクトは当初、分散型 AGI コンピューティング ネットワークにおける遅延問題を解決しました。したがって、次の記事は Together のソリューションを分析するだけであり、プロジェクトを評価するものではありません。
分散型ネットワークがデータセンターよりも 100 倍遅い場合、大規模モデルのトレーニングと推論をどのように達成すればよいでしょうか?
分散化された状況では、ネットワークに参加している GPU デバイスの分布がどのようになるかを想像してみましょう。これらのデバイスはさまざまな大陸や都市に分散されており、デバイスを接続する必要があり、接続の遅延と帯域幅も異なります。以下の図に示すように、デバイスが北米、ヨーロッパ、アジアに分散されており、デバイス間の帯域幅と遅延が異なる分散状況がシミュレートされています。では、直列に接続するにはどうすればよいのでしょうか?
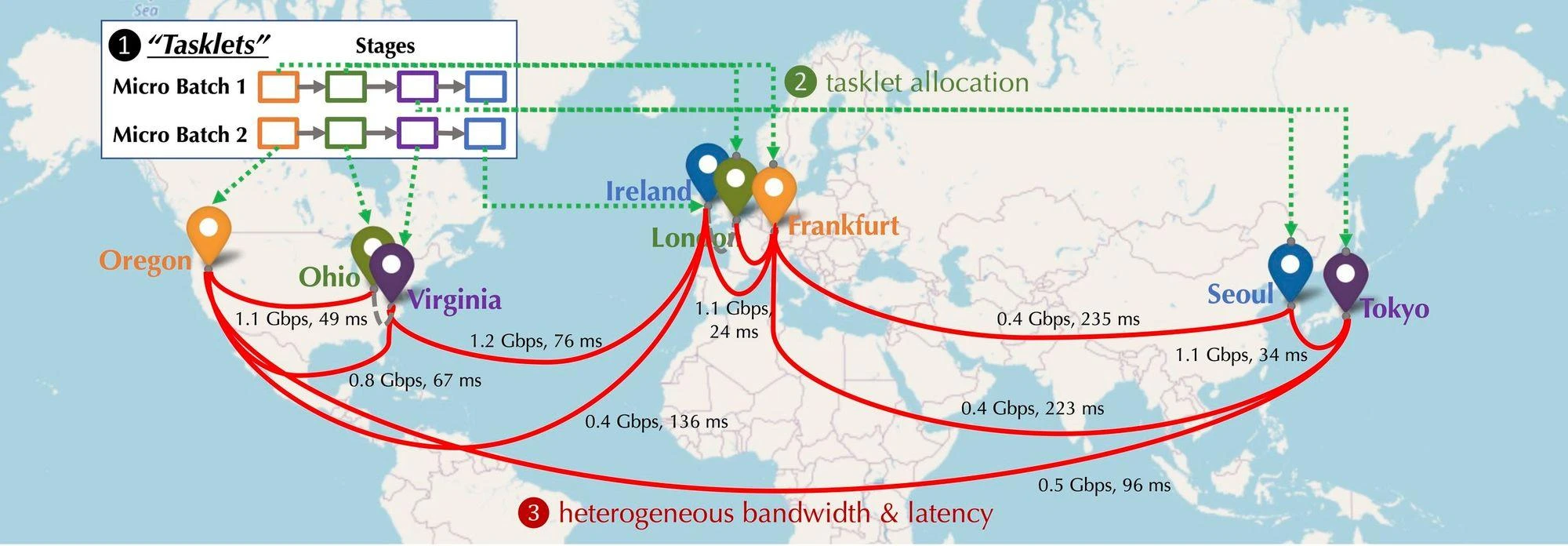
分散トレーニング コンピューティング モデリング:下図は複数のデバイス上での基本的なモデルの学習を示したもので、通信の種類としては順方向アクティベーション(Forward Activation)、逆方向グラディエント(Backward Gradient)、水平通信の3種類があります。
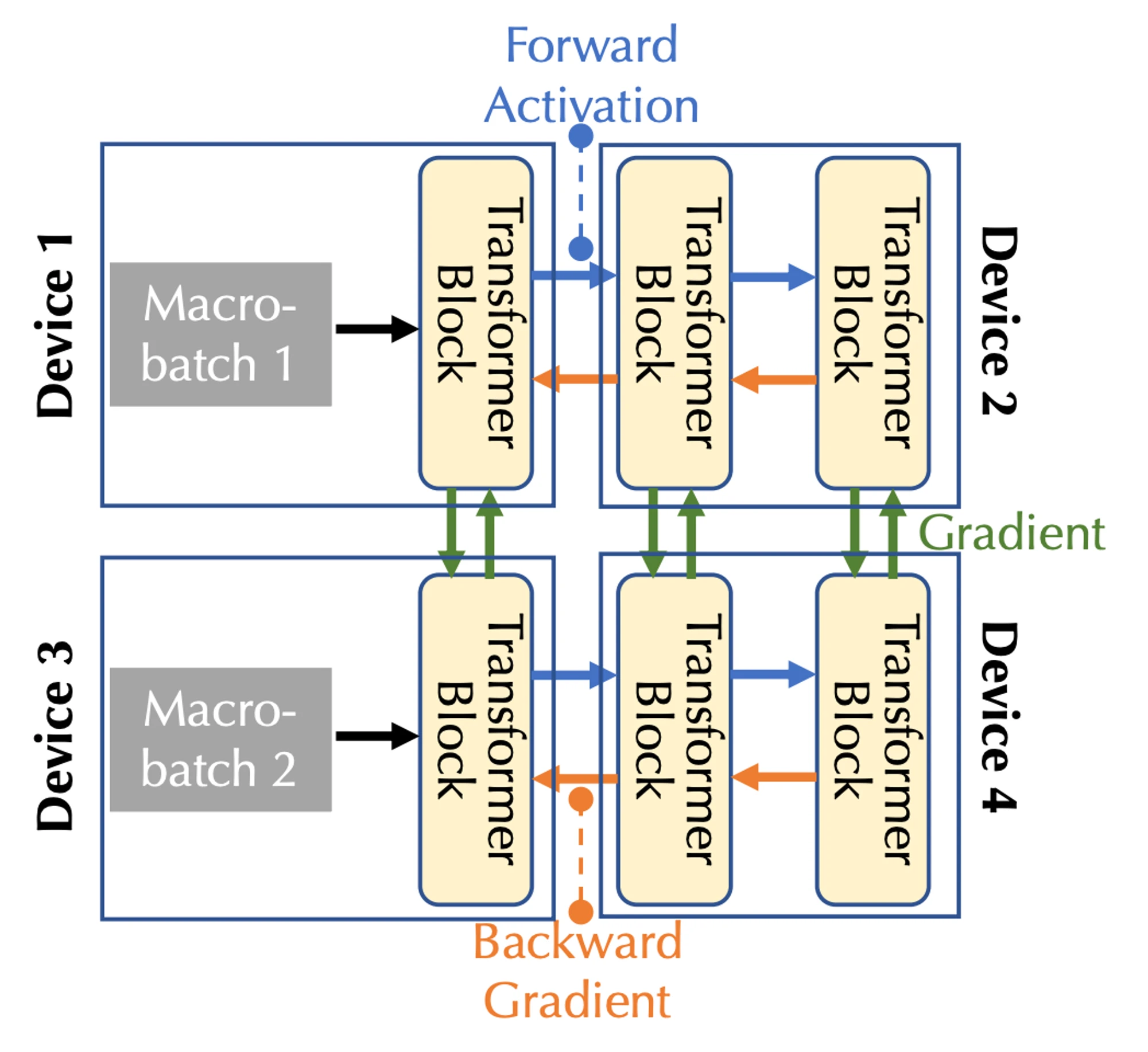
通信帯域幅と遅延を組み合わせて、パイプライン並列処理とデータ並列処理という 2 つの形式の並列処理を考慮する必要があります。これは、マルチデバイスの場合の 3 種類の通信に対応します。
パイプライン並列処理では、モデルのすべてのレイヤーがステージに分割され、各デバイスが 1 つのステージ (複数の Transformer ブロックなどのレイヤーの連続シーケンス) を処理します。フォワード パスではアクティベーションが次のステージに渡され、バックワード パスではアクティベーションが次のステージに渡されます。 pass の場合、活性化勾配は前のステージに渡されます。
データ並列処理では、デバイスは異なるマイクロバッチの勾配を独立して計算しますが、これらの勾配を同期するには通信が必要です。
スケジュールの最適化:
分散環境では、トレーニング プロセスに通信の制約が生じることがよくあります。スケジューリング アルゴリズムは通常、大量の通信を必要とするタスクをより高速な接続を持つデバイスに割り当てます。タスク間の依存関係とネットワークの異質性を考慮して、最初に特定のスケジューリング戦略のコストをモデル化する必要があります。基本モデルのトレーニングにかかる複雑な通信コストを把握するために、Togetter は新しい公式を提案し、グラフ理論を通じてコスト モデルを 2 つのレベルに分解しました。
グラフ理論は、主にグラフ (ネットワーク) の特性と構造を研究する数学の一分野です。グラフは頂点 (ノード) とエッジ (ノードを接続する線) で構成されます。グラフ理論の主な目的は、グラフの接続性、グラフの色、グラフ内のパスとサイクルの特性など、グラフのさまざまな特性を研究することです。
最初のレベルはバランスの取れたグラフ分割です (サブセット間のエッジの数を最小限に抑えながら、グラフの頂点のセットをいくつかの等しいまたはほぼ同じサイズのサブセットに分割します。この分割では、各サブセットがパーティションを表し、通信コストを削減します)パーティション間のエッジを最小限に抑えることによって)問題を解決し、データ並列処理の通信コストに対応します。
第 2 レベルは、結合グラフ マッチングと巡回セールスマン問題です (結合グラフ マッチングと巡回セールスマン問題は、グラフ マッチングと巡回セールスマン問題の要素を組み合わせた組み合わせ最適化問題です。グラフ マッチング問題は、次のようなグラフ内の一致を見つけることです。ある種のコストの最小化または最大化。巡回セールスマン問題は、パイプライン並列処理の通信コストに対応する、グラフ内のすべてのノードを訪問する最短パスを見つけることです。
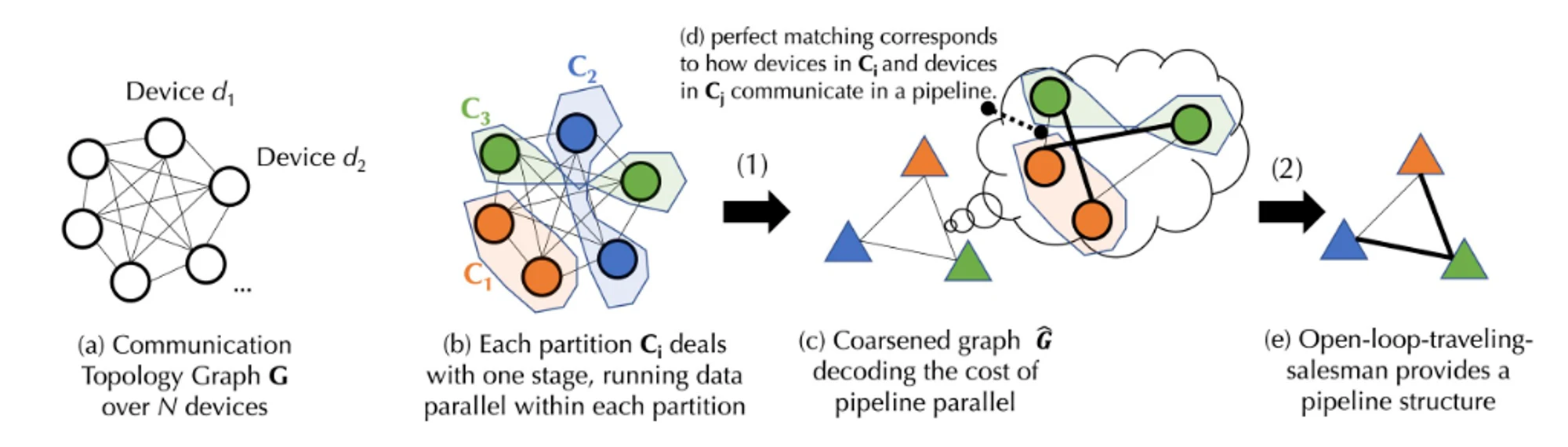 実際の実装プロセスには複雑な計算式が含まれるため、上の図は概略的なプロセス図です。以下、理解を容易にするために、図のプロセスをより簡単に説明しますが、詳細な実装プロセスについては、Togetter 公式 Web サイトのドキュメントを参照してください。
実際の実装プロセスには複雑な計算式が含まれるため、上の図は概略的なプロセス図です。以下、理解を容易にするために、図のプロセスをより簡単に説明しますが、詳細な実装プロセスについては、Togetter 公式 Web サイトのドキュメントを参照してください。
N 個のデバイスを含むデバイス セット D があり、それらの間の通信には不確実な遅延 (A 行列) と帯域幅 (B 行列) があるとします。デバイス セット D に基づいて、最初にバランスの取れたグラフ パーティションを生成します。各パーティションまたはデバイス グループ内のデバイスの数はほぼ等しく、すべて同じパイプライン ステージを処理します。これにより、データが並列化されるときに、各デバイス グループが同じ量の作業を実行することが保証されます。 (データ並列処理とは、同じタスクを実行する複数のデバイスを指しますが、パイプライン ステージは、特定の順序で異なるタスク ステップを実行するデバイスを指します)。通信の遅延と帯域幅に基づいて、式を使用して、デバイスのグループ間でデータを送信する「コスト」を計算できます。バランスの取れた各デバイス グループがマージされ、完全に接続された大まかなグラフが生成されます。ここで、各ノードはパイプラインのステージを表し、エッジは 2 つのステージ間の通信コストを表します。通信コストを最小限に抑えるために、マッチング アルゴリズムを使用して、どのデバイスのグループが連携して動作するかを決定します。
さらに最適化するには、この問題を開ループ巡回セールスマン問題としてモデル化し (開ループとは、パスの開始点に戻る必要がないことを意味します)、すべてのデバイス間でデータを送信するための最適なパスを見つけることもできます。最後に、Togetter は革新的なスケジューリング アルゴリズムを使用して、特定のコスト モデルに最適な割り当て戦略を見つけます。これにより、通信コストを最小限に抑え、トレーニング スループットを最大化します。実際の測定によると、このスケジューリングの最適化によりネットワークが 100 倍遅くなったとしても、エンドツーエンドのトレーニング スループットは約 1.7 ~ 2.3 倍遅くなるだけです。
通信圧縮の最適化:
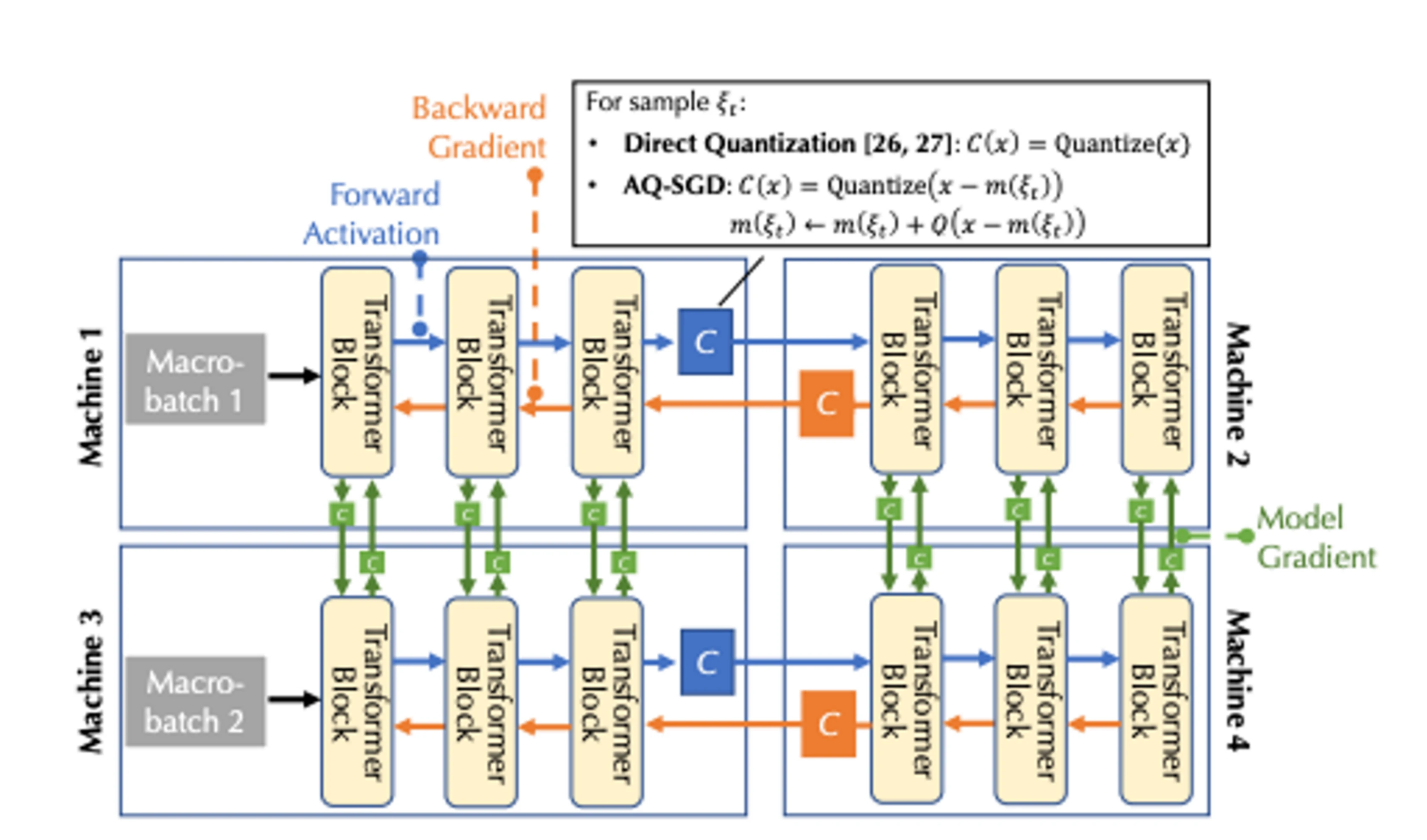
通信圧縮の最適化のために、Togetter は AQ-SGD アルゴリズムを導入しました (詳細な計算プロセスについては、論文「保証付きのアクティベーション圧縮を使用した低速ネットワーク上の言語モデルの微調整」を参照してください)。低速ネットワークでのパイプライン並列処理の実現 トレーニングの通信効率の問題を解決するために設計された新しいアクティブ圧縮テクノロジー。アクティビティ値を直接圧縮する以前の方法とは異なり、AQ-SGD は、異なる期間における同じトレーニング サンプルのアクティビティ値の変化を圧縮することに焦点を当てています。このユニークな方法は、興味深い「自己実行」ダイナミクスを導入します。トレーニングが安定するにつれて、アルゴリズムのパフォーマンスは徐々に向上すると予想されます。 AQ-SGD アルゴリズムは厳密な理論分析を経て、特定の技術的条件下で優れた収束率と、誤差が制限された量子化関数を備えていることが証明されています。このアルゴリズムは効率的に実装できるだけでなく、活性値を保存するためにより多くのメモリと SSD を使用する必要がありますが、エンドツーエンドのランタイム オーバーヘッドも追加しません。シーケンス分類と言語モデリング データセットに関する広範な実験を通じて検証された AQ-SGD は、収束パフォーマンスを犠牲にすることなくアクティビティ値を 2 ~ 4 ビットに圧縮できます。さらに、AQ-SGD は、最先端の勾配圧縮アルゴリズムと統合して、「エンドツーエンド通信圧縮」、つまりモデル勾配、フォワード アクティビティ値、および逆勾配は低精度に圧縮されるため、分散トレーニングの通信効率が大幅に向上します。集中型コンピューティング ネットワーク (10 Gbps など) での圧縮なしのエンドツーエンドのトレーニング パフォーマンスと比較すると、現時点では 31% 遅いだけです。スケジューリングの最適化に関するデータと組み合わせると、集中型コンピューティング パワー ネットワークと集中型コンピューティング パワー ネットワークの間にはまだ一定のギャップがありますが、将来的に追いつく期待は比較的高いです。
結論
AI の波がもたらす配当期において、AGI コンピューティングパワー市場は間違いなく、多くのコンピューティングパワー市場の中で最も大きな可能性と最も需要のある市場です。ただし、開発の難易度、ハードウェア要件、財務要件も最も高くなります。上記の 2 つのプロジェクトの状況から判断すると、AGI コンピューティング電力市場の実現にはまだ一定の距離があります。真の分散型ネットワークは理想的な状況よりもはるかに複雑です。クラウドの巨人と競争するには明らかに十分ではありません。現在のところ。この記事を書いているときに、初期段階 (PPT 段階) の小規模プロジェクトの一部が、難易度の低い推論段階や小規模モデルに焦点を当てるなど、いくつかの新しいエントリ ポイントを模索し始めていることにも気づきました。より実践的な試み。
AGI コンピューティング パワー市場が最終的にどのように実現されるかはまだ不透明であり、多くの課題に直面していますが、長期的には、AGI コンピューティング パワーの分散化とパーミッションレスな重要性が重要であり、推論とトレーニングの権利が集中すべきではありません。少数の中央集権的な巨人に。なぜなら、人類は新たな「宗教」や新たな「教皇」を必要としておらず、ましてや高額な「会費」を支払う必要もないからである。
参考文献
1.Gensyn Litepaper:https://docs.gensyn.ai/litepaper/
2.NeurIPS 2022: Overcoming Communication Bottlenecks for Decentralized Training :https://together.ai/blog/neurips-2022-overcoming-communication-bottlenecks-for-decentralized-training-12
3.Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees:https://arxiv.org/abs/2206.01299
4.The Machine Learning Compute Protocol and our future:https://mirror.xyz/gensyn.eth/_K2v2uuFZdNnsHxVL3Bjrs4GORu3COCMJZJi7_MxByo
5.Microsoft:Earnings Release FY 23 Q2:https://www.microsoft.com/en-us/Investor/earnings/FY-2023-Q2/performance
6. AI 入場チケットを争う: BAT、Byte、Meituan が GPU を争う:https://m.huxiu.com/article/1676290.html
7.IDC: 2022 ~ 2023 年の世界的なコンピューティング能力指数評価レポート:https://www.tsinghua.edu.cn/info/1175/105480.htm
8.国盛証券の大規模モデルトレーニングの推定:https://www.fxbaogao.com/detail/3565665
9. 情報の翼: コンピューティング能力と AI の関係は何ですか? :https://zhuanlan.zhihu.com/p/627645270





