




原作者:YBB Capital 研究員 Zeke

1. 注目から始まる新しいものへの好みと古いものへの嫌悪感
この 1 年で、アプリケーション層の物語がインフラストラクチャの爆発のスピードに追いつかなくなったため、暗号化の分野は徐々に注目のリソースを争うゲームになってきました。 Silly Dragon から Goat まで、Pump.fun から Clanker まで、注目を集める戦いは激化しています。最もありきたりな人目を引く実現から始まり、すぐに注目を求める需要者と供給者が統合されるプラットフォーム モデルに変化し、その後、シリコンベースの生物が新しいコンテンツ プロバイダーになりました。ミームコインのさまざまな奇妙なキャリアの中で、ついに個人投資家とVCが合意に達することを可能にする存在、それがAIエージェントです。

注目というのは究極的にはゼロサムゲームですが、確かに憶測が物事を乱暴に動かす可能性があります。 UNIに関する記事では、ブロックチェーンの最後の黄金時代の始まりを振り返りましたが、DeFiの急速な成長の理由は、数千から数十のさまざまなマイニングプールで実行されたCompound Financeによって始まったLPマイニング時代に由来しています。何千ものApyが出入りするのは、当時のチェーン上での最も原始的なゲーム方法でしたが、最終的な状況はさまざまなマイニングプールが崩壊し、羽毛で覆われたということでした。しかし、金鉱業者の狂気の流入により、DeFiはついに純粋な投機から脱却し、決済、取引、アービトラージ、ステーキングなどのあらゆる面でユーザーを満足させる成熟した軌道を形成しました。 AI Agent も現段階でこの野蛮な段階を経ています。私たちが模索しているのは、Crypto が AI をどのようにより適切に統合し、最終的にアプリケーション層を新たな高みに押し上げることができるかということです。
2. インテリジェントエージェントはどのようにして自律的になるのでしょうか?
前回の記事では、AI Meme: Truth Terminal の起源と AI Agent の今後の展望について簡単に紹介しましたが、この記事ではまず AI Agent 自体に焦点を当てます。
AI エージェントの定義から始めましょう。エージェントは、AI の分野では古い用語ですが、定義が明確ではありません。主に自律性を重視しています。つまり、環境を認識して反映できる AI はすべてエージェントと呼ぶことができます。今日の定義では、AI エージェントはインテリジェント エージェントに近く、人間の意思決定を模倣する大規模なモデルのシステムをセットアップするものであり、学術界ではこのシステムが AGI (汎用人工知能) への最も有望な方法とみなされています。 。
初期の GPT バージョンでは、大きなモデルが非常に人間に似ていることをはっきりと認識できましたが、多くの複雑な質問に答えるとき、大きなモデルはいくつかの適当な答えしか与えることができませんでした。本質的な理由は、当時の大規模なモデルが因果関係ではなく確率に基づいていたことです。第二に、人間のツール、記憶、計画などの能力が欠如しており、AI エージェントがこれらの欠陥を補うことができます。つまり、式でまとめると、AI Agent(インテリジェントエージェント)=LLM(大規模モデル)+Planning(計画)+Memory(記憶)+Tools(ツール)となります。
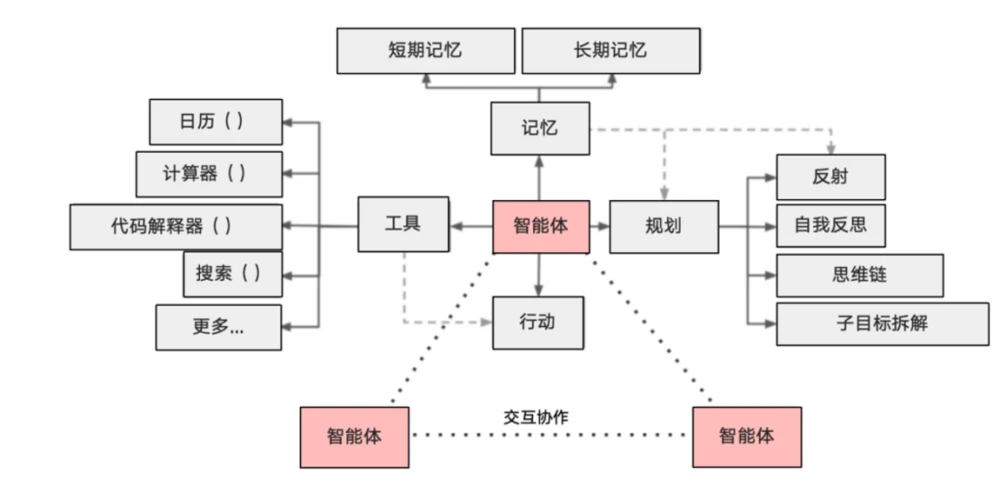
プロンプトワード(プロンプト)に基づく大きなモデルは、より静的な人間に似ており、それを入力すると生命が吹き込まれ、インテリジェントエージェントのターゲットはより現実的な人間になります。サークル内の現在のインテリジェント エージェントは主に、Meta のオープン ソース Llama 70 b または 405 b バージョンに基づいて微調整されたモデルです (どちらも異なるパラメータを持っています)。API アクセス ツールを記憶して使用する機能がありますが、人間の助けが必要な場合があります。または、他の側面からのインプット (他のエージェントとの対話や協力を含む) から、今日でもサークル内の主要なエージェントが KOL の形でソーシャル ネットワーク上に存在していることがわかります。インテリジェント エージェントをより人間らしくするには、計画とアクションの能力にアクセスする必要があり、計画におけるサブ思考の連鎖が特に重要です。
3. 思考の連鎖 (CoT)
思考連鎖 (CoT) の概念は、2022 年に Google によって出版された論文「Chain-of-Thought Prompting Elicits Reasoning in Large Language Models」で初めて登場しました。この論文では、一連の中間言語モデルを生成することでモデルを強化できると指摘されています。推論ステップ。推論機能は、モデルが複雑な問題をよりよく理解し、解決するのに役立ちます。

一般的な CoT プロンプトは、明確な指示、タスクの説明、論理的根拠、タスクの解決をサポートする理論的基礎または原則的な例、および具体的なソリューションのデモンストレーションの 3 つの部分で構成されます。この構造化されたアプローチは、モデルがタスクの要件を理解し、論理的推論を通じて徐々にそれらにアプローチするのに役立ちます。 . に答えることで、問題解決の効率と精度が向上します。 CoT は、数学的な問題解決、プロジェクト レポートの作成、その他の単純なタスクなど、詳細な分析と複数のステップから成る推論を必要とするタスクに特に適しています。CoT は明らかな利点をもたらさないかもしれませんが、複雑なタスクの場合はパフォーマンスを大幅に向上させることができます。段階的な解決戦略を通じてモデルのエラー率を削減し、タスク完了の品質を向上させます。
AI エージェントを構築する際、CoT は受信した情報を理解し、それに応じて合理的な意思決定を行う必要があります。CoT は、エージェントが順序立てて思考する方法を提供することで、入力情報を効果的に処理および分析し、分析結果を変換するのに役立ちます。このアプローチは、エージェントの意思決定の信頼性と効率を高めるだけでなく、意思決定プロセスの透明性を高め、タスクを小さなステップに分解することでエージェントの行動をより予測し、追跡しやすくします。情報過多によって引き起こされる誤った決定を減らすために、各意思決定ポイントが慎重に考慮されます。CoT により、エージェントの意思決定プロセスがより透明になり、ユーザーがエージェントの意思決定の根拠を理解しやすくなります。 CoT は、環境と対話する際に、エージェントが継続的に新しい情報を学習し、行動戦略を調整できるようにします。
効果的な戦略として、CoT は大規模な言語モデルの推論能力を向上させるだけでなく、よりインテリジェントで信頼性の高い AI エージェントを構築する上でも重要な役割を果たします。 CoT を活用することで、研究者や開発者は、複雑な環境により適応し、高度な自律性を備えたインテリジェント システムを作成できます。 CoT は、実際のアプリケーション、特に複雑なタスクを処理する際に、タスクを一連の小さなステップに分解することで、タスク解決の精度が向上するだけでなく、モデルの解釈可能性と制御可能性も向上します。 。問題解決に対するこの段階的なアプローチにより、複雑なタスクに直面したときに情報が多すぎたり複雑すぎたりすることによって引き起こされる誤った決定を大幅に減らすことができます。同時に、このアプローチにより、ソリューション全体のトレーサビリティと検証可能性も向上します。
CoT の中核となる機能は、計画、行動、観察を統合し、推論と行動の間のギャップを埋めることです。この思考モードにより、AI エージェントは、遭遇する可能性のある異常な状況を予測する際に効果的な対策を立てることができるほか、外部環境と対話しながら新しい情報を蓄積し、事前に設定された予測を検証し、新しい推論の根拠を提供することができます。 CoT は、AI エージェントが複雑な環境で効率的な作業効率を維持できるようにする、強力な精度と安定性を備えたエンジンのようなものです。
4. 疑似欲求を修正する
Crypto は AI テクノロジー スタックのどの側面と統合されますか?昨年の記事では、コンピューティング能力とデータの分散化が中小企業や個人の開発者がコストを節約するための重要なステップであると信じていましたが、今年の Coinbase が主催する Crypto x AI のセグメント化されたトラックでは、さらに詳細な区分が見られました。
(1) コンピューティング層 (AI 開発者にグラフィックス プロセッシング ユニット (GPU) リソースを提供することに重点を置いたネットワークを指します)。
(2) データ層 (AI データ パイプラインの分散アクセス、オーケストレーション、検証をサポートするネットワークを指します)。
(3) ミドルウェア層 (AI モデルまたはエージェントの開発、展開、ホスティングをサポートするプラットフォームまたはネットワークを指します)。
(4) アプリケーション層 (B2B または B2C を問わず、オンチェーン AI メカニズムを利用するユーザー指向の製品を指します)。
これら 4 つの部門層にはそれぞれ壮大なビジョンがあり、その目標はすべてシリコンバレーの巨大企業がインターネットを支配する次の時代と戦うことです。私が昨年述べたように、シリコンバレーの巨大企業によるコンピューティング能力とデータの独占的管理を本当に受け入れる必要があるのでしょうか?彼らの独占下にあるクローズドソースの大きなモデルは、その内部がブラックボックスです。科学は今日の人類の最も人気のある宗教です。将来、大きなモデルによって答えられるすべての文が、多くの人々によって真実とみなされるでしょう。真実はどうやって検証するべきですか?シリコンバレーの巨人のビジョンによれば、インテリジェントエージェントは最終的に、財布で支払う権利や端末を使用する権利など、想像を超えた権限を持つようになるでしょう。人々に悪意がないことを保証するにはどうすればよいでしょうか。
分散化が唯一の答えですが、場合によっては、これらの壮大なビジョンにどれだけの買い手がいるのかを総合的に合理的に検討する必要があるでしょうか?以前は、商業的な閉ループを考慮せずに、理想化によって引き起こされたエラーを補うためにトークンを使用できました。今日の状況は非常に深刻であり、Crypto x AI は、実際の状況に基づいて設計する必要があります。たとえば、パフォーマンスが失われ、不安定になった場合に、コンピューティング パワー レイヤーの両端をどのようにバランスさせることができるでしょうか。集中型クラウドの競争力に匹敵する。データ レイヤー プロジェクトには実際のユーザーが何人いますか? 提供されたデータの実際の有効性を確認するにはどうすればよいですか? このデータを必要とする顧客はどのような人ですか?他の 2 つのレベルにも同じことが当てはまります。この時代では、一見正しいと思われる疑似ニーズはそれほど必要ありません。
5.ミームはSocialFiを使い果たしました
最初の段落で述べたように、Meme は Web3 に準拠した SocialFi フォームを超高速で開発しました。 Friend.tech は、このラウンドのソーシャル アプリケーションを立ち上げた最初の Dapp でしたが、熱心なトークン設計に敗れました。 Pump.fun は、トークンやルールのない純粋なプラットフォームの実現可能性を検証しました。 Pump.fun では、ミームの投稿、ライブブロードキャスト、メッセージの送信、取引がすべて無料で行えます。これは、課金対象が異なることと、Pupm.fun のゲームプレイがより Web3 であることを除いて、今日の YouTube や Instagram などのソーシャル メディアのアテンション エコノミー モデルと基本的に一致しています。

Base の Clanker はすべてのマスターです。エコロジーによって個人的に管理されている統合エコロジーのおかげで、Base は完全な内部閉ループを形成するための補助として独自のソーシャル Dapp を持っています。 Intelligent Meme は Meme Coin の 2.0 形式です。人々は常に新しいアイデアを探しており、トレンドから判断すると、Pump.fun が現在最前線に立っています。シリコンベースの生物のランダムなアイデアに取って代わられるのは時間の問題です。炭素ベースの生物に関する下品なミーム。
私は Base についてこれまで何度も言及してきましたが、毎回異なる文脈で言及されています。Base はタイムライン上で最初に動くことはありませんが、常に勝者です。
6. インテリジェントエージェントには他に何があるのでしょうか?
実用的な観点から見ると、従来の AI 分野におけるエージェントの構築から判断すると、エージェントを分散化することは将来的に長期間にわたって不可能であり、単に推論プロセスを分散化し、オープンソース化するだけでは問題を解決できません。 Web2 コンテンツにアクセスするには、さまざまな API にアクセスする必要があり、そのランニング コストが非常に高くつくのが通常です。おそらくUNIのような適切な統合形態が現れるまで、私たちは長い移行期間を経ることになるでしょう。しかし、前回の記事と同様に、私たちの業界における Cex の存在と同じように、インテリジェント エージェントは業界に大きな影響を与えるだろうと今でも考えています。これは間違っていますが重要です。
スタンフォードとマイクロソフトが先月発行した記事「AI エージェントの概要」では、医療業界、インテリジェント マシン、仮想世界におけるエージェントのアプリケーションについて詳しく説明されており、この記事の付録にはすでに多くの GPT-4 V がエージェントとして含まれています。トップクラスの AAA ゲーム開発のテスト ケースに参加します。
分散化との組み合わせの速度を主張する必要はありません。私は、知的エージェントが完成させることができる最初のパズルのピースが、ボトムアップの能力と速度であることを願っています。適切な段階で、次期UNIとしてどうするか検討していきます。
参考文献
大型モデルの「創発」の思考連鎖とはどのような能力なのか?作者:脳極体
エージェントを 1 つの記事で理解すると、大規模モデルの次の目的地になります。著者: LinguaMind





