





模組化運算層 RaaS 平台Lumoz 在剛結束的第三輪激勵測試網中取得階段性成果。市場層面,測試網活動獲得超100 萬用戶、 30 多個頭部生態專案方等關注與支持,市場熱度、討論度、社群規模再創新高;技術層面,Lumoz 團隊也同時對ZK-POW 演算法進行更深層的優化,目前也取得有效突破,目前可以有效提升ZKP 的證明效率約50% 。
作為領先的ZK AI 模組化運算層,Lumoz 可使用PoW 挖礦機制有效為Rollup、ZK-ML 和ZKP 驗證提供運算能力,其核心技術團隊也一直為此不懈努力。而這項技術上的這項措施不僅有效地幫助其在當今激烈競爭的Web3 ZK 運算領域脫穎而出,同時也或為即將到來的 Lumoz ZK-POW 主網「埋下伏筆」。
以下為此 Lumoz ZK-PoW 演算法優化的內容:
現有驗證流程改進
首先,Lumoz 所提出的兩步驟提交演算法與最佳化的 ZKP 生成方案在確保ZK-PoW 機制的去中心化同時也顯著提高了ZK 證明的產生及驗證效率。這在Alpha 測試網期間已經得到了很好的驗證。
而現在,經過一段時間的努力,Lumoz 團隊在原有的兩步驟提交模型基礎上進行了優化,使用更加簡潔的驗證流程以減少驗證時對於鏈上資源的消耗,也縮短了驗證流程整體的時間。在目前流程中,整體的Proof 驗證方案仍然保留了原有的提交視窗和激勵機制,但使用簡化後的一次合約呼叫來取代原有的兩步驟驗證流程。在簡化後的流程中,工作者將不再需要透過proof hash 進行身份以及任務的資訊認證,而是將包含自身資訊、任務資訊的proof id 聚合到生成的zk proof 中,在合約內一次性完成驗證。
透過這種方式,算力提供者只需要進行單次合約呼叫即可完成原有的兩步驟驗證流程,降低了50% ~ 60% 的鏈上開銷;同時,proof 的鏈上驗證步驟也從原本的窗口期後提前到了窗口期開始時,達到信任狀態的時間花費減少了約30% 。
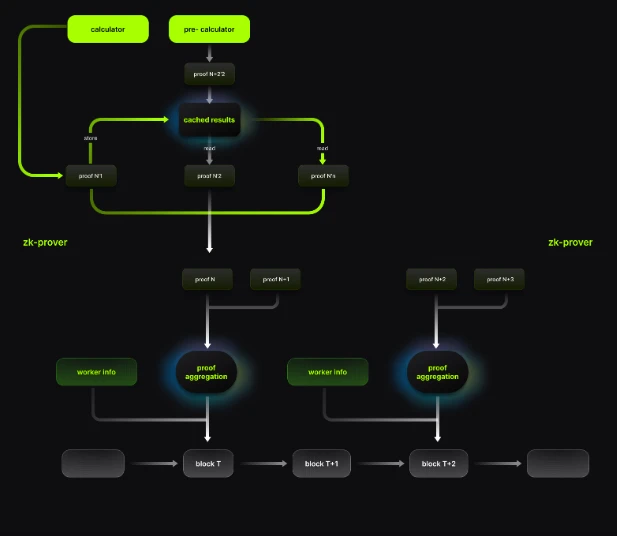
Proof 的遞迴與聚合
在Plonky 系列演算法的啟發下,Lumoz 對ZK-PoW 的證明產生方案進行了最佳化,嘗試引入遞歸形式來提高整體證明的生成效率。在新方案中,多個證明任務的生成步驟可以並行執行,最終透過遞歸的方式逐步聚合為單一證明,從而以更精簡的proof、更低的驗證開銷對整個系統完成ZK 驗證。另一方面,透過遞歸形式,優化後的方案也能將單一任務進行更細粒度的劃分,為更合理、更有效率的算力分配提供了基礎。
更合理的算力分配
在ZK-PoW 的激勵機制下,Lumoz 得以穩定維持大量ZK 算力節點。因此,設計更合理的算力分配機制將為網路整體的證明計算效率帶來很大的提升。 Lumoz 團隊在這一方向也進行了研究與改進:
計算結果復用
在先前的版本中,每個證明任務的計算流程相對獨立,僅依賴系統目前的一些狀態參數。在這個過程中,有大量計算流程是重複且冗餘的。新方案使用遞歸的形式將單一證明任務進行成了更細粒度的劃分,從而在相對獨立的證明任務之間也能夠找到可以相似的模組。對於這些模組,新方案將會對部分計算結果進行緩存,並在後續流程中直接復用,避免了這些大量的重複計算,極大地提高了算力的利用率。
另一方面,在細粒度下,節點能夠更好的對計算過程的中間值做保存,從而在異常的場景下也能夠快速從斷點恢復計算。
預計算
由於去中心化的性質,在ZK-PoW 中算力的並不總是與供給完全相同。為了避免多餘算力的浪費,算力節點並不總是需要等待證明任務產生之後才開始計算。在最佳化方案中,即使新的證明任務暫時沒有發布,節點也會根據系統當前狀態判斷新的任務在更細微上是否可以執行一些預先的計算流程,並利用空閒資源進行計算。在證明任務發布後,節點會使用極小的開銷驗證預計算結果是否有效,再推進正常的計算流程。透過利用這些空閒的算力,證明的生成速度提高了 25%
總結
Lumoz 團隊從三方面入手,多角度的對ZK-PoW 方案進行了最佳化。上層驗證流程的改進降低了驗證的鏈上開銷,同時減少了到達信任狀態的時間花費。底層證明及算力利用方式的最佳化則大大減少了證明產生所需的時間。新的優化方案在保留了原有的去中心化、市場化的 ZK 算力定價機制的同時,大幅減少了礦工開銷,並進一步提高了ZKP 的生成效率。





