




Aleo is a privacy-focused blockchain project that achieves higher privacy and scalability through zero-knowledge proof technology (ZKP). The core concept of Aleo is to enable users to authenticate and process data without revealing personal data.
This article mainly introduces the project overview and latest progress of Aleo, and provides a detailed interpretation of the puzzle algorithm update that the market is very concerned about.
Get a sneak peek at the latest algorithm
The Aleo network randomly generates a ZK circuit every hour; miners need to try different nonces as the input of the circuit within this hour, calculate the witness (that is, all the variables in the circuit, this calculation process is also called synthesize), and after finding the Merkle root of the witness, determine whether it meets the mining difficulty requirements. Due to the randomness of the circuit, this mining algorithm is not friendly to GPUs and has great difficulty in computing acceleration.
Financing Background
Aleo completed a $28 million Series A round led by a16z in 2021, and a $200 million Series B round in 2024, with investors including Kora Management, SoftBank Vision Fund 2, Tiger Global, Sea Capital, Slow Ventures, and Samsung Next. This round of financing brought Aleos valuation to $1.45 billion.
Project Overview
Privacy
The core of Aleo is zero-knowledge proof (ZKPs) technology, which allows transactions and smart contract execution to be carried out while maintaining privacy. The users transaction details, such as the sender and transaction amount, are hidden by default. This design not only protects user privacy, but also allows selective disclosure when necessary, which is very suitable for the development of DeFi applications. Its main components include:
Leo compiler language: adapted from Rust language, specifically used for developing zero-knowledge applications (ZKApps), reducing the requirements for developers to have cryptographic knowledge.
snarkVM and snarkOS: snarkVM allows off-chain computations to be performed, with only the computation results verified on-chain, thus improving efficiency. snarkOS ensures the security of data and computations and allows permissionless function execution.
zkCloud: Provides a secure and private off-chain computing environment that supports programmatic interactions between users, organizations, and DAOs.
Aleo also provides an integrated development environment (IDE) and software development kit (SDK) to support developers to quickly write and publish applications; in addition, developers can deploy applications in Aleos program registry without relying on third parties, thus reducing platform risks.
Scalability
Aleo uses an off-chain processing method, where transactions are first proved on the users device, and then only the verification results are uploaded to the blockchain. This method greatly improves the transaction processing speed and system scalability, avoiding network congestion and high fees similar to Ethereum.
Consensus Mechanism
Aleo introduces AleoBFT, a hybrid consensus mechanism that combines the instant finality of validators and the computational power of provers. AleoBFT not only improves the decentralization of the network, but also enhances performance and security.
Fast block finality: AleoBFT ensures that each block is confirmed immediately after it is generated, improving node stability and user experience.
Decentralized guarantee: By separating block production from coinbase generation, validators are responsible for generating blocks and provers perform proof calculations, preventing a small number of entities from monopolizing the network.
Incentive mechanism: Validators and provers share block rewards; provers are encouraged to become validators by staking tokens, thereby improving the decentralization and computing power of the network.
Aleo allows developers to create applications that are not limited by gas, making it particularly suitable for long-running applications such as machine learning.
Current Progress
Aleo will launch its incentivized testnet on July 1st. Here are some important updates:
ARC-100 vote passed: The vote on ARC-100 (“Compliance Best Practices for Aleo Developers and Operators” proposal, which covers compliance aspects, locking and delaying funds on the Aleo network, and other security measures) has closed and passed. The team is making final adjustments.
Validator Incentive Program: This program will be launched on July 1st and is aimed at validating the new puzzle mechanism. The program will run until July 15th, during which 1 million Aleo points will be distributed as rewards. The percentage of points generated by the node will determine its share of the reward, and each validator must earn at least 100 tokens to receive the reward. The specific details have not yet been finalized.
Initial Supply and Circulating Supply: The initial supply is 1.5 billion tokens, with an initial circulating supply of approximately 10% (not finalized yet). These tokens will primarily come from the Coinbase Mission (75 million) and will be distributed within the first six months, along with rewards for staking, running validators, and validating nodes.
Testnet Beta Reset: This is the last network reset, no new features will be added after completion, the network will be similar to mainnet. The reset is to add ARC-41 and new puzzle features.
Code Freeze: Code freeze was completed a week ago.
Verification node expansion plan: The initial number of verification nodes is 15, with the goal of increasing to 50 within the year and eventually reaching 500. It takes 10,000 tokens to become a delegator and 10 million tokens to become a validator, and these amounts will gradually decrease over time.
Algorithm Update Interpretation
Aleo recently announced the latest testnet news and updated the latest version of the puzzle algorithm. The new algorithm no longer focuses on the generation of zk proof results, removes the calculation of MSM and NTT (both are computing modules that are widely used in generating proofs in zk. Previously, testnet participants optimized the efficiency of the algorithm to increase mining revenue), and focuses on the generation of intermediate data witness before generating proofs. After referring to the official puzzle spec and code, we will give a brief introduction to the latest algorithm.
Consensus Process
At the consensus protocol level, the prover and validator in the process are responsible for generating the calculation result solution and generating blocks and aggregating and packaging the solution respectively. The process is as follows:
Prover calculates the puzzle, constructs solutions and broadcasts them to the network
Validator aggregates transactions and solutions into the next new block, ensuring that the number of solutions does not exceed the consensus limit (MAX_SOLUTIONS)
The legitimacy of the solution needs to be verified that its epoch_hash conforms to the latest_epoch_hash maintained by the validator, its calculated proof_target conforms to the latest_proof_target maintained by the validator in the network, and the number of solutions contained in the block is less than the consensus limit.
A valid solution can receive consensus rewards
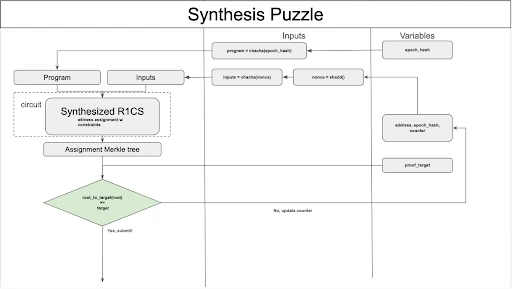
Synthesis Puzzle
The core of the latest version of the algorithm is called Synthesis Puzzle. Its core is to generate a common EpochProgram for each epoch, and to generate the corresponding R 1 CS assignment (the witness mentioned by everyone) as the leaf node of the Merkle tree by constructing an R 1 CS proof circuit for the input and EpochProgram. After calculating all the leaf nodes, the Merkle root is generated and converted into the proof_target of the solution. The detailed process and specifications for building Synthesis Puzzle are as follows:
1. Each puzzle calculation is called a nonce, which is constructed by the address receiving the mining reward, epoch_hash and a random number counter. Every time a new solution needs to be calculated, a new nonce can be obtained by updating the counter.
2. In each epoch, all provers in the network need to calculate the same EpochProgram, which is sampled from the instruction set by the random number generated by the current epoch_hash. The sampling logic is:
The instruction set is fixed. Each instruction contains one or more computational operations. Each instruction has a preset weight and operation count.
When sampling, a random number is generated according to the current epoch_hash. According to the random number, instructions are obtained from the instruction set in combination with the weight and arranged in sequence. Sampling stops after the cumulative operation count reaches 97.
Group all instructions into EpochProgram
3. Use nonce as the random number seed to generate the input of EpochProgram
4. Aggregate the R 1 CS and input corresponding to EpochProgram and perform witness (R 1 CS assignment) calculation
5. After all witnesses are calculated, they will be converted into the leaf node sequence of the corresponding merkle tree. The merkle tree is an 8-ary K-ary Merkle tree with a depth of 8.
6. Calculate the merkle root and convert it into the proof_target of the solution, determine whether it meets the latest_proof_target of the current epoch, if so, the calculation is successful, submit the reward address, epoch_hash and counter required for constructing the input as the solution and broadcast it
7. In the same epoch, you can update the input of EpochProgram by iterating the counter to perform multiple solution calculations.
Changes and impacts of mining
After this update, the puzzle has changed from generating proof to generating witness. The calculation logic of all solutions in each epoch is consistent, but the calculation logic of different epochs is quite different.
From the previous test network, we can find that many optimization methods focus on using GPU to optimize the MSM and NTT calculations in the proof generation stage to improve mining efficiency. This update completely abandons this part of the calculation; at the same time, since the process of generating witnesses is generated by executing a program that changes with the epoch, the instructions in it will have some serial execution dependencies, so it is quite challenging to achieve parallelization.





