




TL;DR
第三次ブラウザ戦争が静かに展開している。歴史を振り返ると、1990年代のNetscapeとMicrosoftのIEから、オープンソースのFirefoxとGoogleのChromeに至るまで、ブラウザ戦争は常にプラットフォームの支配と技術パラダイムシフトを凝縮した反映であった。Chromeは更新速度とエコシステムの連携によって優位な地位を獲得し、Googleは検索とブラウザの「複占」構造を通じて情報入力の閉ループを形成してきた。
しかし今日、このパターンは揺らぎ始めています。大規模言語モデル(LLM)の台頭により、検索結果ページでのタスクを「ゼロクリック」で完了できるユーザーが増え、従来のウェブページクリックは減少しています。同時に、AppleがSafariのデフォルト検索エンジンを置き換える意向があるという噂は、Googleの親会社であるAlphabetの収益基盤をさらに脅かし、市場は「検索の正統性」に対する不安感を示し始めています。
ブラウザ自体も役割の再構築に直面しています。ブラウザはウェブページを表示するツールであるだけでなく、データ入力、ユーザー行動、プライバシーIDといった複数の機能を統合したツールでもあります。AIエージェントは強力ですが、複雑なページインタラクションの実行、ローカルIDデータの呼び出し、ウェブページ要素の制御には、ブラウザの信頼境界と関数サンドボックスへの依存が依然として必要です。ブラウザは、ヒューマンインターフェースからエージェントのシステムコールプラットフォームへと変化しつつあります。
本稿では、ブラウザが依然として必要かどうかを考察します。同時に、現在のブラウザ市場を席巻する可能性のあるのは、もはや「より優れたChrome」ではなく、新たなインタラクション構造、つまり情報の表示ではなくタスクの呼び出しであると考えています。将来的には、ブラウザはAIエージェント向けに設計されるべきです。つまり、読み込みだけでなく、書き込みと実行も考慮されるべきです。Browser Useのようなプロジェクトは、ページ構造をセマンティクス化し、ビジュアルインターフェースをLLMから呼び出し可能な構造化テキストに変換することで、ページと命令のマッピングを実現し、インタラクションコストを大幅に削減しようとしています。
市場の主流プロジェクトは、すでにその実力を測り始めています。PerplexityはネイティブブラウザCometを開発し、AIを活用して従来の検索結果を置き換えました。Braveはプライバシー保護とローカル推論を組み合わせ、LLMを用いて検索機能とブロック機能を強化しました。DonutのようなCryptoネイティブプロジェクトは、AIがオンチェーン資産と対話するための新たなエントリポイントをターゲットにしています。これらのプロジェクトに共通する特徴は、ブラウザの出力層を美しくするのではなく、入力層を再構築しようとしていることです。
起業家にとって、入力、構造、エージェントの三角関係にこそチャンスが潜んでいます。将来、エージェントが世界を呼び出すためのインターフェースとなるブラウザは、構造化され、呼び出し可能で、信頼できる「機能ブロック」を提供できる者が、新世代のプラットフォームの一員になれることを意味します。SEOからAEO(エージェントエンジン最適化)、ページトラフィックからタスクチェーン呼び出しまで、製品形態とデザイン思考が再構築されています。第三次ブラウザ戦争は「表示」ではなく「入力」を舞台に展開されました。勝敗はもはやユーザーの目に留まるものではなく、エージェントの信頼を獲得し、呼び出しのエントリーポイントを獲得できる者によって決まるのです。
ブラウザ開発の簡単な歴史
1990年代初頭、インターネットがまだ日常生活の一部となっていなかった頃、Netscape Navigatorが誕生しました。まるで帆船が新大陸を切り開き、何百万人ものユーザーにデジタル世界への扉を開いたかのようでした。このブラウザは最初のブラウザではありませんでしたが、真に大衆に受け入れられ、インターネット体験を形作った最初の製品でした。当時、人々は初めてグラフィカルインターフェースを通してこれほど簡単にウェブを閲覧できるようになり、まるで全世界が突然手の届くところにあるかのようでした。
しかし、栄光は長くは続かないものです。Microsoftはすぐにブラウザの重要性に気づき、Internet ExplorerをWindows OSに強制的にバンドルし、デフォルトのブラウザにすることを決定しました。この戦略は「プラットフォームキラー」とも呼ばれ、Netscapeの市場支配を直接的に揺るがしました。多くのユーザーは積極的にIEを選んだわけではなく、システムがデフォルトで受け入れていたため、受け入れたのです。Windowsの配布機能の恩恵を受け、IEは瞬く間に業界のリーダーとなり、Netscapeは衰退の一途を辿りました。

Firefox ロゴの進化
困難な状況の中、Netscapeのエンジニアたちは急進的かつ理想的な道を選びました。ブラウザのソースコードを公開し、オープンソースコミュニティに呼びかけたのです。この決断は、テクノロジー界における「マケドニアの譲歩」と捉えられ、旧時代の終焉と新たな勢力の台頭を告げるものとなりました。このコードは後にMozillaブラウザプロジェクトの基盤となり、当初はPhoenix(不死鳥の涅槃を意味する)と名付けられましたが、商標問題により何度か改名され、最終的にFirefoxと命名されました。
FirefoxはNetscapeの単なるコピーではありません。ユーザーエクスペリエンス、プラグインエコシステム、セキュリティなど、多くの点で飛躍的な進歩を遂げてきました。その誕生はオープンソース精神の勝利を象徴し、業界全体に新たな活力を与えています。オスマン帝国がビザンツ帝国の残光を受け継いだように、FirefoxをNetscapeの「精神的後継者」と表現する人もいます。この比喩は誇張されているかもしれませんが、非常に意義深いものです。
しかし、Firefoxが正式にリリースされる数年前、MicrosoftはすでにIEの6つのバージョンをリリースしていました。時間的な優位性とシステムバンドル戦略に頼っていたFirefoxは、最初から追い上げの立場にあり、この競争は公平なスタート地点での競争とは言えませんでした。
同じ頃、もう一つの先駆者がひっそりと登場していました。1994年、ノルウェーからOperaブラウザが登場しました。当初は実験的なプロジェクトに過ぎませんでした。しかし、2003年のバージョン7.0以降、独自のPrestoエンジンを導入し、CSS、アダプティブレイアウト、音声制御、Unicodeエンコーディングといった最先端技術を初めてサポートしました。ユーザー数は限られていましたが、常にテクノロジーの面で業界の最先端を走り、「ギークのお気に入り」となりました。
同年、AppleはSafariブラウザをリリースしました。これは大きな転換点となりました。当時、Microsoftは倒産寸前だったAppleに1億5000万ドルを投資し、競争の体裁を保ち、独占禁止法の調査を回避しようとしていました。Safariのデフォルトの検索エンジンは誕生以来Googleですが、Microsoftとのこの歴史的な絡み合いは、インターネットの巨人同士の複雑かつ繊細な関係を象徴しています。協力と競争は常に隣り合わせなのです。
2007年、Windows Vistaと同時にIE 7がリリースされましたが、市場の反応は芳しくありませんでした。一方、Firefoxはより迅速な更新ペース、より使いやすい拡張機能の仕組み、そして開発者にとって自然な魅力を武器に、着実に市場シェアを伸ばし、20%程度まで達しました。IEの優位性は徐々に弱まり、風向きも変わりつつあります。
Googleは異なるアプローチをとっています。2001年から独自のブラウザ開発を計画していましたが、CEOのエリック・シュミット氏を説得して承認を得るまでに6年を要しました。Chromeは2008年にリリースされ、オープンソースプロジェクトのChromiumとSafariで使用されているWebKitエンジンをベースにしています。「肥大化した」ブラウザというあだ名をつけられましたが、Googleの広告とブランディングにおける深い専門知識のおかげで、急速に注目を集めるようになりました。
Chromeの最大の武器は、その機能ではなく、頻繁なバージョンアップデート(6週間ごと)と、すべてのプラットフォームで統一されたエクスペリエンスです。2011年11月、Chromeは初めてFirefoxを上回り、市場シェア27%に達しました。そして6ヶ月後にはIEを上回り、挑戦者から支配的な存在へと変貌を遂げました。
同時に、中国のモバイルインターネットも独自のエコシステムを形成しつつあります。アリババのUCブラウザは2010年代初頭、特にインド、インドネシア、中国などの新興市場で急速に普及しました。軽量設計、データ圧縮、通信量節約機能により、ローエンドデバイスユーザーから高い支持を得ました。2015年には、モバイルブラウザの世界市場シェアは17%を超え、インドでは一時46%に達しました。しかし、この勝利は長くは続きませんでした。インド政府が中国製アプリのセキュリティ審査を強化したため、UCブラウザは主要市場から撤退を余儀なくされ、徐々にかつての栄光を失っていきました。
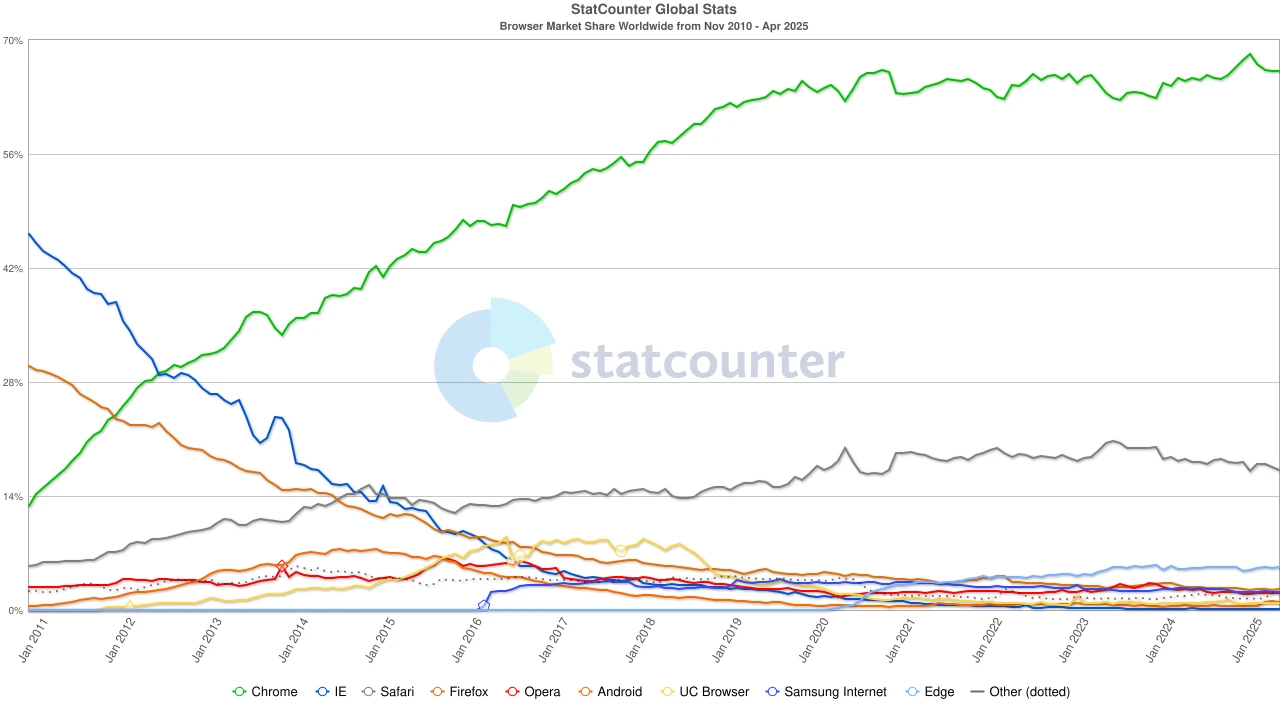
ブラウザの市場シェア、出典:statcounter
2020年代に入り、Chromeは世界市場シェアの約65%を占め、圧倒的な優位性を確立しました。注目すべきは、Google検索エンジンとChromeブラウザはAlphabet傘下ですが、市場の観点から見るとそれぞれ独立した覇権システムであるということです。前者は世界の検索ポータルの約90%を支配し、後者はほとんどのユーザーがインターネットにアクセスする「最初の窓口」を支配しています。
この二重独占構造を維持するために、Googleは巨額の投資を行ってきました。2022年には、GoogleをSafariのデフォルト検索として維持するためだけに、AlphabetはAppleに約200億ドルを支払いました。一部のアナリストは、この支出はSafariトラフィックからのGoogleの検索広告収入の36%に相当すると指摘しています。つまり、Googleは自らの堀を守るために「保護料」を支払っているのです。
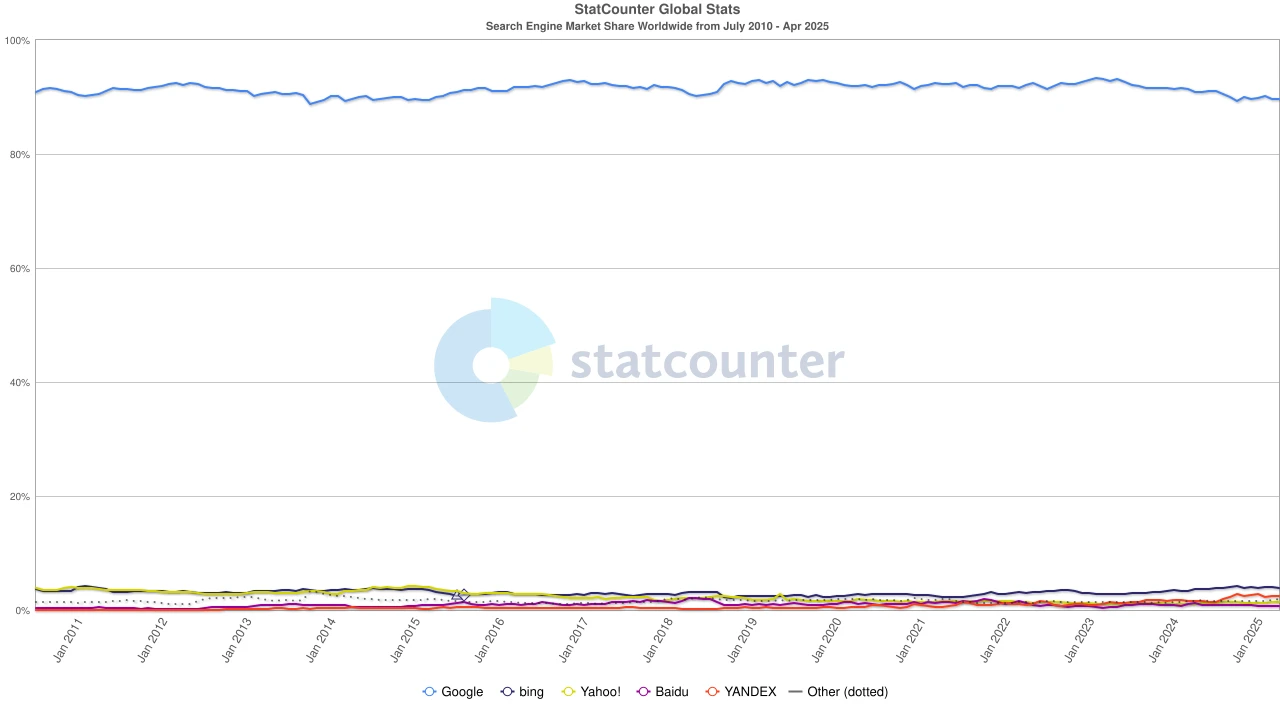
検索エンジン市場シェア、出典:statcounter
しかし、風向きは再び変わりました。大規模言語モデル(LLM)の台頭により、従来の検索は影響を受け始めています。2024年には、Googleの検索市場シェアは93%から89%に低下しました。依然として優位に立っているものの、亀裂が見え始めています。さらに衝撃的なのは、Appleが独自のAI検索エンジンを立ち上げるかもしれないという噂です。Safariのデフォルト検索がApple陣営に移行すれば、生態系の地形が書き換えられるだけでなく、Alphabetの収益の柱も揺るがす可能性があります。市場はすぐに反応し、Alphabetの株価は170ドルから140ドルに下落しました。これは、投資家のパニックだけでなく、検索時代の今後の方向性に対する深い不安を反映しています。
NavigatorからChromeへ、オープンソースの理念から広告の商業化へ、軽量ブラウザからAI検索アシスタントへ。ブラウザ戦争は常に技術、プラットフォーム、コンテンツ、そしてコントロールをめぐる戦いでした。戦場は常に変化し続けていますが、本質は変わりません。入り口を制する者が未来を決めるのです。
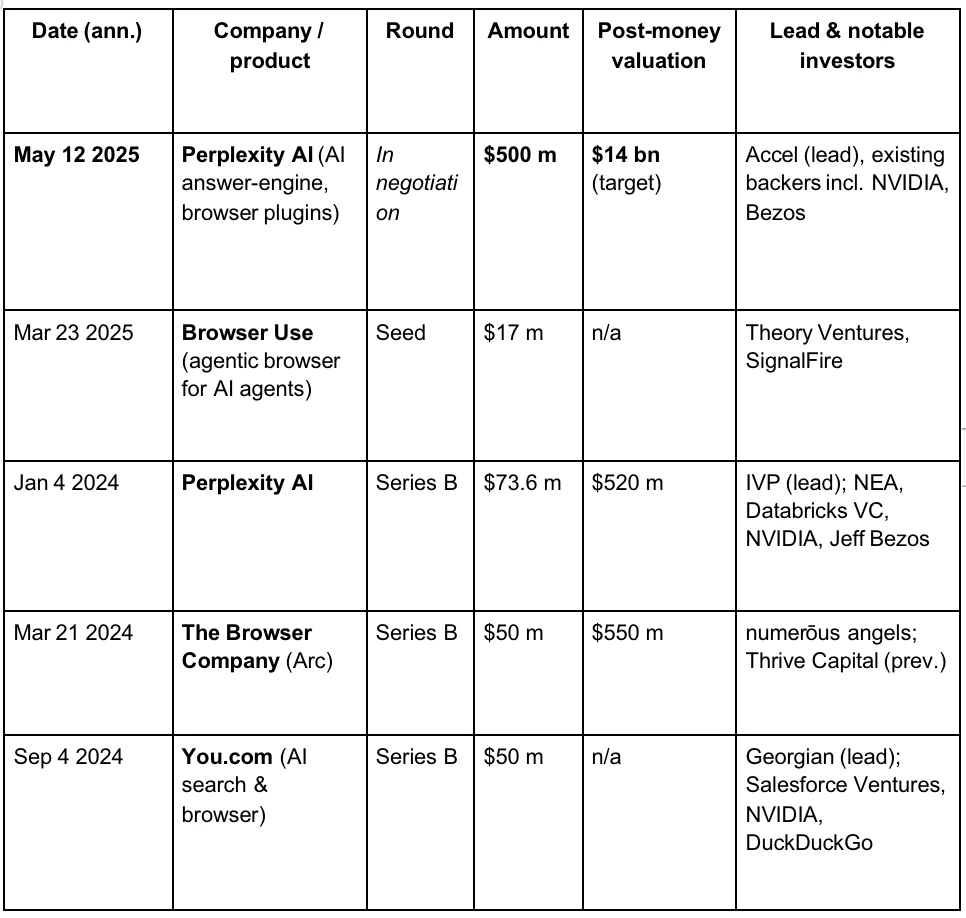
VCの視点から見ると、法学修士課程とAI時代における人々の検索エンジンへの新たな需要に支えられ、第三次ブラウザ戦争が徐々に展開しつつあります。以下は、いくつかの著名なAIブラウザプロジェクトの資金調達状況です。
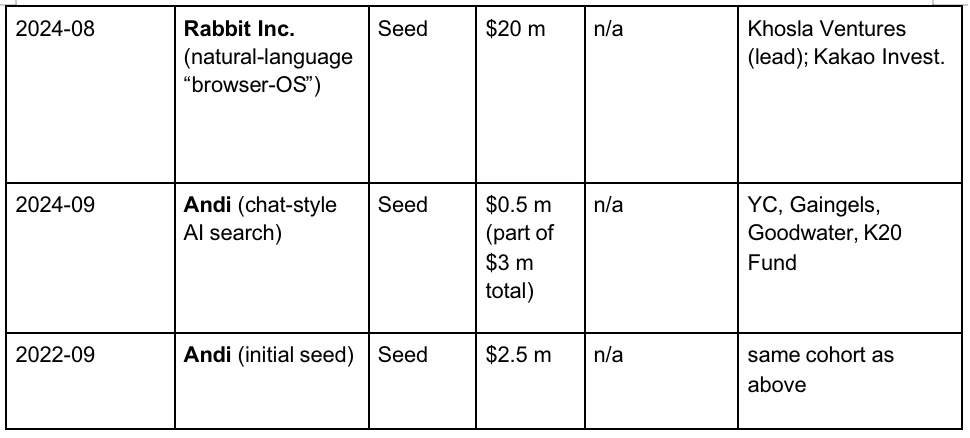
現代のブラウザの古いアーキテクチャ
ブラウザのアーキテクチャに関しては、従来の古典的なアーキテクチャは次の図に示されています。
全体的なアーキテクチャ、出典: Damien Benveniste
1. クライアントフロントエンドエントリ
クエリはHTTPS経由で最寄りのGoogle Front Endに送信され、TLS復号化、QoSサンプリング、地理的ルーティングが完了します。異常なトラフィック(DDoS、自動クロールなど)が検出された場合は、このレイヤーで制限またはチャレンジできます。
2. クエリの理解
フロントエンドは、ユーザーが入力した単語の意味を理解する必要があります。これには、ニューラル スペル修正 (「recpie」を「recipe」に修正)、同義語拡張 (「how to fix bike」を「repair bicycle」に拡張)、および意図分析 (クエリが情報、ナビゲーション、またはトランザクションのいずれを目的としているかを判断し、垂直リクエストを割り当てます) という 3 つの手順が含まれます。
3. 候補者のリコール
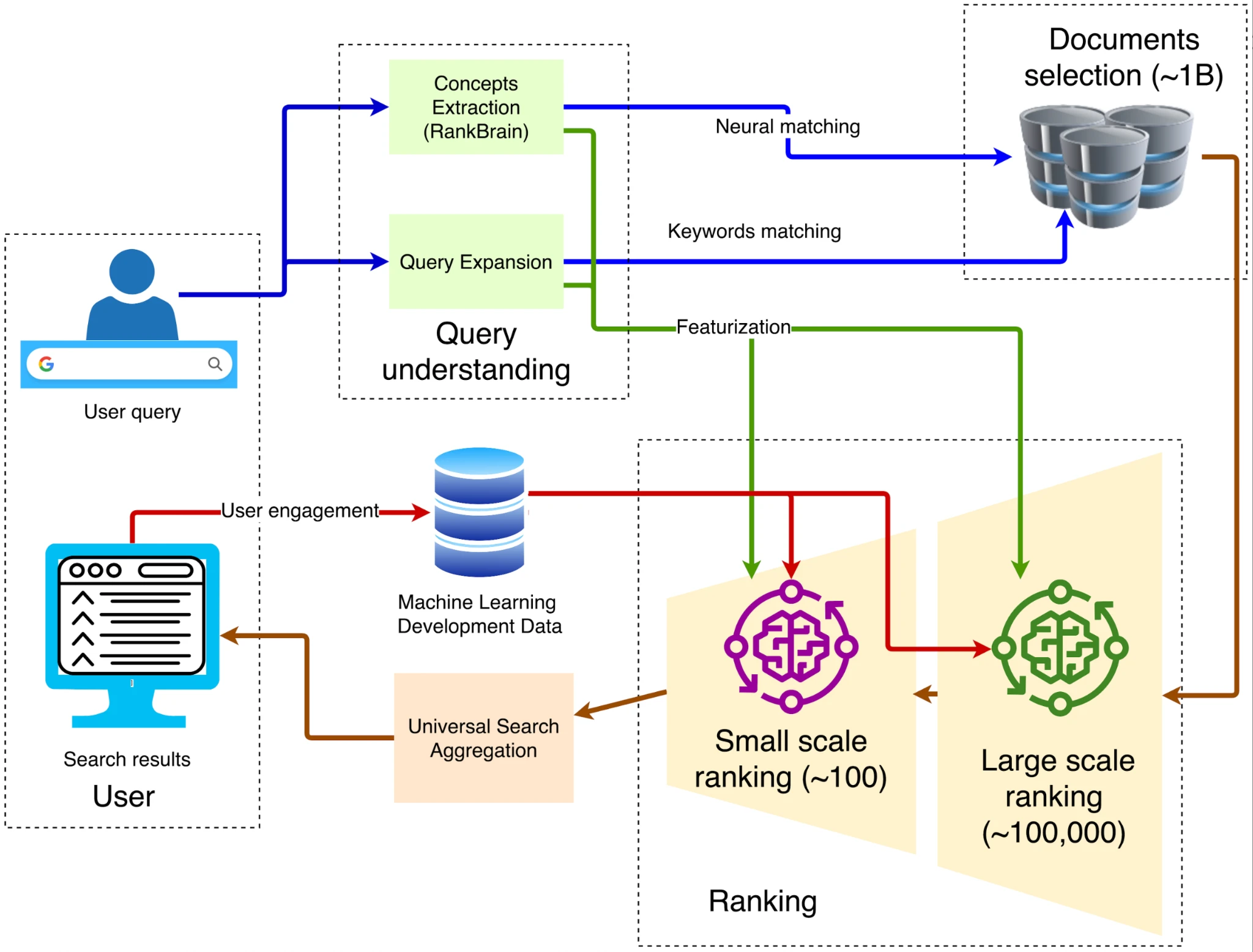
逆インデックス、出典:スポットインテリジェンス
Googleが使用するクエリ技術は、転置インデックスと呼ばれます。順方向インデックスでは、IDを指定してファイルにインデックスを付けることができます。しかし、ユーザーが数千億ものファイルの中から目的のコンテンツがいくつあるかを把握することは不可能です。そのため、Googleは極めて伝統的な転置インデックスを用いて、コンテンツを通じてどのファイルに該当するキーワードが含まれているかを照会します。次に、Googleはベクトルインデックスを用いてセマンティック検索、つまりクエリと意味が類似するコンテンツを検索します。テキスト、画像、その他のコンテンツを高次元ベクトル(埋め込み)に変換し、これらのベクトル間の類似性に基づいて検索を行います。例えば、ユーザーが「ピザ生地の作り方」を検索した場合でも、検索エンジンは意味的に類似しているため、「ピザ生地の作り方ガイド」に関連する結果を返すことができます。転置インデックスとベクトルインデックスを経ることで、約10万件のウェブページが最初に除外されます。
4. 多段階ソート
システムは通常、BM2 5、TF-IDF、ページ品質スコアなどの数千の軽量特徴量を用いて、数十万ページから約1,000ページの候補ページをフィルタリングし、予備的な候補セットを形成します。このようなシステムは総称してレコメンデーションエンジンと呼ばれ、ユーザーの行動、ページ属性、クエリの意図、コンテキストシグナルなど、複数のエンティティによって生成される膨大な特徴量に依存しています。例えば、Googleはユーザーの履歴、他のユーザーからの行動フィードバック、ページのセマンティクス、クエリの意味などの情報を統合するとともに、時間(時間帯、曜日)やリアルタイムニュースなどの外部イベントなどのコンテキスト要因も考慮します。
5. 一次分類のためのディープラーニング
Googleは、初期の検索段階でRankBrainやNeural Matchingなどの技術を用いてクエリの意味を理解し、大量のドキュメントから関連性の高い予備的な結果をフィルタリングします。RankBrainは、Googleが2015年に導入した機械学習システムで、ユーザークエリ、特に初めて表示されるクエリの意味をより深く理解できるように設計されています。クエリとドキュメントをベクトル表現に変換し、それらの類似度を計算することで、最も関連性の高い結果を見つけます。例えば、「ピザ生地の作り方」というクエリの場合、ドキュメント内に完全に一致するキーワードがなくても、RankBrainは「ピザの基本」や「生地作り」に関連するコンテンツを識別できます。
ニューラルマッチングは、Googleが2018年にリリースした、クエリとドキュメント間の意味的関係をより深く理解するための技術です。ニューラルネットワークモデルを用いて単語間の曖昧な関係性を捉えることで、Googleがクエリとウェブページのコンテンツをより正確に一致させるのに役立ちます。例えば、「ノートパソコンのファンがうるさいのはなぜですか?」というクエリの場合、ニューラルマッチングは、これらの単語がクエリに直接現れていなくても、ユーザーが過熱、埃の蓄積、CPU使用率の上昇といったトラブルシューティング情報を探している可能性があると理解できます。
6. ディープリランキング:BERTモデルの応用
Googleは、関連性の高い文書を最初に選別した後、BERT(Bidirectional Encoder Representations from Transformers)モデルを用いてこれらの文書をより細かく分類し、最も関連性の高い結果が上位に表示されるようにします。BERTは、Transformerをベースとした事前学習済みの言語モデルで、文中の単語間の文脈的関係を理解できます。検索では、BERTは最初に取得された文書の再ランキングに使用されます。BERTは、クエリと文書を共同でエンコードし、それらの関連性スコアを計算することで、文書の再ランキングを行います。例えば、「縁石のないランプに駐車する」というクエリに対して、BERTは「縁石がない」の意味を理解し、縁石がある状況と誤解するのではなく、ハンドルを縁石の方に向けるよう運転者に推奨するページを返します。SEOエンジニアは、Googleランキングと機械学習の推奨アルゴリズムを正確に学習し、ウェブページのコンテンツを的確に最適化して、上位表示を獲得する必要があります。
上記はGoogle検索エンジンの典型的なワークフローです。しかし、AIとビッグデータの爆発的な増加が続く現代において、ユーザーはブラウザインタラクションに新たな要求を抱いています。
AIがブラウザを変える理由
まず、ブラウザ形式がなぜ今も存在しているのかを明確にする必要があります。人工知能エージェントとブラウザ以外の選択肢、つまり第三の形式は存在するのでしょうか?
私たちは、存在はかけがえのないものだと信じています。なぜ人工知能はブラウザを活用できるにもかかわらず、完全に置き換えることができないのでしょうか?それは、ブラウザが普遍的なプラットフォームであり、データを読み取るための入り口であるだけでなく、データを入力するための普遍的な入り口でもあるからです。この世界では、情報を入力するだけでなく、データを生成し、ウェブサイトとやり取りする必要があります。そのため、パーソナライズされたユーザー情報を統合するブラウザは、今後も広く存在し続けるでしょう。
ブラウザは普遍的なエントリポイントであり、データの読み取りだけでなく、ユーザーがデータとやり取りする必要があることも多々あります。ブラウザ自体は、ユーザーの指紋を保存するのに最適な場所です。より複雑なユーザー行動や自動化された行動は、ブラウザを通じて実行する必要があります。ブラウザは、すべてのユーザー行動の指紋、パスワード、その他のプライバシー情報を保存し、自動化プロセス中にトラストレスな呼び出しを実装できます。データとのやり取りは、次のように進化する可能性があります。
ユーザー → AI エージェントの呼び出し → ブラウザ。
言い換えれば、置き換えられる可能性があるのは、世界の進化の潮流、つまりよりインテリジェントで、よりパーソナライズされ、より自動化された部分だけです。確かに、この部分はAIエージェントで処理できますが、AIエージェント自体は、データセキュリティと利便性の面で多くの課題を抱えているため、ユーザーパーソナライズされたコンテンツを配信するのには決して適していません。具体的には、
ブラウザにはパーソナライズされたコンテンツが保存されます。
1. 大規模なモデルのほとんどはクラウドでホストされており、セッション コンテキストはサーバー上に保存されるため、ローカル パスワード、ウォレット、Cookie などの機密データを直接呼び出すことは困難です。
2. すべての閲覧データと支払いデータをサードパーティ モデルに送信するには、ユーザーからの再承認が必要です。EU DMA と米国の州プライバシー法はどちらも、データのアウトバウンド転送を最小限に抑えることを義務付けています。
3. 2 要素認証コードの自動入力、カメラの呼び出し、WebGPU 推論用の GPU の使用はすべてブラウザ サンドボックス内で実行する必要があります。
4. データ コンテキストは、タブ、Cookie、IndexedDB、Service Worker Cache、Passkey 資格情報、拡張データなど、すべてブラウザーに保存されるものであり、ブラウザーに大きく依存します。
交流形態の大きな変化
冒頭の話題に戻りますが、ブラウザを使用する際の行動は、データの読み取り、データの入力、そしてデータとのインタラクションという3つの形態に大別できます。人工知能ビッグモデル(LLM)は、データの読み取りの効率と方法を大きく変えました。かつて、キーワードに基づいてウェブページを検索するというユーザーの行動は、非常に古く非効率的なものでした。
要約された回答を取得するか、Web ページをクリックするかなど、ユーザーの検索行動の進化を分析する研究は数多く行われています。
ユーザーの行動パターンに関して言えば、2024年の調査によると、米国におけるGoogle検索1,000件のうち、実際にウェブページをクリックしたのはわずか374件でした。つまり、約63%が「ゼロクリック」行動だったことになります。ユーザーは、天気、為替レート、ナレッジカードなどの情報を検索結果ページから直接入手することに慣れています。
ユーザー心理の観点から見ると、2023年の調査では、回答者の44%が通常の自然な検索結果の方が強調スニペットよりも信頼できると考えていることが示されました。学術研究でも、物議を醸すトピックや統一された真実がない場合、ユーザーは複数のソースリンクを含む結果ページを好むことが分かっています。
つまり、一部のユーザーはAI要約をあまり信頼していませんが、ユーザー行動のかなりの割合が「ゼロクリック」に移行しています。そのため、AIブラウザは、特にデータ読み取り部分において、適切なインタラクティブ形式を模索する必要があります。現在の大規模モデルの「幻覚問題」は依然として解消されておらず、多くのユーザーは自動生成されたコンテンツ要約を完全に信頼することが難しいと感じています。この点、大規模モデルをブラウザに組み込む場合、ブラウザに破壊的な変更を加える必要はなく、モデルの精度と制御性を徐々に改善していくだけで十分です。この改善も継続的に推進されています。
ブラウザに真に大きな変化をもたらす可能性があるのは、データインタラクション層です。かつては、ユーザーはキーワードを入力することでインタラクションを完了していましたが、これはブラウザが理解できる範囲の限界でした。現在、ユーザーは複雑なタスクを説明する際に、自然言語で構成された段落全体を使う傾向が高まっています。例えば、
● 「特定の期間のニューヨークからロサンゼルスへの直行便を検索」
●「ニューヨークから上海、そしてロサンゼルスへのフライトを探しています」
これらの行動は、人間であっても複数のウェブサイトにアクセスし、データを収集・比較するのに多くの時間を要します。しかし、これらのエージェント的なタスクは徐々にAIエージェントに取って代わられつつあります。
これは、自動化とインテリジェンスという歴史的進化の方向性とも合致しています。人々は手を自由にすることを切望しており、AIエージェントはブラウザに深く組み込まれるでしょう。将来のブラウザは、特に以下の点を考慮して、完全な自動化を実現するように設計する必要があります。
● 人間の読解体験とAIエージェントの解析可能性のバランスをとる方法
● 同じページでユーザーとエージェント モデルの両方を提供する方法。
設計がこれら 2 つの要件を満たしている場合にのみ、ブラウザは AI エージェントがタスクを実行するための真に安定したキャリアになることができます。
次に、Browser Use、Arc(The Browser Company)、Perplexity、Brave、Donutといった、期待の高い5つのプロジェクトに焦点を当てます。これらのプロジェクトは、AIブラウザの将来的な進化と、Web3および暗号シナリオへのネイティブ統合の可能性を象徴しています。
ブラウザの使用
これが、PerplexityとBrowser Useへの巨額の資金調達の背後にある核心的なロジックです。特に、Browser Useは、2025年前半に出現するイノベーション機会の中で、2番目に確実性と成長性が高い分野です。

ブラウザの使用状況、出典: ブラウザの使用状況
ブラウザは真のセマンティック レイヤーを構築しており、その中核となるのは次世代ブラウザ向けのセマンティック認識アーキテクチャの構築です。
Browser Useは、従来の「DOM = 人間のためのノードツリー」を「セマンティックDOM = LLMのための命令ツリー」へとデコードすることで、エージェントが「フィルムポイントの座標を見る」ことなく、正確にクリック、入力、アップロードできるようにします。この方法は、視覚的なOCRや座標系Seleniumを「構造化テキスト → 関数呼び出し」に置き換えるため、実行速度が向上し、トークンが節約され、エラーが減少します。TechCrunchはこれを「AIがWebページを真に理解できるようにするグルーレイヤー」と呼び、3月に完了した1,700万ドルのシードラウンドは、この基盤となるイノベーションへの賭けです。
HTML レンダリング後、標準の DOM ツリーが形成されます。その後、ブラウザはアクセシビリティ ツリーを導出して、スクリーン リーダーに豊富な「役割」と「状態」のラベルを提供します。
1. 各インタラクティブ要素 (<button>、<input> など) を、役割、可視性、座標、実行可能なアクションなどのメタデータを含む JSON フラグメントに抽象化します。
2. LLM がシステム プロンプトで一度に読み取れるように、ページ全体をフラット化された「セマンティック ノード リスト」に変換します。
3. LLMが出力した高レベルの命令(click(node_id=btn-Checkout)など)を受け取り、実際のブラウザで再生します。公式ブログでは、このプロセスを「ウェブサイトのインターフェースをLLMが解析できる構造化テキストに変換する」と呼んでいます。
同時に、この一連の標準がW3Cに導入されれば、ブラウザ入力の問題はほぼ解決される可能性があります。The Browser Companyの公開書簡と事例を用いて、The Browser Companyの考えがなぜ間違っているのかをさらに詳しく説明します。
アーク
Arcの親会社であるThe Browser Companyは、公開書簡の中で、ARCブラウザが定期メンテナンスフェーズに入り、チームはAIに完全特化したブラウザであるDIAに注力すると述べました。また、DIAの具体的な実装パスはまだ決定されていないことも認めています。同時に、チームは書簡の中で将来のブラウザ市場についていくつかの予測を示しました。これらの予測に基づき、既存のブラウザ環境を真に覆すには、インタラクティブな側面におけるアウトプットを変えることが鍵となると考えています。
ここでは、ブラウザ市場の将来について ARC チームから得た 3 つの予測を紹介します。
ウェブページはもはや主要なインターフェースではなくなるでしょう。従来のブラウザはウェブページを読み込むために作られました。しかし、ウェブページ(アプリ、記事、ファイルなど)は、AIチャットインターフェースによってますますツールコールへと変化していくでしょう。多くの点で、チャットインターフェースは既にブラウザのように機能しています。検索、読み取り、生成、応答といった機能です。API、LLM、データベースとのやり取りも行います。そして、人々は毎日何時間もチャットインターフェースを使っています。もし懐疑的であれば、高校や大学のいとこに聞いてみてください。古いコンピューティングパラダイムの退屈さを抽象化する自然言語インターフェースは、今後も存在し続けるでしょう。
しかし、Webはどこにも行きません。少なくとも近い将来は。FigmaやThe New York Timesの重要性は低下していません。上司がチームのSaaSツールを捨てたりもしません。むしろその逆です。私たちはこれからも、ドキュメントを編集したり、ビデオを視聴したり、お気に入りの出版社の週末記事を読んだりする必要があるでしょう。もっと直接的に言えば、Webページは置き換えられることはありません。不可欠なものであり続けるでしょう。タブは使い捨てではなく、私たちの中核となるコンテキストです。だからこそ私たちは、デスクトップにおけるAIへの最も強力なインターフェースは、WebブラウザでもAIチャットインターフェースでもないと考えています。その両方になるでしょう。まるでピーナッツバターとジャムのように。iPhoneが古いカテゴリーを根本的に新しいものに組み合わせたように、AIブラウザもそうなるでしょう。たとえそれが私たちのブラウザでなくても。
新しいインターフェースは、馴染みのあるインターフェースから始まります。この新しい世界では、二つの相反する力が同時に働いています。私たち皆がコンピューターを使う方法は、(AIのおかげで)ほとんどの人が認識しているよりもはるかに速いペースで変化しています。しかし同時に、AI関係者が考えているほど、私たちは古いやり方を完全に捨て去るには程遠いのです。Cursorはコーディング分野でこの仮説を証明しました。昨年の画期的なAIアプリは、AIネイティブに設計された(古い)IDEだったのです。OpenAIは、Codexがバックグラウンドで静かに動作しているにもかかわらず、Windsurf(別のAI IDE)を買収したことで、この理論を裏付けました。私たちは、AIブラウザが次に来ると信じています。
まず、ウェブページはもはや主要なインタラクティブインターフェースではないと考えています。確かにこれは難しい判断であり、創設者の考察の結果に私たちが疑問を抱く主な理由でもあります。私たちの意見では、この見解はブラウザの役割を著しく過小評価しており、AIブラウザの方向性を探る際に無視されている重要な問題でもあります。
ビッグモデルは、「飛行機を予約して」といったコマンドの理解など、意図を捉えることに優れています。しかし、情報密度という点では依然として不十分です。ユーザーがダッシュボード、ブルームバーグターミナル風のメモ帳、あるいはFigmaのようなビジュアルキャンバスを必要とする場合、ピクセル単位の精度で配置された専用のWebページに勝るものはありません。各製品に合わせた人間工学に基づいたデザイン(チャート、ドラッグアンドドロップ機能、ホットキーなど)は、単なる装飾的な要素ではなく、むしろ圧縮された認知アフォーダンスです。これらの機能は、単純な会話によるインタラクションでは実現できません。Gate.comを例に挙げると、ユーザーが投資運用業務を行いたい場合、AIによる対話だけに頼るのは到底不十分です。なぜなら、ユーザーは情報の入力、正確性、そして構造化されたプレゼンテーションに大きく依存しているからです。
RCチームのパス想定には本質的な逸脱があります。それは、「インタラクション」が入力と出力という二つの次元から成り立つことを明確に区別できていないことです。入力側においては、その見解はいくつかのシナリオにおいては妥当であり、AIは確かにコマンドベースのインタラクションの効率を向上させることができます。しかし、出力側においては、その判断は明らかに不均衡であり、情報提示とパーソナライズされた体験におけるブラウザの中核的な役割を無視しています。例えば、Redditは独自のレイアウトと情報アーキテクチャを備えていますが、AAVEは全く異なるインターフェースと構造を備えています。高度なプライバシーデータに対応し、多様な製品インターフェースを提供できるプラットフォームであるブラウザは、入力層における代替性が限られており、出力側においては、その複雑さと非標準化により、覆すことが困難になっています。一方、現在市場に出回っているAIブラウザは、「出力要約」レベル、つまりウェブページの要約、情報の精緻化、結論の生成に重点を置いています。しかし、これらの機能は、Googleなどの主流のブラウザや検索システムに対する根本的な挑戦となるには不十分であり、検索要約の市場シェアが二分されているに過ぎません。
したがって、最大66%の市場シェアを誇るChromeを真に揺るがすことができるのは、「次世代Chrome」ではないでしょう。この破壊的イノベーションを実現するには、ブラウザのレンダリングモードを根本的に再構築し、インテリジェント時代のAIエージェントが支配するインタラクティブなニーズ、特に入力側のアーキテクチャ設計に適応させる必要があります。そのため、私たちはBrowser Useが採用している技術的アプローチを支持しています。Browser Useは、ブラウザの基盤となるメカニズムの構造的変化に重点を置いています。あらゆるシステムが「アトマイズ」または「モジュール化」されると、その結果生じるプログラミング性と組み合わせ性は、極めて破壊的な破壊的可能性をもたらします。そして、まさにこれがBrowser Useが現在進めている方向性です。
まとめると、AIエージェントの動作は依然としてブラウザの存在に大きく依存しています。ブラウザは複雑なパーソナライズデータの主な保存場所であるだけでなく、多様なアプリケーションのためのユニバーサルレンダリングインターフェースでもあるため、今後もインタラクションの中心的な入り口としての役割を果たし続けるでしょう。AIエージェントはブラウザに深く埋め込まれ、一定のタスクを完了するため、ユーザーデータの呼び出しを通じて特定のアプリケーションとインタラクトします。つまり、主に入力側で動作します。そのため、ブラウザの既存のレンダリングモードを革新し、AIエージェントとの互換性と適応性を最大限に高め、アプリケーションをより効果的にキャプチャする必要があります。
困惑
Perplexityは、レコメンデーションシステムで知られるAI検索エンジンです。最新の評価額は140億ドルに達し、2024年6月の30億ドルの約5倍に達しています。月間4億件以上の検索クエリを処理しており、2024年9月には約2億5000万件のクエリを処理しました。ユーザークエリ数は前年比で8倍に増加し、月間アクティブユーザー数は3000万人を超えました。
主な特徴は、ページをリアルタイムで要約できることで、瞬時に情報を取得する上で優位性があります。今年初めには、独自のネイティブブラウザ「Comet」の開発に着手しました。Perplexityは、今後登場するCometを、ウェブページを「表示する」だけでなく、「考える」ブラウザだと説明しています。関係者によると、Perplexityの回答エンジンをブラウザに深く組み込む予定で、これはスティーブ・ジョブズ流の「ホールマシン」構想、つまりAIタスクをサイドバープラグインではなくブラウザの最下層深くに埋め込むというものです。従来の「10個の青いリンク」を引用付きの簡潔な回答に置き換え、Chromeと直接競合することになります。

Google I/O 2025
しかし、依然として2つの根本的な問題を解決する必要があります。それは、高い検索コストと、限界ユーザーからの低い利益率です。Perplexityは既にAI検索の分野で主導的な地位を占めていますが、Googleも2025年のI/Oカンファレンスで、コア製品の大規模なインテリジェントな再構築を発表しました。ブラウザの再構築に対応して、GoogleはOverview、Deep Research、そして将来のAgentic機能を統合した「AI Model」と呼ばれる新しいブラウザタブエクスペリエンスを発表しました。このプロジェクト全体は「Project Mariner」と呼ばれています。
GoogleはAIの再構築に積極的に取り組んでいるため、Overview、DeepResearch、Agenticsといった表面的な機能を模倣するだけでは、真の脅威となることは難しい。混沌とした状況に新たな秩序をもたらす真の可能性を秘めているのは、ブラウザアーキテクチャを根本から再構築し、大規模言語モデル(LLM)をブラウザカーネルに深く埋め込み、インタラクションのあり方を根本的に変革することだ。
勇敢な
Braveは、暗号資産業界で最も古く、最も成功したブラウザです。Chromiumアーキテクチャをベースとしているため、Googleストアのプラグインと互換性があります。ユーザー獲得のために、プライバシーとブラウジングによるトークン獲得モデルを採用しています。Braveの開発過程は、その成長ポテンシャルをある程度示してきました。しかし、製品の観点から見ると、プライバシーは重要ですが、その需要は依然として特定のユーザーグループに集中しており、プライバシー意識は一般の人々にとって主流の意思決定要因にはなっていません。したがって、この機能に頼ることで既存の大手ブラウザを転覆させようとする可能性は低いでしょう。
現在、Braveの月間アクティブユーザー数は8,270万人、日次アクティブユーザー数は3,560万人で、市場シェアは約1%~1.5%です。ユーザー規模は拡大を続けており、2019年7月の600万人から2021年1月には2,500万人、2023年1月には5,700万人、2025年2月には8,200万人を超え、年平均成長率は2桁となっています。月間平均検索クエリ数は約13.4億回で、Googleの約0.3%に相当します。
以下はBraveの反復的なロードマップです。
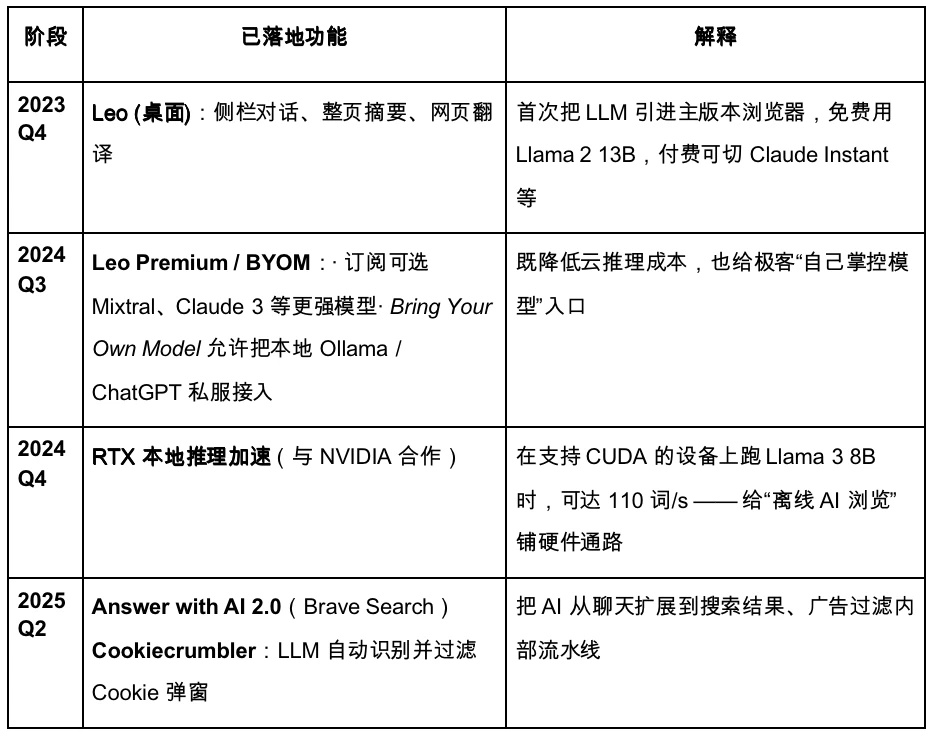
Braveはプライバシー重視のAIブラウザへのアップグレードを計画している。しかし、ユーザーデータへのアクセスが制限されているため、大規模モデルのカスタマイズ性は低く、迅速かつ正確な製品イテレーションには不向きだ。来たるAgentic Browser時代において、Braveはプライバシーを重視する一部のユーザー層で安定したシェアを維持する可能性はあるものの、主要プレーヤーとなることは難しいだろう。同社のAIアシスタントLeoはプラグインのようなもので、既存製品の機能強化やコンテンツの要約といった一定の機能を備えているものの、AIエージェントへの完全移行に向けた明確な戦略はなく、インタラクションレベルでのイノベーションは依然として不十分である。
ドーナツ
最近、暗号資産業界はエージェントブラウザの分野でも進展を見せています。スタートアッププロジェクト「Donut」は、Sequoia China(Hongshan)、HackVC、Bitkraft Venturesが主導するプレシードラウンドで700万ドルの資金調達を実施しました。このプロジェクトはまだ構想段階の初期段階にあり、「発見、意思決定、そして暗号資産ネイティブな実行」という統合機能を実現することを目指しています。
この方向性の核心は、暗号化ネイティブの自動実行パスを組み合わせることです。a16zの予測通り、将来的にはエージェントが検索エンジンに取って代わり、主要なトラフィックの入り口となることが予想されます。起業家はもはやGoogleのランキングアルゴリズムを巡る競争ではなく、エージェント実行によってもたらされるアクセスとコンバージョントラフィックを巡る競争に加わることになります。業界ではこのトレンドを「AEO」(Answer/Agent Engine Optimization)、あるいはさらに「ATF」(Agentic Task Fulfillment)と呼んでいます。つまり、検索ランキングの最適化ではなく、注文、チケット予約、ユーザーへのメッセージ作成といったタスクを遂行できるインテリジェントモデルを直接提供するということです。
起業家向け
まず第一に、ブラウザ自体がインターネット世界において依然として最大の「エントリーポイント」であり、再構築されていないことを認めなければなりません。世界中に約21億人のデスクトップユーザーと43億人以上のモバイルユーザーがいます。ブラウザは、データ入力、インタラクティブな行動、そしてパーソナライズされた指紋の保存のための共通の媒体です。この形態が存続しているのは、惰性によるものではなく、ブラウザが本質的に双方向の特性を持っているためです。つまり、データの「読み取りエントリ」であると同時に、行動の「書き込み出口」でもあるのです。
したがって、起業家にとって真の破壊的ポテンシャルは「ページ出力」レベルの最適化ではありません。たとえGoogleのようなAIオーバービュー機能を新規タブに実装できたとしても、それは本質的にブラウザプラグイン層の反復であり、根本的なパラダイムシフトにはまだ至っていません。真のブレークスルーは「入力側」、つまりAIエージェントが起業家の製品を能動的に呼び出し、特定のタスクを完了させる方法にあります。これが、将来の製品がエージェントエコシステムに統合され、トラフィックと価値分配を獲得できるかどうかの鍵となるでしょう。
検索時代では「クリック」と呼ばれ、代理店時代では「コール」と呼ばれます。
起業家であれば、製品をAPIコンポーネントとして再考してみるのも良いでしょう。そうすれば、インテリジェントエージェントはそれを「読む」だけでなく、「呼び出す」ことも可能になります。そのためには、製品設計の初期段階で以下の3つの側面を考慮する必要があります。
1. インターフェース構造の標準化: あなたの製品は「呼び出し可能」ですか?
製品がインテリジェントエージェントによって呼び出される能力を持つかどうかは、その情報構造が標準化され、明確なスキーマに抽象化されているかどうかにかかっています。例えば、ユーザー登録、注文ボタン、コメント投稿といった主要な操作を、セマンティックDOM構造やJSONマッピングで記述できるかどうか、エージェントがユーザーの行動プロセスを安定的に再現できるよう、システムがステートマシンを提供しているかどうか、ページ上でのユーザーのインタラクションがスクリプトによる復元をサポートしているかどうか、安定したアクセスが可能なWebHookやAPIエンドポイントがあるかどうかなどが挙げられます。
これが、Browser Useの資金調達成功の本質的な理由です。ブラウザをフラットレンダリングされたHTMLから、LLMから呼び出し可能なセマンティックツリーへと変換します。起業家にとって、Web製品に同様の設計コンセプトを導入することは、AIエージェント時代に向けた構造的な適応を図ることを意味します。
2. アイデンティティとアクセス: エージェントが「信頼の壁を越える」ことを支援できますか?
AIエージェントがトランザクションを完了し、支払いや資産を呼び出すには、何らかの信頼できる中間層が必要です。あなたはその役割を担えますか?ブラウザは、ローカルストレージの読み取り、ウォレットの呼び出し、検証コードの識別、二要素認証へのアクセスを自然に実行できるため、大規模なクラウドモデルよりも実行に適しています。これは特にWeb3のシナリオに当てはまります。オンチェーン資産を呼び出すためのインターフェース標準が統一されておらず、エージェントは「ID」や「署名機能」なしでは先に進めません。
したがって、暗号通貨起業家にとって、想像力豊かな空白領域が存在します。それは「ブロックチェーン世界におけるMCP(マルチ機能プラットフォーム)」です。これは、汎用的な命令レイヤー(エージェントがDappを呼び出すためのもの)、標準化されたコントラクトインターフェースセット、あるいはローカルで実行される軽量ウォレットとIDミドルプラットフォームなど、様々な形態が考えられます。
3. トラフィックメカニズムの再理解:未来はSEOではなくAEO/ATF
かつてはGoogleのアルゴリズムの支持を得る必要がありましたが、今ではAIエージェントによってタスクチェーンに組み込まれる必要があります。つまり、製品には明確なタスク粒度が必要です。「ページ」ではなく、「呼び出し可能な機能ユニット」の列です。つまり、エージェント最適化(AEO)やタスクスケジューリング適応(ATF)を実施する必要があるということです。例えば、登録プロセスを構造化されたステップに簡素化できるか、インターフェースから価格を引き出せるか、在庫をリアルタイムで確認できるかなどです。
異なるLLMフレームワークにおける呼び出し構文の適応も必要です。OpenAIとClaudeは関数呼び出しとツールの使用に関して異なる設定をしています。Chromeは旧世界へのターミナルであり、新世界への入り口ではありません。将来性のある真の起業プロジェクトは、新しいブラウザを作ることではなく、既存のブラウザをエージェントとして機能させ、新世代の「命令フロー」への橋渡しをすることです。
構築する必要があるのは、エージェントがワールドを呼び出すための「インターフェース構文」です。
あなたが目指しているのは、インテリジェントなエンティティの信頼チェーンのリンクになることです。
構築する必要があるのは、次の検索モードの「API Castle」です。
Web2 ではユーザーの注意を引くために UI に依存していましたが、Web3 + AI エージェントの時代では、エージェントの実行意図を把握するために呼び出しチェーンに依存します。
免責事項:
本コンテンツは、いかなるオファー、勧誘、または推奨を構成するものではありません。投資に関する決定を行う前に、必ず独立した専門家の助言を求めてください。Gateおよび/またはGate Venturesは、制限地域において本サービスの全部または一部を制限または禁止する場合がありますのでご了承ください。詳しくは、該当する利用規約をご覧ください。
ゲートベンチャーズについて
Gate VenturesはGateのベンチャーキャピタル部門であり、Web 3.0時代の世界を変革する分散型インフラ、エコシステム、アプリケーションへの投資に注力しています。Gate Venturesは、世界的な業界リーダーと連携し、革新的な思考と能力を持つチームやスタートアップを支援し、社会と金融のインタラクションモデルを再定義します。
公式サイト:https://ventures.gate.io/
ツイッター: https://x.com/gate_ventures
ミディアム: https://medium.com/gate_ventures





