




原作者:ユシン
この記事はコミュニケーションと学習のみを目的としており、投資アドバイスを構成するものではありません。

ChatGPT と GPT-4 の人気は、人工知能の威力を示しています。人工知能の背後では、アルゴリズムに加えて、より重要なのは大量のデータです。私たちはデータを中心に大規模で複雑なシステムを構築してきました。その価値は主にビジネス インテリジェンス (ビジネス インテリジェンス、BI) と人工知能 (人工知能、AI) から得られます。インターネット時代のデータ量の急速な増加により、データ インフラストラクチャへの取り組みとベスト プラクティスも急速に進化しています。過去 2 年間で、データ インフラストラクチャ テクノロジ スタックのコア システムは非常に安定しており、サポートするツールやアプリケーションも急速に成長しています。
Web2 データ インフラストラクチャ アーキテクチャ
クラウド データ ウェアハウス (Snowflake など) は、主に SQL ユーザーとビジネス インテリジェンスのユーザー シナリオに焦点を当てて急速に成長しています。他のテクノロジーの導入も加速しており、データ レイク (Databricks など) の顧客は前例のない速度で増加しており、データ テクノロジー スタックの異質性が共存することになります。
データの取得や変換など、他のコア データ システムも同様に耐久性があることが証明されています。これは、現代のデータ インテリジェンスの世界において特に顕著です。 Fivetran と dbt (または同様のテクノロジー) の組み合わせは、ほとんどどこでも見られます。しかし、これはビジネス システムにもある程度当てはまります。 Databricks/Spark、Confluent/Kafka、Astronomer/Airflow の組み合わせもデファクトスタンダードになり始めています。
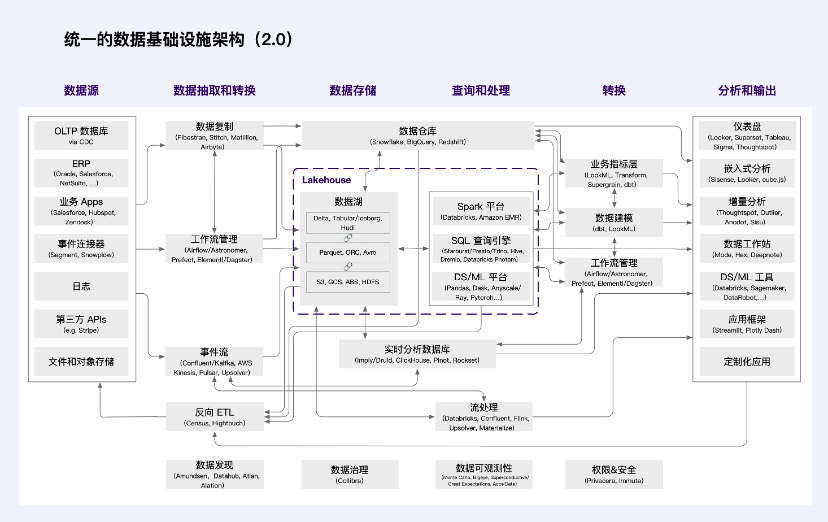
ソース: a16z
で、
情報元関連するビジネスおよびビジネスデータを端末上で生成します。
データの抽出と変換ビジネス システムからのデータの抽出 (E)、ストレージへの送信、データ ソースと宛先の間の形式の調整 (L)、および必要に応じて分析されたデータのビジネス システムへの返送を担当します。
データストレージクエリや処理が可能な形式でデータを保存する場合は、低コスト、高い拡張性、分析ワークロードを実現するために最適化する必要があります。
クエリと処理高レベルのプログラミング言語 (通常は SQL、Python、または Java/Scala) をローエンドのデータ処理タスクに変換します。分散コンピューティングを使用して、履歴分析 (過去に発生したイベントの説明) や予測分析 (将来予想されるイベントの説明) を含む、保存されたデータに基づいてクエリとデータ モデルを実行します。
変換するデータを分析に使用できる構造に変換し、プロセスとリソースを管理します。
分析と出力アナリストとデータ サイエンティストに、洞察を追跡して共同作業したり、内部および外部のユーザーにデータ分析の結果を表示したり、ユーザー指向のアプリケーションにデータ モデルを埋め込んだりできるインターフェイスを提供します。
データエコロジーの急速な発展に伴い、「データプラットフォーム」という概念が登場しました。業界の観点から見ると、プラットフォームの決定的な特徴は、影響力のあるプラットフォーム プロバイダーと多数のサードパーティ開発者の技術的および経済的相互依存関係です。プラットフォームの観点から見ると、データ テクノロジー スタックは「フロントエンド」と「バックエンド」に分けられます。
「バックエンド」には、データの抽出、保存、処理、変換が広く含まれます。、少数のクラウド サービス プロバイダーを中心に統合が始まりました。その結果、顧客データは標準セットのシステムに収集され、ベンダーは他の開発者がこのデータに簡単にアクセスできるようにするために多額の投資を行っています。これは Databricks などのシステムの基本的な設計原則でもあり、SQL 標準などのシステムや Snowflake などのカスタム コンピューティング API を通じて実装されます。
「フロントエンド」エンジニアは、この単一の統合ポイントを活用して、さまざまな新しいアプリケーションを構築します。彼らは、データ ウェアハウス/レイク内のクレンジングおよび統合されたデータに依存しており、データがどのように生成されたかという根本的な詳細を気にする必要はありません。 1 人の顧客が、コア データ システム上に多数のアプリケーションを構築および購入できます。財務や製品分析などの従来のエンタープライズ システムが、ウェアハウス ネイティブ アーキテクチャを使用して再構築されている例さえ見られ始めています。
データ テクノロジー スタックが徐々に成熟するにつれて、データ プラットフォーム上のデータ アプリケーションも急増しています。標準化の結果、新しいデータ プラットフォームを採用することがこれまで以上に重要になり、それに応じてプラットフォームを維持することが非常に重要になりました。大規模化すると、プラットフォームは非常に価値のあるものになる可能性があります。現在、コア データ システム ベンダー間では、現在のビジネスだけでなく、長期的なプラットフォームの地位をめぐって激しい競争が行われています。データ取得および変換モジュールが新興データ プラットフォームの中核部分であると考えると、データ取得および変換企業の驚異的な評価額が理解しやすくなります。
しかし、これらの技術スタックは大企業主導のデータ活用アプローチのもとで形成されたものです。データに対する社会の理解が深まるにつれ、データは土地、労働力、資本、技術と同様、市場によって配分される生産要素であると人々は考えるようになりました。データは5大生産要素の一つであり、その背後に反映されるのがデータの資産価値です。
データ要素市場の構成を実現するには、現在の技術スタックではニーズを満たすには程遠いです。ブロックチェーン技術と密接に統合されている Web3 分野では、新しいデータ インフラストラクチャが開発され、進化しています。これらのインフラストラクチャは最新のデータ インフラストラクチャ アーキテクチャに組み込まれ、データ所有権の定義、流通取引、収入分配、要素ガバナンスを実現します。これら 4 つの領域は政府の規制の観点から重要であるため、特別な注意が必要です。
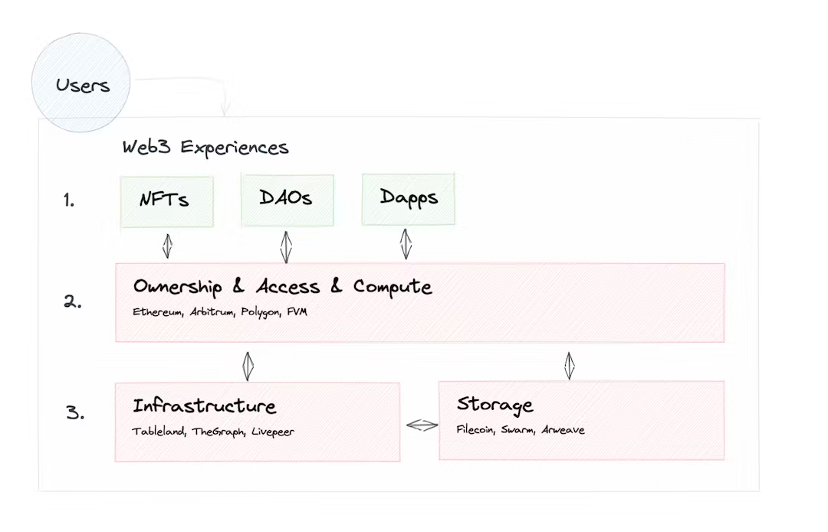
Web3 ハイブリッド データ インフラストラクチャ アーキテクチャ
a16z 統合データ インフラストラクチャ アーキテクチャ (2.0) に触発され、Web3 インフラストラクチャ アーキテクチャの理解を統合して、次の Web3 ハイブリッド データ インフラストラクチャ アーキテクチャを提案します。
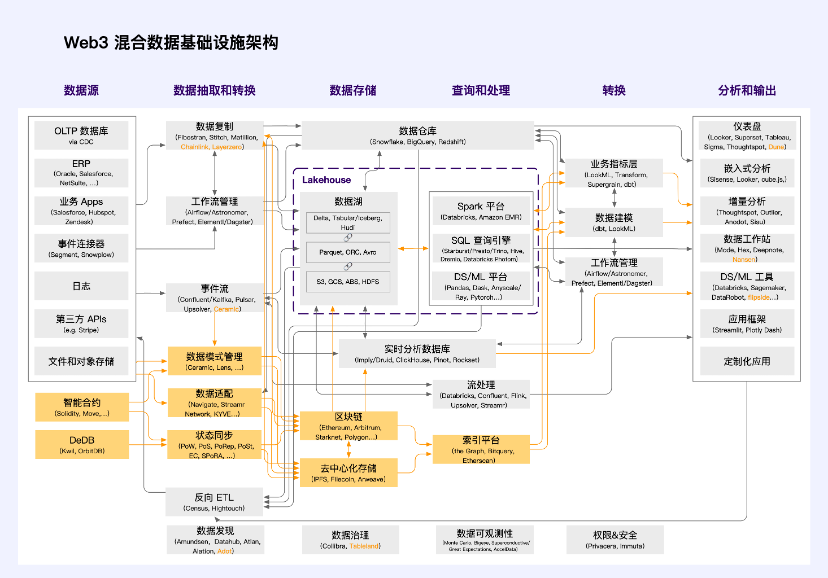
Orange は Web3 独自のテクノロジー スタック ユニットです。分散テクノロジーはまだ開発の初期段階にあるため、Web3 分野のほとんどのアプリケーションは依然としてこのハイブリッド データ インフラストラクチャ アーキテクチャを使用しています。アプリケーションの大部分は、真の「上部構造」ではありません。上部構造には、止められない、自由、価値がある、拡張可能、許可不要、ポジティブな外部性、信頼できる中立性という特徴があります。デジタル世界における公共財として存在し、「メタバース」世界の公共インフラである。これをサポートするには、完全に分散化された基盤となるアーキテクチャが必要です。
従来のデータ インフラストラクチャ アーキテクチャは、企業のビジネス開発に基づいて進化しました。 a16z では、2 つのシステム (分析システムとビジネス システム) と 3 つのシナリオ (最新のビジネス インテリジェンス、マルチモデル データ処理、人工知能と機械学習) にまとめられています。これは企業の観点からの要約です。データは企業の発展に役立ちます。
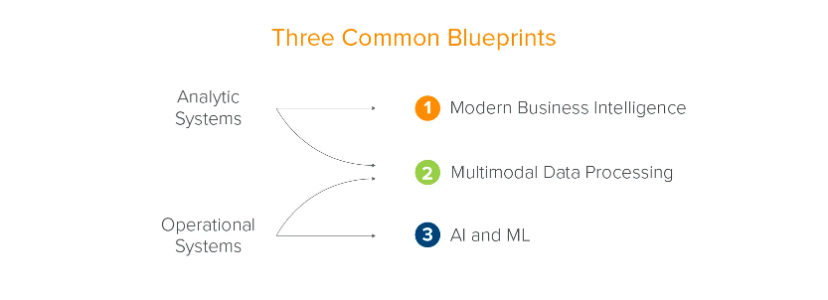
ソース: a16z
ただし、データ要素によってもたらされる生産性の向上から恩恵を受けるのは企業だけではなく、社会や個人も同様です。データの利用を規制レベルから標準化し、データの流通を促進しようと、世界各国が次々と政策や規制を導入している。これには、日本で一般的に見られる各種データバンク、最近中国で登場したデータ交換機、BDEX(米国)、Streamr(スイス)、DAWEX(フランス)などの欧米で広く利用されている取引プラットフォームが含まれます。 、カルーソなど。
データが所有権、フロー取引、収入分配、ガバナンスを定義し始めると、そのシステムとシナリオは企業自身の意思決定と事業開発を強化するだけではありません。これらのシステムとシナリオは、ブロックチェーン テクノロジーの助けを必要とするか、ポリシーの監督に大きく依存します。
Web3 はデータ要素市場の自然土壌であり、不正行為の可能性を技術的に排除し、規制圧力を大幅に軽減し、データを実際の生産要素として存在させ、市場指向の方法で構成できるようにします。
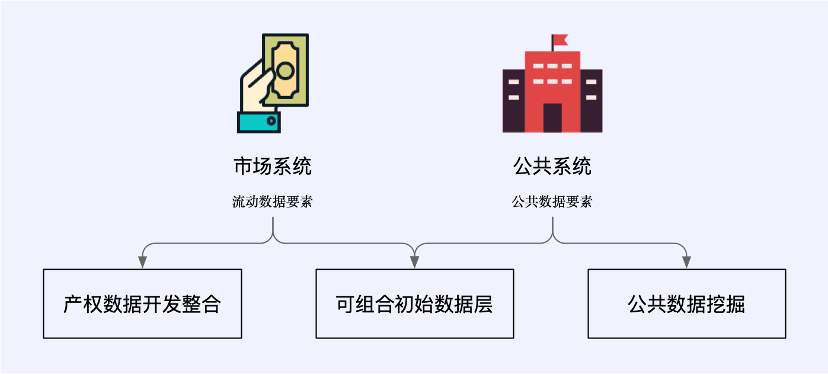
Web3 の文脈では、データ活用の新しいパラダイムには、流動的なデータ要素を運ぶ市場システムと、公開データ要素を管理する公共システムが含まれます。これらは、財産権データ開発の統合、構成可能な初期データ層、およびパブリック データ マイニングという 3 つの新しいデータ ビジネス シナリオをカバーしています。
これらのシナリオの中には、従来のデータ インフラストラクチャと密接に統合され、Web3 ハイブリッド データ インフラストラクチャ アーキテクチャに属するものもありますが、一部のシナリオは従来のアーキテクチャから分離され、Web3 固有の新しいテクノロジによって完全にサポートされます。
Web3 とデータ エコノミー
データ経済市場は、製品データの開発と統合、およびコンポーザビリティを備えた初期データ層市場を含む、データ要素を構成するための鍵です。効率的でコンプライアンスに準拠したデータ エコノミー市場では、次の点が非常に重要です。
データの所有権データは権利と利益を保護し、コンプライアンスを遵守して使用するための鍵であり、構造的に割り当てられ、廃棄される必要があると同時に、データの使用は認可メカニズムを確認する必要があります。各参加者は関連する権利と利益を持っている必要があります。
流通取引オンサイトとオフサイトの統合、コンプライアンスと効率が必要です。確認可能なデータソース、定義可能な使用範囲、追跡可能な流通プロセス、および防止可能なセキュリティリスクの 4 つの原則に基づいている必要があります。
所得分配制度効率的かつ公平である必要があります。 「誰が投資し、誰が貢献し、誰が利益を受けるか」の原則に従って、政府はデータ要素からの収入の分配において指導および規制の役割を果たすこともできます。
ファクターガバナンスは安全で、制御可能で、柔軟かつ包括的です。そのためには、政府のデータガバナンスメカニズムを革新し、データ要素市場信用システムを確立し、データソース、データ財産権、データ品質、データ使用などに焦点を当てて、企業がデータ要素市場の構築に積極的に参加するよう奨励する必要があります。データベンダーとサードパーティの専門サービス組織、データ流通取引明細書とコミットメントシステムを促進する必要があります。
上記の原則は、規制当局がデータエコノミーを検討するための基本原則です。財産権データの開発と統合、構成可能な初期データ層、パブリック データ マイニングの 3 つのシナリオでは、これらの原則に基づいて考えることができます。それをサポートするにはどのようなインフラストラクチャが必要ですか?これらのインフラストラクチャはどの段階でどのような価値を獲得できるのでしょうか?
シナリオ 1: 財産権データの開発と統合
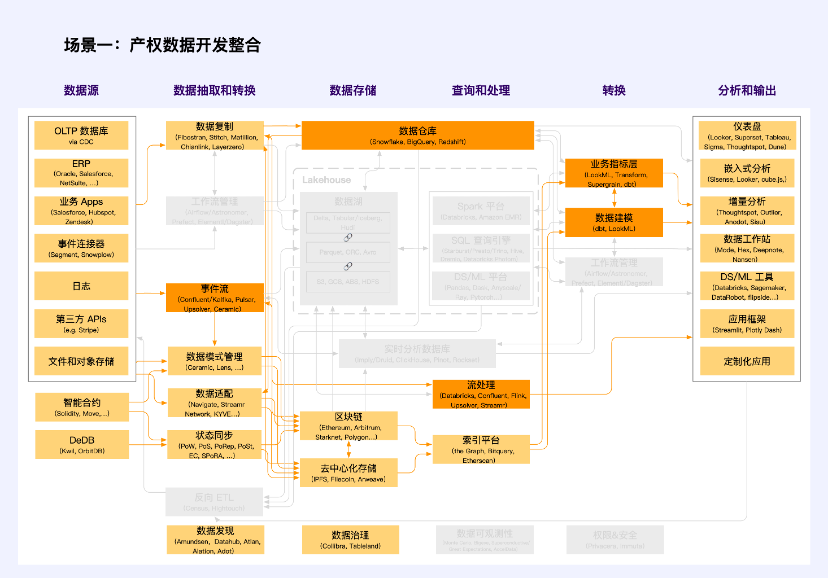
注: オレンジ色は Web2 と Web3 が交差するユニットです
財産権データの開発プロセスでは、公共データ、企業データ、個人データの所有権、使用権、操作権を決定するための機密かつ階層的な権利確認および認可メカニズムを確立する必要があります。データソースと生成の特性に応じて、データの所有権は「データアダプテーション」を通じて定義されます。その中で代表的なプロジェクトとしては、Navigate、Streamr Network、KYVE などが挙げられます。これらのプロジェクトは、技術的手段を通じてデータ品質の標準化、データ収集、インターフェイスの標準化を達成し、何らかの形式でオフチェーンデータの権利を確認し、スマートコントラクトまたは内部ロジックシステムを通じてデータ分類と階層的承認を実行します。
このシナリオで適用されるデータの種類は、非公開データ、つまり企業データと個人データです。データ要素の価値は、「共通の使用と利益の共有」を通じて市場志向の方法で活性化される必要があります。
企業データには、個人情報や公共の利益に関係しない、生産および事業活動においてさまざまな市場主体によって収集および処理されるデータが含まれます。市場主体は、法令に従って収入を保有し、使用し、取得する権利を有し、また、労働やその他の要素の貢献に対して合理的な利益を受け取る権利を有します。
個人データについては、データ処理者が個人の承認の範囲内で法律および規制に従ってデータを収集、保持、ホスト、および使用する必要があります。個人情報を使用する際には、革新的な技術的手段を使用して個人情報の匿名化を促進し、情報セキュリティと個人のプライバシーを確保します。受託者が個人の利益を代表し、市場主体による個人情報データの収集、処理、使用を監督するためのメカニズムを検討します。国家安全保障に関わる特別な個人情報データについては、法令に従って関連部門にその使用を許可することができます。
シナリオ 2: 構成可能な初期データ層
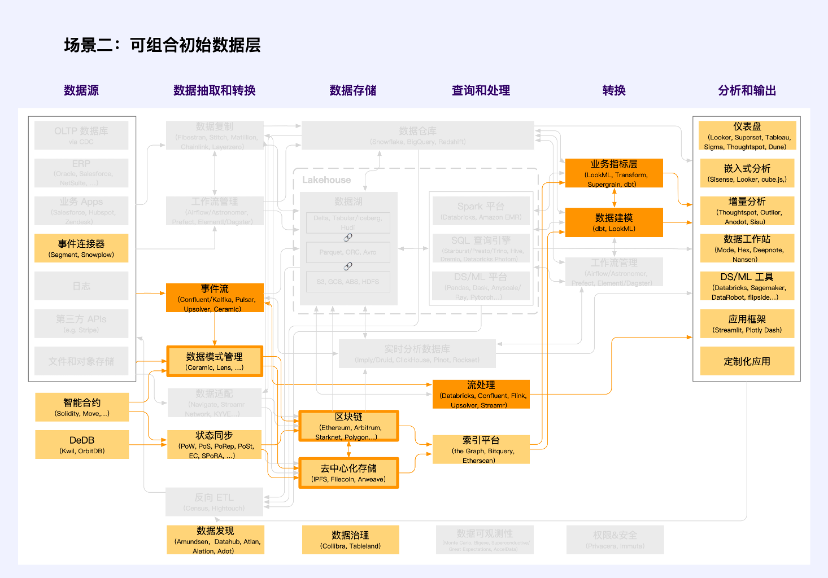
注: オレンジ色は Web2 と Web3 が交差するユニットです
構成可能な初期データ レイヤーは、データ エコノミー市場の重要な部分です。一般的な財産権データとは異なり、この部分のデータの最も明白な特徴は、「データ スキーマ管理」を通じてデータの標準形式を定義する必要があることです。 「データ適応」の品質、収集、インターフェースの標準化とは異なり、ここでは標準データ形式や標準データモデルなどのデータパターンの標準化に重点が置かれています。 Ceramic と Lens はこの分野の先駆者であり、それぞれオフチェーン (分散ストレージ) とオンチェーン データの標準モードを保証し、データを構成可能にします。
これらのデータ スキーマ管理ツールの上に構築されるのは、サイバーコネクト、KNN 3 などの、「データ レイヤー」と呼ばれることが多い、構成可能な初期データ レイヤーです。
コンポーザブルな初期データ層に Web2 テクノロジー スタックが関与することはほとんどありませんが、Ceramic ベースのホット データ読み取りツールはこれを打破し、非常に重要なブレークスルーとなります。同様のデータの多くはブロックチェーンに保存する必要がなく、ブロックチェーンに保存することは困難ですが、ユーザーの投稿、いいね、コメントなど、高頻度で低頻度で分散型ネットワークに保存する必要があります。値密度: データ、セラミックは、このタイプのデータのストレージ パラダイムを提供します。
構成可能な初期データは、新しい時代のイノベーションの重要なシナリオであり、データ覇権とデータ独占の終焉を示す重要な象徴です。データの観点からスタートアップ企業のコールドスタート問題を解決し、成熟したデータセットと新しいデータセットを組み合わせることで、スタートアップ企業がデータ競争上の優位性をより迅速に構築できるようになります。同時に、新興企業はデータ価値の増加とデータの鮮度に重点を置くことができるため、革新的なアイデアに対する継続的な競争力を獲得できます。このようにすれば、大量のデータが大企業にとって外堀になることはありません。
シナリオ 3: パブリック データ マイニング
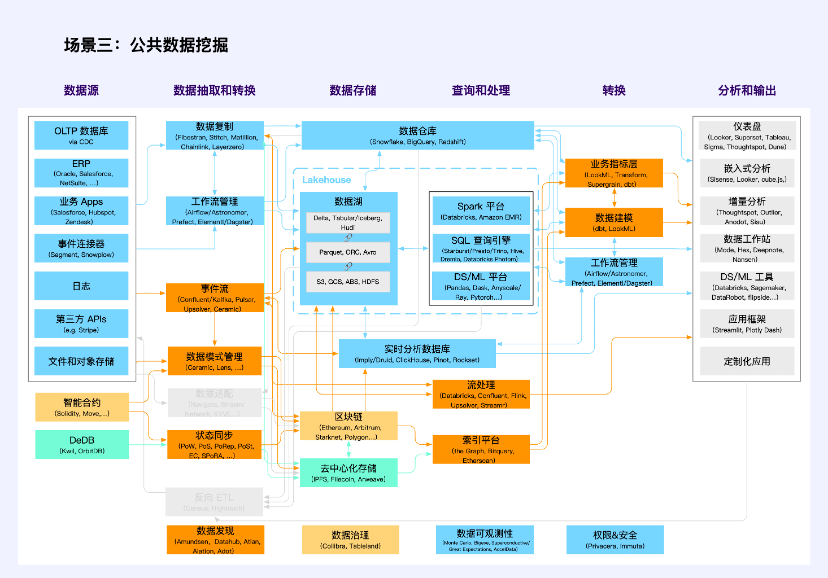
注: オレンジ色は複数カテゴリの交差ユニットです
パブリック データ マイニングは新しいアプリケーション シナリオではありませんが、Web3 テクノロジ スタックではこれまでにないほど注目されています。
従来の公共データには、法律に従って職務を遂行するとき、または公共サービスを提供するときに、政党および政府機関、企業および機関によって生成される公共データが含まれます。規制当局は、「元データが領域外に出ず、データが利用可能かつ不可視であること」を前提に、モデルや検証などの製品・サービスとして社会に提供することを奨励しています。個人のプライバシーを保護し、公共の安全を確保します。従来のテクノロジー スタックを使用しています (青とオレンジ色。オレンジ色は複数の種類のテクノロジー スタックの交差を表します。以下も同様)。
Web3では、ブロックチェーン上のトランザクションデータやアクティビティデータも「可用性・可視性」を特徴とするパブリックデータの一種であるため、データプライバシーやデータセキュリティ、データ使用許可の確認機能が欠如しており、まさに「公開データ」と言えます。 公共財。彼らは、ブロックチェーンとスマートコントラクトをコアとしたテクノロジースタック(黄色と部分的にオレンジ色)を採用しています。
分散ストレージ上のデータは、トランザクション以外のほとんどが Web3 アプリケーション データであり、現在は主にファイル ストレージとオブジェクト ストレージであり、対応する技術スタックはまだ未熟です (緑色と一部のオレンジ色)。このようなパブリック データの作成とマイニングにおける一般的な問題には、ホット ストレージとコールド ストレージ、インデックス作成、状態の同期、権限の管理と計算などが含まれます。
このシナリオでは、Nansen、Dune、NFTScan、0x Scope など、データ インフラストラクチャではなく、より多くのデータ ツールである多くのデータ アプリケーションが登場しています。
ケース: データ交換
データ交換とは、データを商品として取引するためのプラットフォームを指します。取引対象、価格設定メカニズム、品質保証などに基づいて分類および比較できます。 DataStreamX、Dawex、Ocean Protocol は、市場での典型的なデータ交換のいくつかです。
Ocean Protocol (時価総額 2 億) は、企業や個人がデータやデータベースのサービスを交換して収益化できるように設計されたオープンソース プロトコルです。このプロトコルはイーサリアム ブロックチェーンに基づいており、「データトークン」を使用してデータ セットへのアクセスを制御します。データ トークンは、データ セットまたはデータ サービスの所有権または使用権を表す特別な ERC 20 トークンです。ユーザーはデータ トークンを購入または獲得して、必要な情報を取得できます。
Ocean Protocol の技術アーキテクチャには主に次の部分が含まれます。
プロバイダー: データまたはデータ サービスを提供するサプライヤーを指し、Ocean Protocol を通じて独自のデータ トークンを発行および販売して収入を得ることができます。
消費者: データまたはデータ サービスを購入および使用する需要者を指し、Ocean Protocol を通じて必要なデータ トークンを購入または獲得してアクセス権を取得できます。
マーケットプレイス: Ocean Protocol またはサードパーティが提供する、オープンで透明かつ公正なデータ取引市場を指し、世界中のプロバイダーと消費者を結び付け、さまざまな種類と分野のデータ トークンを提供できます。市場は、組織が新たなビジネスチャンスを発見し、収益源を増やし、業務効率を最適化し、より多くの価値を生み出すのに役立ちます。
ネットワーク: Ocean Protocol によって提供される分散ネットワーク層を指します。これは、さまざまなタイプと規模のデータ交換をサポートし、データトランザクションプロセスのセキュリティ、信頼性、透明性を確保できます。ネットワーク層は、データの登録、所有権情報の記録、安全なデータ交換の促進などに使用される一連のスマート コントラクトです。
キュレーター: データ セットのスクリーニング、管理、レビューを担当するエコシステム内の役割を指します。データ セットのソース、コンテンツ、形式、およびライセンス情報をレビューして、データ セットが基準を満たしていることを確認する責任があります。他のユーザーによって信頼され、使用されるようになります。
検証者: データ トランザクションとデータ サービスの検証とレビューを担当するエコシステム内の役割を指し、データ サービスの品質、可用性、精度を保証するために、データ サービス プロバイダーと消費者間のトランザクションをレビューおよび検証します。
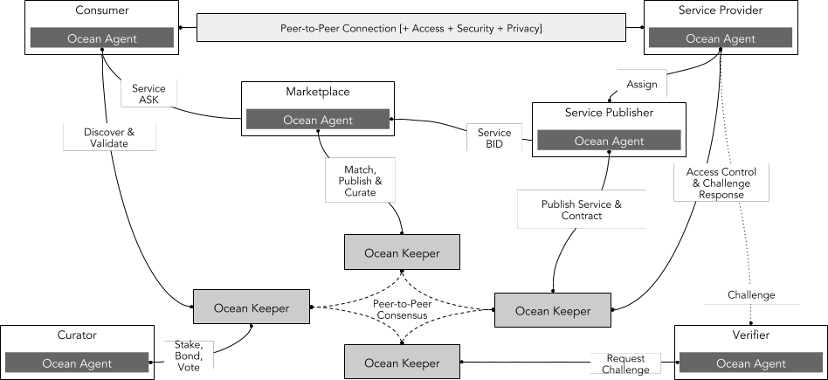
出典: オーシャンプロトコル
データプロバイダーによって作成される「データサービス」には、データ、アルゴリズム、計算、ストレージ、分析、キュレーションが含まれます。これらのコンポーネントは、サービスの実行契約 (サービス レベル契約など)、セキュリティ計算、アクセス制御、およびアクセス許可に関連付けられています。基本的に、これはスマート コントラクトを通じて「一連のクラウド サービス」へのアクセスを制御します。
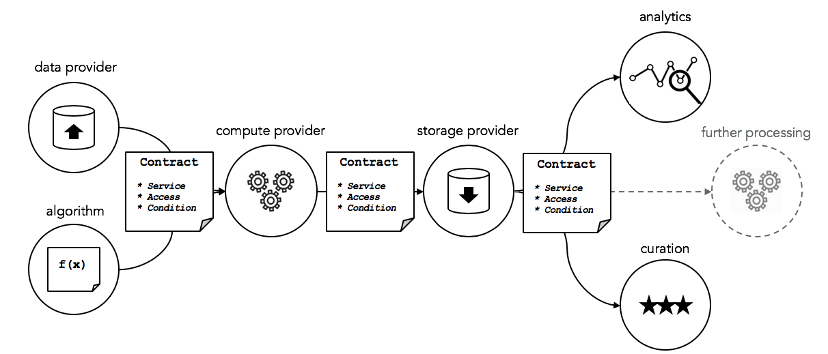
出典: オーシャンプロトコル
利点は、
オープンソースの柔軟で拡張可能なプロトコルは、組織や個人が独自のデータ エコシステムを作成するのに役立ちます。
ブロックチェーン技術に基づく分散型ネットワーク層は、データ取引プロセスにおけるセキュリティ、信頼性、透明性を確保すると同時に、プロバイダーと消費者のプライバシーと権利を保護します。
オープンで透明かつ公正なデータ市場は、世界中のプロバイダーと消費者を結び付け、複数の種類と分野でデータ トークンを提供できます。
Ocean Protocol はハイブリッド アーキテクチャの典型的な例です。そのデータは、従来のクラウド ストレージ サービス、分散ストレージ ネットワーク、データ プロバイダー独自のサーバーなど、さまざまな場所に保存できます。このプロトコルは、データ トークンとデータ NFT を通じてデータの所有権とアクセス権を識別および管理します。さらに、このプロトコルはコンピューティングからデータへの機能も提供し、データ利用者が元のデータを公開することなくデータを分析および処理できるようにします。
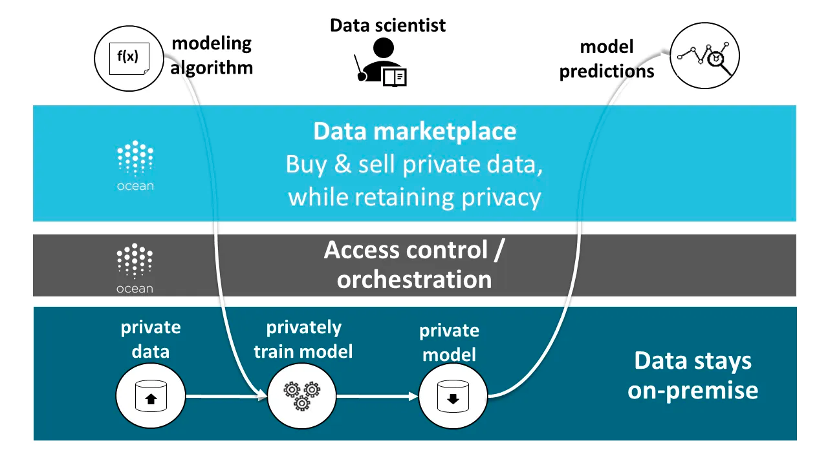
出典: オーシャンプロトコル
Ocean Protocol は現段階で市場で最も完全なデータ取引プラットフォームの 1 つですが、依然として多くの課題に直面しています。
効果的な信頼メカニズムを確立する、データプロバイダーとデマンダー間の信頼を高め、トランザクションのリスクを軽減します。たとえば、データ取引における信頼できない行為、信頼できるインセンティブ、信頼できない罰、信用修復、異議申し立ての処理などを識別するために、ブロックチェーンを通じて証明書を保持および検証するデータ要素市場信用システムを確立します。
合理的な価格設定メカニズムを確立する、データ製品の真の価値を反映し、データプロバイダーが高品質のデータを提供するよう動機付け、より多くの需要者を引き付けるために。
統一標準仕様の制定、異なる形式、タイプ、ソース、用途のデータ間の相互運用性と互換性を促進します。
事例: データモデル市場
Ceramic は、Data Universe の中で、データには相互運用性が必要なため、生産性を大幅に向上できるオープン データ モデル マーケットプレイスを構築したいと述べています。このようなデータ モデル市場は、イーサリアムの ERC 契約標準と同様に、データ モデルに関する緊急コンセンサスによって実現され、開発者はそのデータ モデルのすべてのデータに準拠するアプリケーションを作成するための機能テンプレートとして選択できます。現段階では、そのような市場は取引市場ではありません。
データ モデルに関して、簡単な例として、分散型ソーシャル ネットワークでは、データ モデルを次の 4 つのパラメーターに単純化できます。
PostList: ユーザー投稿のインデックスを保存します
投稿: 単一の投稿を保存します
プロファイル: ユーザー情報を保存します
FollowList: ユーザーのフォローリストを保存します
では、Ceramic 上でデータ モデルを作成、共有、再利用して、アプリケーション間のデータの相互運用性を実現するにはどうすればよいでしょうか?
Ceramic は、Ceramic 用の再利用可能なアプリケーション データ モデルのオープン ソースのコミュニティ構築リポジトリである DataModels Registry を提供します。これは、開発者が既存のデータ モデルをオープンに登録、発見、再利用できる場所であり、共有データ モデルに基づいて構築された顧客運用アプリケーションの基盤となります。現在は Github ストレージをベースとしていますが、将来的には Ceramic 上に分散化される予定です。
レジストリに追加されたすべてのデータ モデルは、@datamodels の npm プラグイン パッケージに自動的に公開されます。開発者は @datamodels/model-name を使用して 1 つ以上のデータ モデルをインストールし、DID DataStore や Self.ID などの IDX クライアントを使用して実行時にデータを保存または取得できるようになります。
さらに、Ceramic は Github に基づいた DataModels フォーラムも構築しており、データ モデル レジストリ内の各モデルにはフォーラム上に独自のディスカッション スレッドがあり、コミュニティはそこを通じてコメントやディスカッションを行うことができます。また、開発者がデータ モデルのアイデアを投稿して、レジストリにデータ モデルを追加する前にコミュニティからの意見を得る場所でもあります。現在、すべてが初期段階にあり、レジストリには多くのデータ モデルがありません。レジストリに含まれるデータ モデルはコミュニティによって評価される必要があり、データのコンポーザビリティを提供するイーサリアムのスマート コントラクト標準と同様に、CIP 標準と呼ばれます。
事例: 分散型データ ウェアハウス
Space and Time は、オンチェーンとオフチェーンのデータを接続して新世代のスマート コントラクトのユースケースをサポートする初の分散型データ ウェアハウスです。 Space and Time (SxT) は、業界で最も成熟したブロックチェーン インデックス サービスです。SxT データ ウェアハウスは、Proof of SQL™ と呼ばれる新しい暗号化も使用して、検証可能な改ざん防止結果を生成し、開発者が簡単に SQL 形式でトラストレスに結合できます。チェーンとオフチェーンのデータを統合し、結果をスマート コントラクトに直接ロードし、完全に改ざん防止されブロックチェーンに基づいた方法で 1 秒未満のクエリとエンタープライズ グレードの分析を強化します。
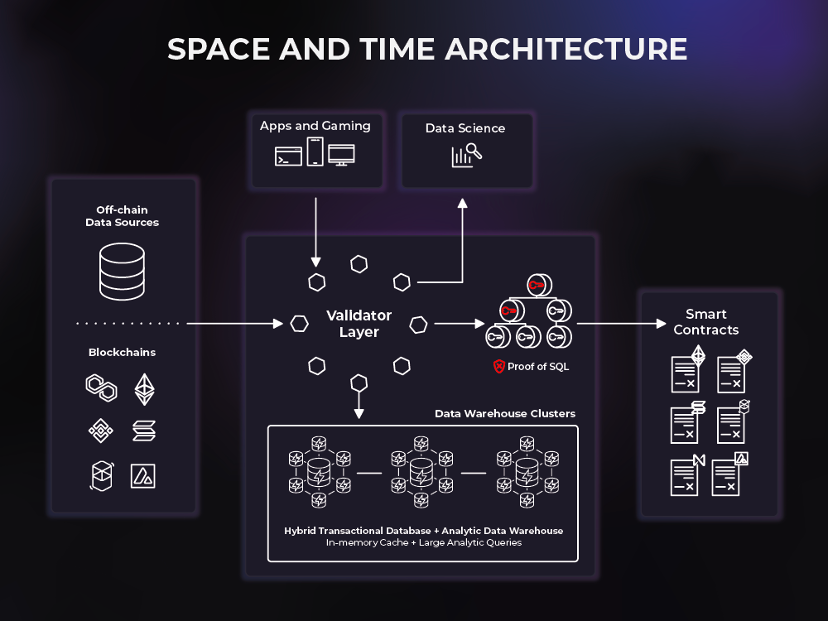
Space and Time は、バリデーター層とデータ ウェアハウスで構成される 2 層のネットワークです。 SxT プラットフォームの成功は、オンチェーンおよびオフチェーン データのシンプルかつ安全なクエリを容易にするバリデーターとデータ ウェアハウスのシームレスな相互作用にかかっています。
データ ウェアハウスは、空間と時間の検証ツールによって制御され、そこにルーティングされるデータベース ネットワークとコンピューティング クラスターで構成されます。 Space and Time では、非常に柔軟な倉庫ソリューションである HTAP (ハイブリッド トランザクション/分析処理) を使用しています。
Validator は、これらのクラスターによって提供されるサービスを監視、指示、検証し、エンド ユーザーとデータ ウェアハウス クラスター間のデータとクエリのフローを調整します。バリデータは、データがシステムに入る手段 (ブロックチェーン インデックスなど)、およびデータがシステムから出る手段 (スマート コントラクトなど) を提供します。
ルーティング - 分散型データ ウェアハウス ネットワークとのトランザクションおよびクエリの対話を可能にします。
ストリーミング – 大量の顧客ストリーミング (イベント駆動型) ワークロードのシンクとして機能します。
コンセンサス - プラットフォームに出入りするデータに高性能ビザンチン フォールト トレランスを提供します。
Query Proof – SQL プルーフをプラットフォームに提供します
テーブルアンカー - テーブルをチェーンに固定することで、プラットフォームに保管の証拠を提供します。
Oracle - スマート コントラクト イベント リスニングやクロスチェーン メッセージング/リレーなどの Web3 インタラクションをサポートします。
セキュリティ – プラットフォームへの未認証および不正アクセスを防止します。
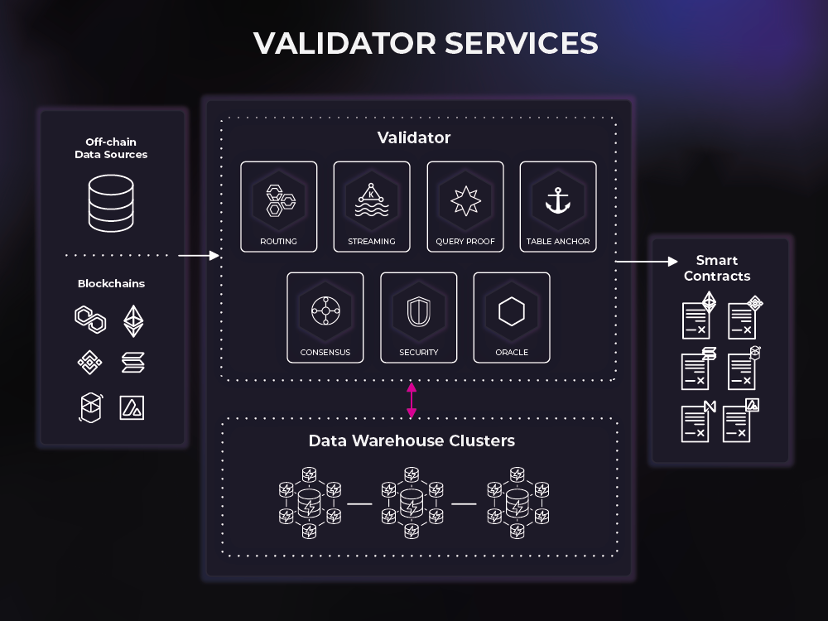
プラットフォームとしての Space and Time は世界初の分散型データ構造であり、強力だが十分なサービスが提供されていない市場であるデータ共有を切り開きます。 Space and Time プラットフォーム内では、企業は自由にデータを共有し、スマート コントラクトを使用して共有データを取引できます。さらに、消費者に生データへのアクセスを与えることなく、SQL 証明を通じてデータセットを集約して収益化することができます。データ利用者は、データ自体を見なくても集計が正確であると信頼できるため、データプロバイダーはデータ利用者である必要がなくなりました。 SQL プルーフとデータ構造スキーマの組み合わせには、誰でもデータ セットの取り込み、変換、提供に貢献できるため、データ操作を民主化できる可能性があるのはこのためです。
Web3 データ ガバナンスと検出
現在、Web3 データ インフラストラクチャ アーキテクチャには、実用的かつ効率的なデータ ガバナンス構造が欠けています。ただし、各参加者の関連する関心に応じたデータ要素を構成するには、実用的で効率的なデータ ガバナンス インフラストラクチャが不可欠です。
データソースについては、インフォームドコンセントと、データ自体を自由に取得、コピー、転送する権利が必要です。
データ処理者にとっては、自律的にデータを制御し、使用し、利益を得る能力が必要です。
データ派生製品の場合は、運営権が必要です。
現在、Web3 データ ガバナンス機能は単一であり、多くの場合、資産とデータ (セラミックを含む) は秘密キーを制御することによってのみ制御でき、階層分類構成機能はほとんどありません。最近では、Tableland、FEVM、Greenfield の革新的なメカニズムにより、トラストレスなデータ ガバナンスをある程度実現できるようになりました。 Collibra などの従来のデータ ガバナンス ツールは、通常、企業内でのみ使用でき、プラットフォーム レベルの信頼しかありませんが、同時に、非分散テクノロジーにより、個人の悪や単一障害点を防ぐことができません。 Tableland などのデータ ガバナンス ツールを通じて、データ流通プロセスに必要なセキュリティ技術、標準、ソリューションを保証できます。
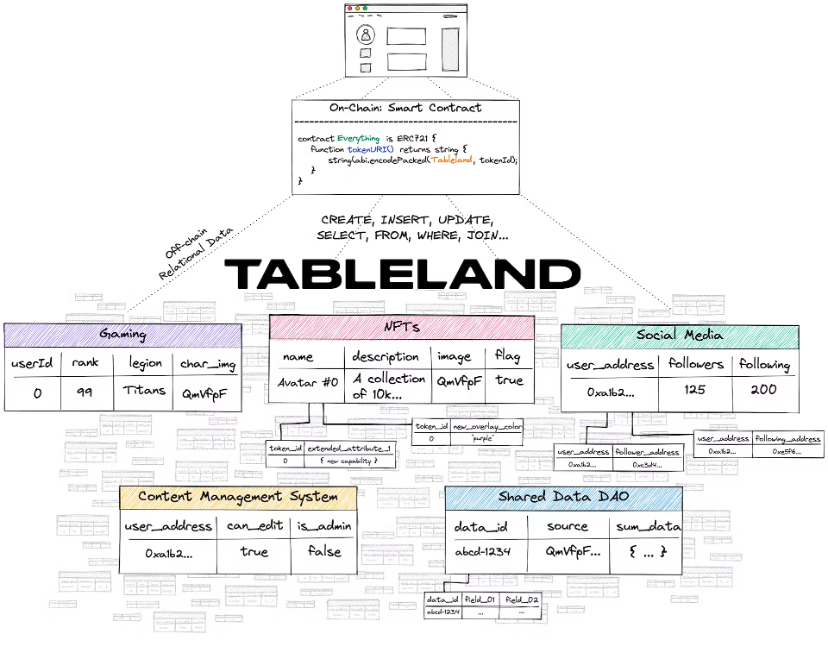
ケース: テーブルランド
Tableland Network は、イーサリアム (EVM) および EVM 互換の L2 から始まる、構造化リレーショナル データ用の分散型 Web3 プロトコルです。 Tableland では、アクセス制御にブロックチェーン層を活用することで、従来の Web2 リレーショナル データベース機能を実装できるようになりました。ただし、Tableland は新しいデータベースではなく、単なる Web3 ネイティブのリレーショナル テーブルです。
Tableland は、dapp がこれらのトレードオフなしにリレーショナル データを Web3 ネイティブ ネットワークに保存するための新しい方法を提供します。
解決
Tableland を使用すると、メタデータの変更 (必要に応じてアクセス制御を使用)、クエリ (使い慣れた SQL を使用)、およびコンポーザブル (Tableland 上の他のテーブルを使用) がすべて完全に分散された方法で可能です。
Tableland は、従来のリレーショナル データベースを、アクセス コントロール ロジック (ACL) を備えたオンチェーン レジストリとオフチェーン (分散型) テーブルの 2 つの主要コンポーネントに分割します。 Tableland のすべてのテーブルは、最初は基本 EVM 互換性レイヤー上の ERC 721 トークンとして作成されます。したがって、オンチェーンのテーブル所有者はテーブルに ACL 権限を設定できますが、オフチェーンのテーブルランド ネットワークはテーブル自体の作成とその後の変更を管理します。オンチェーンとオフチェーンの間のリンクはすべてコントラクト レベルで処理され、単にテーブルランド ネットワークを指します (IPFS ゲートウェイまたはメタデータ用のホスティング サーバーを使用する多くの既存の ERC 721 トークンと同様に、baseURI + tokenURI を使用します)。
 適切なオンチェーン権限を持つユーザーのみが特定のテーブルに書き込むことができます。ただし、テーブル読み取りは必ずしもオンチェーン操作である必要はなく、Tableland ゲートウェイを使用できるため、読み取りクエリは無料で、単純なフロントエンド リクエストから、または他の非 EVM ブロックチェーンから送信することもできます。ここで、Tableland を使用するには、まずテーブルを作成する必要があります (つまり、ERC 721 としてオンチェーンで作成されます)。デプロイメント アドレスは最初はテーブルの所有者に設定されており、この所有者は、テーブルを操作して変更を加えようとする他のユーザーにアクセス許可を設定できます。たとえば、所有者は、誰が値を更新/挿入/削除できるか、どのデータを変更できるかについてのルールを設定し、テーブルの所有権を別の当事者に譲渡するかどうかを決定することもできます。さらに、より複雑なクエリでは、複数のテーブル (所有または未所有) のデータを結合して、完全に動的で構成可能なリレーショナル データ レイヤーを作成できます。
適切なオンチェーン権限を持つユーザーのみが特定のテーブルに書き込むことができます。ただし、テーブル読み取りは必ずしもオンチェーン操作である必要はなく、Tableland ゲートウェイを使用できるため、読み取りクエリは無料で、単純なフロントエンド リクエストから、または他の非 EVM ブロックチェーンから送信することもできます。ここで、Tableland を使用するには、まずテーブルを作成する必要があります (つまり、ERC 721 としてオンチェーンで作成されます)。デプロイメント アドレスは最初はテーブルの所有者に設定されており、この所有者は、テーブルを操作して変更を加えようとする他のユーザーにアクセス許可を設定できます。たとえば、所有者は、誰が値を更新/挿入/削除できるか、どのデータを変更できるかについてのルールを設定し、テーブルの所有権を別の当事者に譲渡するかどうかを決定することもできます。さらに、より複雑なクエリでは、複数のテーブル (所有または未所有) のデータを結合して、完全に動的で構成可能なリレーショナル データ レイヤーを作成できます。
次の図を考えてみましょう。これは、Dapp によって Tableland にデプロイされたテーブルに対する新規ユーザーの操作をまとめたものです。
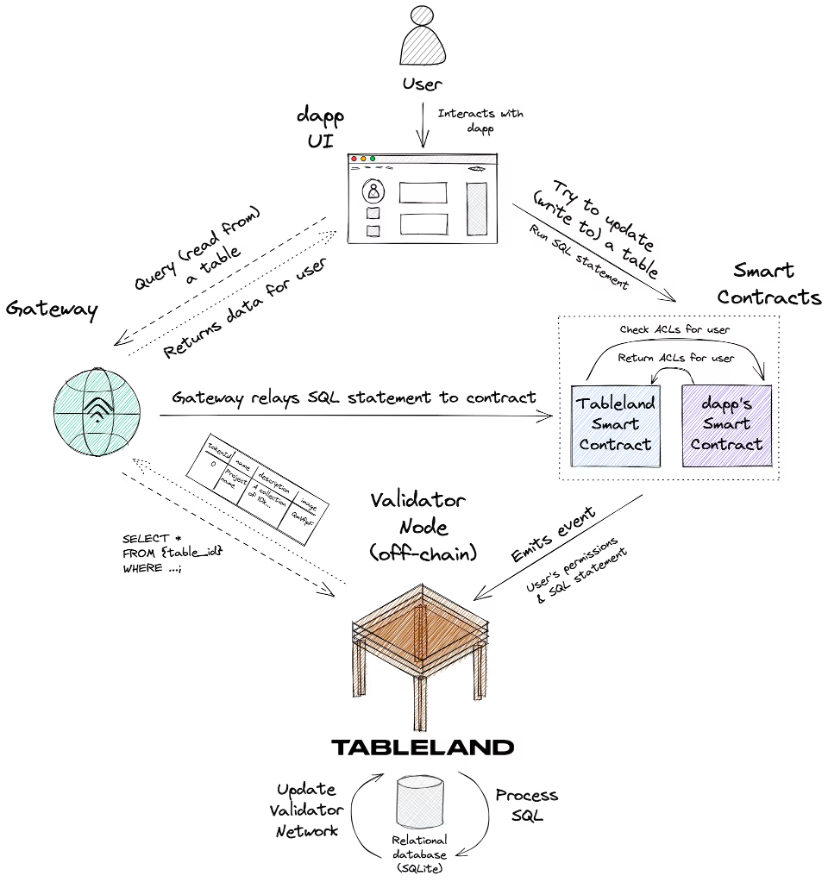
全体的な情報の流れは次のとおりです。
1. 新しいユーザーが dapp の UI を操作し、Tableland テーブルに保存されている一部の情報を更新しようとします。
2. dapp は、Tableland 登録スマート コントラクトを呼び出して、この SQL ステートメントを実行します。このコントラクトは、この新しいユーザーの権限を定義するカスタム ACL を含む dapp のスマート コントラクトをチェックします。注意すべき点がいくつかあります。
dapp の個別のスマート コントラクト内のカスタム ACL は完全にオプションですが、高度な使用例です。開発者はカスタム ACL を実装する必要はなく、Tableland レジストリ スマート コントラクトのデフォルト ポリシーを使用できます (所有者のみが完全なアクセス許可を持っています)。
Tableland スマート コントラクトを直接呼び出す代わりに、ゲートウェイを使用してクエリを作成することもできます。 dapps が Tableland スマート コントラクトを直接呼び出すオプションは常にありますが、クエリはゲートウェイ経由で送信でき、補助金付きの方法でクエリをスマート コントラクト自体に中継します。
3. Tableland スマート コントラクトは、ユーザーの SQL ステートメントと権限を取得し、実行される SQL ベースのアクションを記述する発行されたイベントにこれらを組み込みます。
4. Tableland Validator ノードはこれらのイベントをリッスンし、次のいずれかのアクションを実行します。
ユーザーがテーブルに書き込むための適切な権限を持っている場合、バリデーターはそれに応じて SQL コマンドを実行し (たとえば、テーブルに新しい行を挿入したり、既存の値を更新したり)、確認データをテーブルランド ネットワークにブロードキャストします。
ユーザーが適切な権限を持っていない場合、バリデーターはテーブルに対していかなる操作も実行しません。
リクエストが単純な読み取りクエリの場合は、適切なデータが返されます。Tableland は、誰でも任意のテーブルに対して読み取り専用クエリを実行できる、完全にオープンなリレーショナル データ ネットワークです。
5. dapp は、ゲートウェイを介して Tableland ネットワーク上で発生した更新を反映できるようになります。
(利用シーン)避けるべきこと
個人を特定できるデータ - Tableland はオープン ネットワークであり、誰でも任意のテーブルからデータを読み取ることができます。したがって、個人データを Tableland に保存すべきではありません。
高頻度の 1 秒未満の書き込み - 高頻度取引ボットなど。
すべてのユーザー インタラクションをアプリケーションに保存します。キーストロークやクリックなどのこのデータを Web3 テーブルに保存することは意味がない場合があります。書き込み頻度が高いとコストが高くなります。
非常に大規模なデータ セット - これらは避けるべきであり、IPFS、Filecoin、Arweave などのソリューションを使用して、ファイル ストレージ経由で処理するのが最適です。ただし、これらの場所へのポインターと関連するメタデータは、実際には Tableland テーブルの良い使用例です。
価値の捉え方についての考え方
データ インフラストラクチャ アーキテクチャ全体において、さまざまなユニットがかけがえのない役割を果たします。取得された価値は、主に市場価値/評価および推定収益に反映されます。次の結論が導き出されます:
データ ソースは、アーキテクチャ全体で最大の値を取得するモジュールです
次はデータのレプリケーション、変換、ストリーミング、データ ウェアハウジングです。
分析層のキャッシュフローは良好かもしれないが、評価額には上限がある
簡単に言えば、全体構造図の左側にある企業/プロジェクトの価値捕捉が大きくなる傾向があります。
産業の集中
不完全な統計分析によると、業界の集中度は次のように判断できます。
業界で最も集中している 2 つのモジュールは、データ ストレージとデータ クエリと処理です。
中規模産業の集中はデータの抽出と変換です
業界の集中度が低い 2 つのモジュールは、データ ソース、分析、出力です。
データソース、分析、出力業界の集中度は低く、当初の判断では、データベース分野のOracle、サードパーティサービスのStripe、サービス分野のStripeなど、異なるビジネスシナリオが各ビジネスシナリオの垂直シナリオリーダーの出現につながると考えられています。エンタープライズ サービス: Salesforce、ダッシュボード分析の Tableau、組み込み分析の Sisense など。
中程度の産業集中を伴うデータ抽出および変換モジュールについては、当初、その理由はビジネス属性のテクノロジー指向の性質によるものであると判断されます。モジュール形式のミドルウェアにより、スイッチング コストも比較的低くなります。
データ ストレージ、データ クエリおよび処理モジュールは業界で最も集中しています。単一のビジネス シナリオ、高度な技術的内容、高額なスタートアップ コストとその後の切り替えコストにより、その企業/プロジェクトには強力な先行者がいるというのが予備的な判断です。利点があり、ネットワーク効果があります。
データプロトコルのビジネスモデルと出口パス
設立時期や記載内容から判断すると、
2010年以前に設立された企業/プロジェクトはデータソース企業/プロジェクトが多く、まだモバイルインターネットが登場しておらず、データ量もそれほど多くはなかったが、ダッシュボードを中心としたデータ蓄積や分析出力プロジェクトもいくつかあった。
2010 年から 2014 年にかけて、モバイル インターネットの台頭前夜に、Snowflake や Databricks などのデータ ストレージおよびクエリ プロジェクトが誕生し、データ抽出および変換プロジェクトも登場し始め、一連の成熟したビッグ データ管理テクノロジ ソリューションが徐々に改善されました。この時期はダッシュボード型を中心に分析出力型のプロジェクトが多数発生します。
2015 年から 2020 年にかけて、クエリおよび処理プロジェクトが急増し、多数のデータ抽出および変換プロジェクトも登場し、人々がビッグ データの力をより効果的に活用できるようになりました。
2020 年以降、Clickhouse や Tabular など、より新しいリアルタイム分析データベースやデータ レイク ソリューションが登場しました。
いわゆる「大量導入」にはインフラの整備が前提となる。大規模なアプリケーションの期間中も、新しい機会はまだありますが、これらの機会はほぼ「ミドルウェア」にのみ属しており、基盤となるデータ ウェアハウス、データ ソース、およびその他のソリューションは、そうでない限り、ほぼ勝者総取りの状況になります。技術的な内容. 性的な進歩、そうでなければ成長するのは困難です。
分析成果プロジェクトは、いつの時代でも起業家プロジェクトの機会となります。 2010 年以前に登場した Tableau がデスクトップ ダッシュボード分析ツールの大部分を占め、その後、よりプロフェッショナル向けの DS/ML ツールなどの新しいシナリオが登場しました。より包括的な指向のデータワークステーションやよりSaaS指向の組み込み分析など。
Web3 の現在のデータ プロトコルを次の観点から見てみましょう。
データ ソースとストレージ プロジェクトの状況は不透明ですが、リーダーが現れ始めています。オンチェーン ステート ストレージはイーサリアム (市場価値 2,200 億) が主導し、分散型ストレージはファイルコイン (市場価値 23 億) が主導しています。 Arweave (市場価値 2 億 8,000 万) グリーンフィールドが突然出現する可能性があります。 ——最高値獲得
データ抽出と変換プロジェクトにはまだイノベーションの余地がある データオラクルのChainlink(市場価値38億)は始まりに過ぎない セラミック、イベントストリームやストリーム処理インフラストラクチャなど、さらに多くのプロジェクトが登場するだろうが、それほど多くはない部屋。 - 中程度の価値の獲得
クエリおよび処理プロジェクトについては、Graph (市場価値 12 億) がほとんどのニーズを満たすことができており、プロジェクトの種類と数はまだ爆発的な段階に達していません。 - 中程度の価値の獲得
データ分析プロジェクト、主に Nansen と Dune (評価額 10 億) には、新しい機会を得るために新しいシナリオが必要です。NFTScan と NFTGo は新しいシナリオにある程度似ていますが、コンテンツの更新のみであり、分析ロジック/パラダイム レベルではありません。 。 ——平凡な価値の獲得とかなりのキャッシュフロー。
ただし、Web3 は Web2 のレプリカではなく、Web2 が完全に進化したものでもありません。 Web3 は非常にネイティブなミッションとシナリオを持っているため、これまでとはまったく異なるビジネス シナリオが生まれます (最初の 3 つのシナリオはすべて現在作成可能な抽象化です)。





